Command Palette
Search for a command to run...
OmniLottie:通过参数化 Lottie Tokens 生成矢量动画
OmniLottie:通过参数化 Lottie Tokens 生成矢量动画
Yiying Yang Wei Cheng Sijin Chen Honghao Fu Xianfang Zeng Yujun Cai Gang Yu Xingjun Ma
摘要
OmniLottie 是一个多功能框架,能够根据多模态指令生成高质量的矢量动画。为实现对运动与视觉内容的灵活控制,我们聚焦于 Lottie——一种轻量级的 JSON 格式,用于表示图形形状与动画行为。然而,原始的 Lottie JSON 文件包含大量不变的结构化元数据和格式化标记,给矢量动画生成任务带来了显著挑战。为此,我们设计了一种高效的 Lottie 分词器(tokenizer),可将 JSON 文件转化为由命令与参数组成的结构化序列,用以表示图形、动画函数及控制参数。该分词器使我们能够基于预训练的视觉-语言模型构建 OmniLottie,从而准确理解多模态交错指令,并生成高质量的矢量动画。为进一步推动矢量动画生成领域的研究,我们构建了 MMLottie-2M——一个大规模、由专业设计的矢量动画构成的数据集,每个动画均配有文本和视觉标注。通过大量实验验证,OmniLottie 能够生成生动且语义一致的矢量动画,精准遵循多模态人类指令。
一句话总结
复旦大学、StepFun、香港大学 MMLab 与昆士兰大学的研究人员提出了 OmniLotte——一种多功能自回归模型,可通过新颖的 Lotte 分词器从多模态输入生成高质量矢量动画,克服 JSON 结构挑战并实现精确的运动控制,适用于创意设计任务。
主要贡献
- OmniLotte 是首个端到端框架,通过新颖分词器将 Lottie 复杂的 JSON 结构转换为紧凑可学习的指令序列,直接从多模态指令生成高质量矢量动画。
- 该框架在 MMLotte-2M 数据集上训练,该数据集包含 200 万专业设计的 Lottie 动画,配以文本、图像和视频注释,支持跨文本到动画、图文到动画、视频到动画任务的统一评估。
- 实验表明,OmniLotte 在视觉保真度和语义对齐方面显著优于先前方法,可生成稳健、可编辑且高度贴合多样化多模态用户输入的矢量动画。
引言
