Command Palette
Search for a command to run...
OpenAutoNLU:面向自然语言理解的开源AutoML库
OpenAutoNLU:面向自然语言理解的开源AutoML库
Grigory Arshinov Aleksandr Boriskin Sergey Senichev Ayaz Zaripov Daria Galimzianova Daniil Karpov Leonid Sanochkin
摘要
OpenAutoNLU 是一个面向自然语言理解(NLU)任务的开源自动化机器学习库,涵盖文本分类与命名实体识别(NER)两大核心任务。与现有解决方案不同,本库引入了数据感知的训练策略选择机制,无需用户进行任何手动配置。此外,该库还集成了数据质量诊断功能,支持可配置的分布外(OOD)检测,并内嵌大型语言模型(LLM)相关特性,所有功能均通过一个简洁的低代码 API 实现。演示应用可访问:https://openautonlu.dev。
一句话总结
来自 MWS AI、ITMO 大学和 MBZUAI 的研究人员推出了 OpenAutoNLU,这是一个面向自然语言理解(NLU)任务的开源 AutoML 库,可自动选择训练策略,通过低代码 API 集成 OOD 检测和大语言模型(LLM)功能,在无需手动调参的同时增强文本分类和命名实体识别(NER)的数据诊断能力。
主要贡献
- OpenAutoNLU 引入了一种数据感知的训练策略选择器,可根据每类样本数量自动在少样本学习(AncSetFit、SetFit)或完整 Transformer 微调之间切换,无需手动配置,同时适应数据集规模和标签分布。
- 该库内置数据质量诊断功能(包括重新标注、不确定性评分和 V-Information 分析),并提供可配置的 OOD 检测方法(如马氏距离、softmax 概率),针对每种训练策略定制,从而增强生产环境中的模型鲁棒性。
- 通过统一的低代码 API 支持文本分类和 NER,OpenAutoNLU 在意图分类基准上表现出具有竞争力的性能,并在低资源场景下提供可选的 LLM 驱动数据增强功能。
引言
作者利用自动化机器学习简化自然语言理解(NLU)模型开发,涵盖文本分类和命名实体识别——这些任务对意图检测和信息抽取等应用至关重要。以往的 NLP AutoML 工具常需手动配置、缺乏统一接口,且忽略 NLP 特定需求(如基于数据规模选择训练策略或内置数据质量检查)。OpenAutoNLU 通过引入数据感知的训练策略选择器、集成诊断工具、可配置的 OOD 检测和统一低代码 API 解决了这些问题,无需用户调参即可在最小设置下实现有竞争力的性能。
数据集