作者利用广泛使用的矢量动画格式 Lottie(以 JSON 编码),构建了 OmniLotte——一个从文本、图像或视频输入生成高质量、可编辑动画的框架。先前方法要么因生成栅格输出而缺乏可编辑性,要么因难以处理 Lottie 严格的 JSON 结构而导致成功率低、指令遵循差。OmniLotte 通过引入专用分词器,将 Lottie 冗长的 JSON 转换为紧凑指令序列,从而在 MMLotte-2M(包含 200 万标注矢量动画的新数据集)上实现高效训练。该方法支持端到端生成,同时保留矢量图形的可扩展性和跨平台优势,显著提升视觉保真度和与多模态提示的语义对齐。
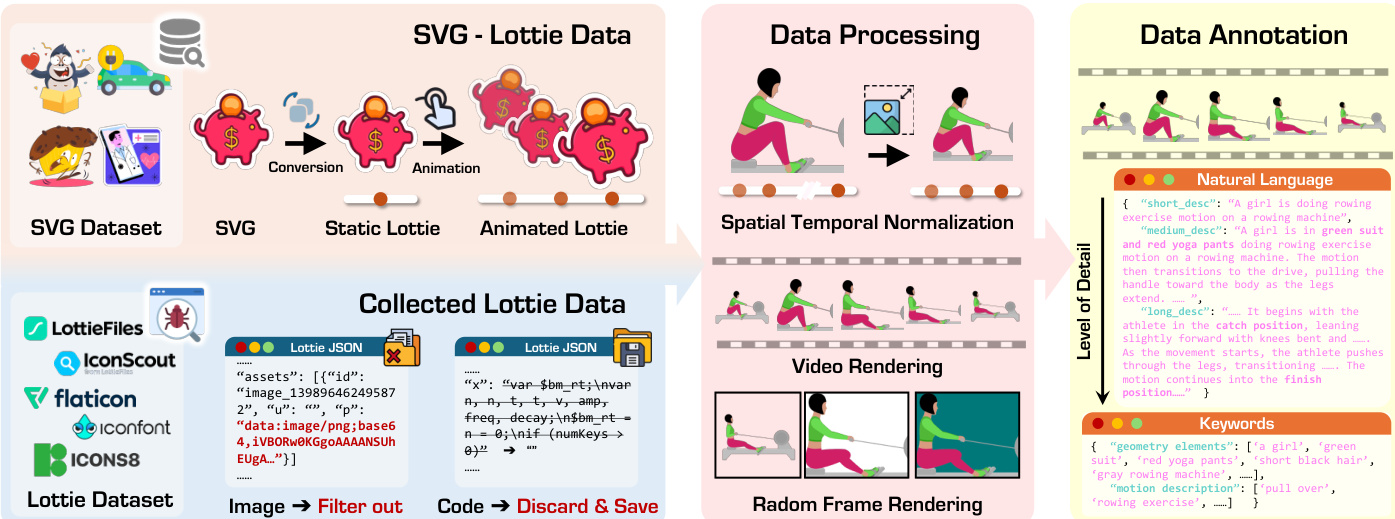
数据集
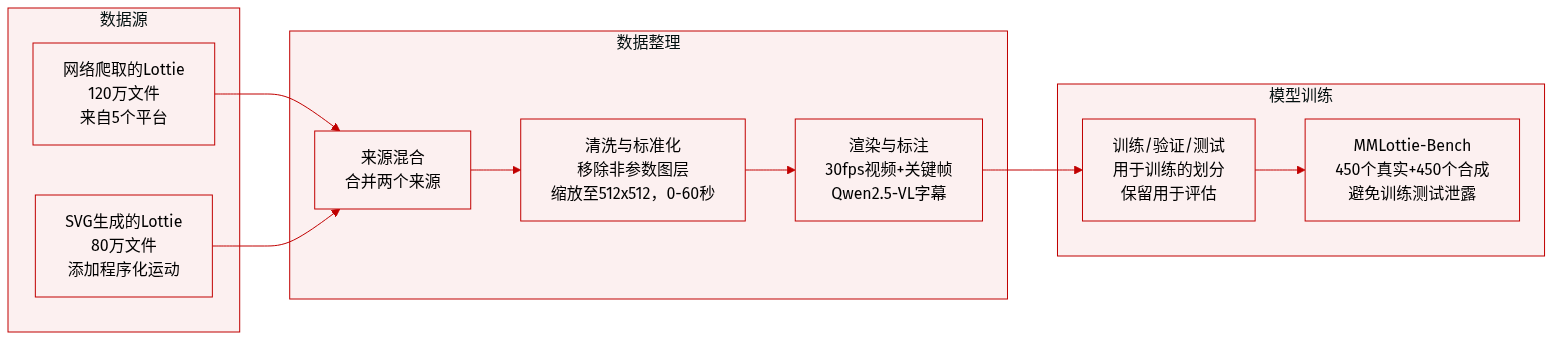
作者使用 MMLottie-2M 数据集训练和评估多模态矢量动画生成模型。数据集结构与处理方式如下:
-
数据集组成与来源
数据集结合两个主要来源:120 万从 LottieFiles、IconScout、Flaticon、Iconfont 和 Icons8 爬取的 Lottie 动画;以及 80 万由 OmniSVG 中 200 万静态 SVG 通过程序化运动(平移、旋转、缩放、透明度等)生成的动画。 -
关键子集详情
- 网络爬取 Lottie:120 万文件,清理移除 base64 图像、音频/摄像头图层及 After Effects 表达式,保留完全可参数化的文件。
- SVG 衍生 Lottie:80 万文件,通过对静态 SVG 应用随机基础运动生成,解耦视觉内容与运动以更好学习对齐。
- MMLottie-Bench(评估):450 个真实样本(每任务 150 个:文本到动画、图文到动画、视频到动画)+ 450 个合成样本(由 GPT-4o、Gemini 3.1-Pro 和 Seedance 1.0 生成),确保公平性并避免训练-测试泄露。
-
训练用途与处理流程
所有 Lottie 文件经历 5 阶段处理管道:- 收集:从平台和 SVG 聚合。
- 清洗:移除不可参数化元素。
- 标准化:空间缩放至 512×512 并居中对齐;时间标准化至 0–60 范围。
- 渲染:转换为 30fps MP4 视频,背景随机淡色;为图像任务提取关键帧。
- 标注:使用 Qwen2.5-VL 生成两级说明——简洁概览(平均 86 词)和详细时间描述(平均 114 词),严格遵循颜色、运动和空间细节指南。
-