作者使用四个英文意图分类数据集——Banking77、HWU64、MASSIVE 和 SNIPS——在一致设置下评估 OOD 检测。数据组成与处理方式如下:
-
数据集组成与来源
每个数据集分为分布内(ID)和分布外(OOD)子集。OOD 样本分为三类:- 中等 OOD:来自同一数据集但保留未用于训练的类别(占 20%)。
- 远距离 OOD:来自语义相关但分布不同的数据集(如 Banking77 ↔ HWU64)。
- 极远距离 OOD:1000 条合成的无意义语句,用于测试对无意义输入的鲁棒性。
-
关键子集细节
- 分布内:仅保留样本数 ≥ n_min 的类别(n_min = 少样本上限或 100 用于全数据)。随机选择 80% 符合条件的类别作为 ID;每类中 90% 用于训练,10% 用于测试。少样本运行时,每类训练样本在指定范围内随机采样;低于最小值的类别被丢弃。
- OOD 测试集:总 OOD 大小 = ID 类别大小的第 95 百分位,平均分配至中等、远距离和极远距离 OOD。
- OOD 训练集(可选):若使用,OOD 体积等于 ID 训练集的一半,同样平均分配至各类 OOD。
-
数据在模型中的使用方式
- 对于监督式 OOD 检测,OOD 样本同时用于训练和测试。
- 对于无监督 OOD(如 OpenAutoNLU),OOD 样本仅在测试时出现。
- 作者还测试了训练时将 OOD 作为标注类别引入时的性能。
- 评估指标见表 2,完整细节见附录 D。
-
处理与元数据
- 阈值(n_min = 5 和 n_min = 80)通过多个数据集和任务经验确定,用于识别不同训练方法(AncSetFit、SetFit、全微调)间的最优切换点。
- OOD 类别在测试集中均匀平衡。
- 远距离 OOD 来源选择为语义相关但领域偏移(见表 E.1 中配对)。
方法
作者在 OpenAutoNLU 中采用模块化、数据感知的流水线架构,自动跨不同数据规模训练 NLU 模型,无需手动干预。系统根据每类最小样本数 nmin 动态选择训练策略,确保在少样本、中样本或全微调场景下选择最优方法。该决策基于经验基准,具有确定性,无需用户手动配置算法或超参数网格。
在顶层,框架通过 auto_classes 模块暴露公共流水线类,继承自管理完整生命周期的抽象基类:数据加载、预处理、可选数据质量评估、方法解析、训练、评估和模型导出。核心逻辑位于 methods 模块,封装了四种主要训练策略:Finetuner(适用于 nmin>80)、SetFitMethod(适用于 5<nmin≤80)、AncSetFitMethod(适用于 2≤nmin≤5)和 TokenClassificationFinetuner(用于命名实体识别任务)。每种方法均配有一类 OOD 检测变体——微调对应边际马氏距离,SetFit 对应最大 softmax 概率,AncSetFit 对应基于 logits 的“outOfScope”类别——均可通过单一配置标志访问。
请参考框架图以了解流水线的模块结构和数据流。图示说明了当启用数据质量模块时,如何通过动态调优器生成每样本诊断信号。这些信号输入四个评估器:Retag(标记标签与模型不一致)、Uncertainty(识别低置信度预测)、V-Information(衡量每样本可学习信号)和 Dataset Cartography(将数据划分为易、模糊和难区域)。对于 NER 任务,采用基于 Dawid–Skene 共识估计的标签聚合评估器替代上述评估器,通过蒙特卡洛 dropout 检测词元级标注分歧。
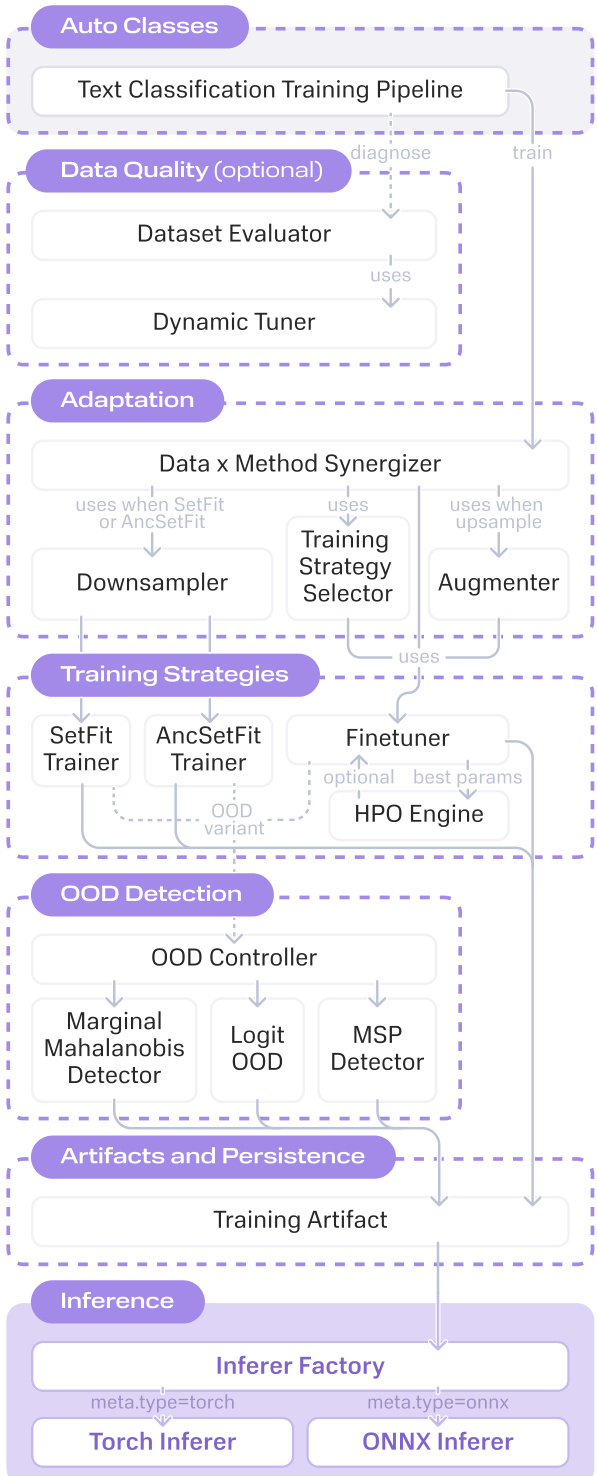
在方法选择前,流水线执行自适应数据再平衡。若低资源类别(样本数 n≤80)超过数据集 30%,则使用 Augmentex 扰动或 LLM 生成的改写对欠表示类别上采样至 n=81。反之,当选中少样本方法时,过表示类别将下采样至该方法的上限(SetFit 为 80,AncSetFit 为 5),以维持训练平衡。此再平衡可能将数据集推入更高数据规模,触发重新评估最优训练策略。
在微调模式下,通过 Optuna 使用树状帕累托估计器采样器对学习率(对数均匀分布于 [10−6,10−3])、批量大小和权重衰减进行超参数优化,默认预算为 10 次试验并启用早停(耐心值 = 5)。相比之下,SetFit 和 AncSetFit 使用固定、经验调优的超参数,在完整下采样数据集上训练,无需搜索。
当启用 OOD 检测时,流水线联合优化分类器和检测器。通过无意义语句生成器生成合成 OOD 样本,检测阈值(马氏距离或 softmax 概率)在验证数据上调整,可通过 threshold_factor 参数调节。此外,LLM 驱动的测试集生成模块在无保留测试集时合成标注评估样本,为低资源场景提供可靠模型质量估计代理。
所有训练模型均序列化为支持 ONNX 导出的推理就绪包。这些包包含 ONNX 图、分词器文件、标签映射和 meta.json 描述符。推理层自动检测可用硬件(CUDA、CoreML、CPU),并执行批处理推理,动态调整批次大小以避免内存溢出。
实验
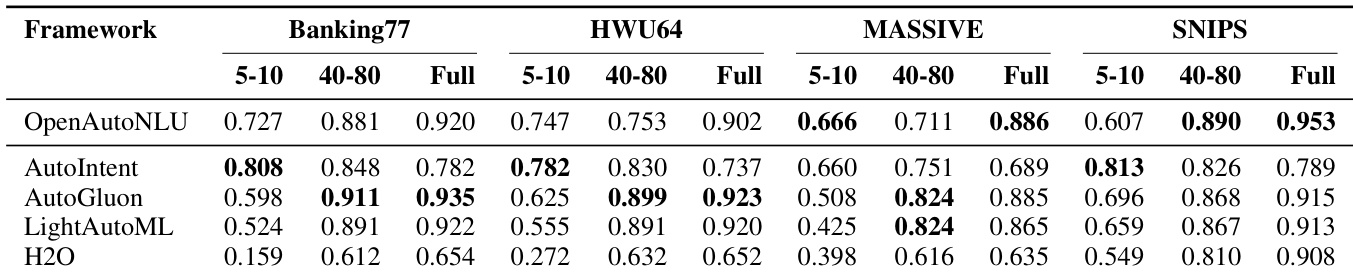
- OpenAutoNLU 在多个意图分类数据集上持续匹配或超越竞争 AutoML 框架,尤其在中至全数据规模下表现优异,同时在现实 OOD 未知条件下保持强大的域内分类性能。
- AutoGluon 在 Banking77 上表现最佳,但计算成本显著更高;其他通用框架(LightAutoML、H2O)表现落后,尤其在低资源场景下。
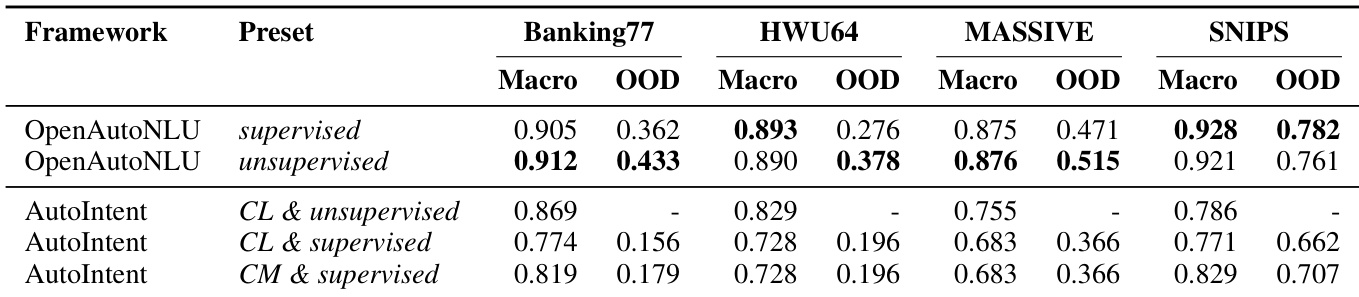
- AutoIntent 虽专为意图分类设计,但在所有数据集上均逊于 OpenAutoNLU,尤其在 MASSIVE 上差距显著;其 OOD 检测需监督训练,且会降低域内性能。
- OpenAutoNLU 的无监督 OOD 检测在无需标注 OOD 数据的情况下表现稳健,常优于监督变体;相比之下,AutoIntent 无法在无监督下生成 OOD 预测,且性能权衡明显。
- LLM 生成的测试集在某些规模下是可靠代理,但非全部,表明合成评估的有效性依赖上下文。
- 所有实验均在标准化硬件上进行,训练时间反映现实部署约束,进一步凸显 OpenAutoNLU 的效率优势。
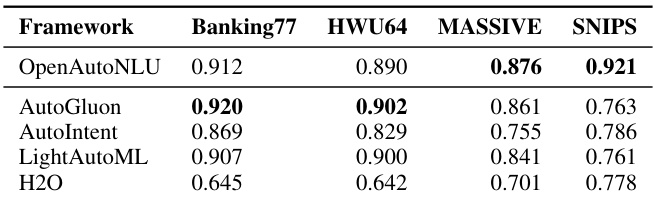
OpenAutoNLU 在四个评估数据集中的三个上取得最佳或并列最佳性能,证明其在现实 OOD 未知条件下具备强大的域内分类准确率。尽管 AutoGluon 在 Banking77 上略胜一筹,但代价是显著更高的计算成本。AutoIntent 尽管专为意图分类设计,但在所有数据集上持续表现不佳,尤其在 MASSIVE 上。
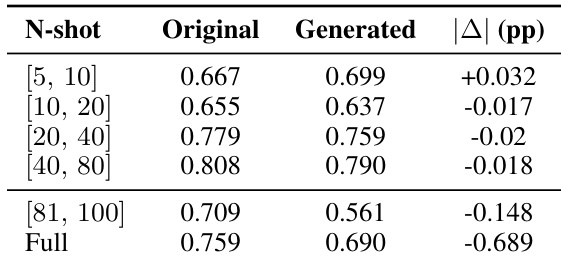
作者在不同数据规模下使用原始和 LLM 生成的测试集评估分类性能,发现生成集在少至中样本设置下接近原始性能,但在全数据条件下显著偏离。结果表明,仅当绝对性能差异保持在 5 个百分点以内时,LLM 生成的测试集可作为可靠代理,这一条件适用于较小训练规模,但不适用于完整数据集。
OpenAutoNLU 在所有数据集的监督和无监督 OOD 检测模式下持续优于 AutoIntent,取得更高的宏观 F1 和 OOD F1 分数,且无需标注 OOD 数据。AutoIntent 在强制处理 OOD 检测时性能显著下降,尤其在监督模式下牺牲域内分类准确率。结果表明,OpenAutoNLU 的无监督 OOD 机制有效且稳健,无需额外监督即可实现强大的联合分类和检测性能。
作者在四个意图分类数据集上评估多个 AutoML 框架在不同数据规模下的表现,发现 OpenAutoNLU 在全数据设置下持续取得最佳或接近最佳性能,同时在低和中样本场景下保持强劲表现。AutoGluon 和 LightAutoML 在大数据规模下具竞争力,但在低资源条件下显著退化,而 AutoIntent 在少样本设置下表现最佳,但随训练数据增加而落后。H2O 在所有数据集和数据规模下持续表现不佳。