额外处理细节
- 运动迁移管道从 100 万原生文件提取变换轨迹,创建标准运动模板,应用于 SVG 衍生动画以丰富运动多样性。
- 图层结构扁平化为可分词函数调用供 OmniLotte 使用,扩展 Qwen2.5-VL 以支持专用 Lottie 分词器。
- 评估使用 Claude-3.5-Sonnet 作为对象和运动对齐评判员,与人工评分验证(Spearman ρ = 0.82 和 0.79)。
- 指标包括分词效率(通过 Qwen2.5-VL 分词器)和推理时间(在 A100 GPU 或 API 延迟上)。
数据集仅供研究使用,所有权归原始内容所有者。
方法
作者利用名为 OmniLottie 的结构化、基于分词的框架,实现从文本、图像和视频输入生成多模态矢量动画。核心创新在于将冗长的 Lottie JSON 格式抽象为紧凑、语义丰富的离散标记序列,可被视觉-语言模型(VLM)高效处理。此方法避免了直接生成原始 JSON 的低效性,后者包含冗余结构元数据,干扰模型学习形状、运动和时序动态等动画相关先验。
流程始于自定义 Lottie 分词器,将 Lottie JSON 重组为包含基础元数据和图层特定属性的层级表示。元数据包括全局动画属性如版本(v)、帧率(fr)、入点(ip)、出点(op)、宽度(w)、高度(h)、名称(nm)和 3D 标志(ddd)。每图层由其类型(ty ∈ {0,1,3,4,5} 对应预合成、实体、空、形状、文本)及其相关属性参数化,包括变换(ks)、效果(ef)、遮罩(masksProperties)和文本内容(t)。如下图所示,此结构分解支持无损树状表示,保留原始格式的完整生成灵活性,同时消除语法冗余。
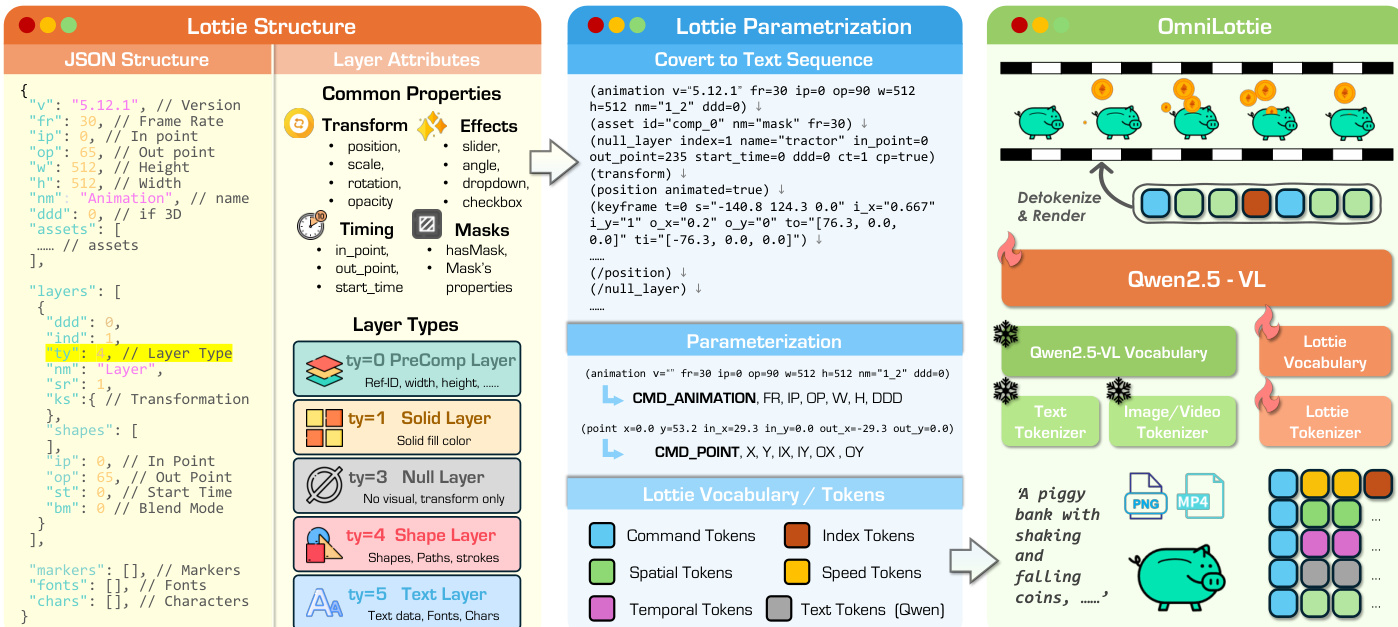
分词器使用基于偏移的量化方案将连续参数映射为离散标记:token(x,t)=⌊x⋅st⌋+ot,其中 x 为参数值,t 为其语义类型,st 为类型特定缩放因子,ot 为词汇偏移。此设计确保每个参数类别——时序、空间、变换、样式——在标记空间中占据不重叠区域,避免冲突同时保留数值关系。字体名称或字符等文本字段由骨干 VLM 的原生分词器(Qwen2.5-VL)单独处理,编码为带计数前缀的标记序列以保留语言语义。
生成的标记序列输入预训练 VLM 骨干 Qwen2.5-VL,该模型已扩展自定义 Lottie 词汇表。模型使用标准交叉熵损失训练,以多模态指令(文本、图像、视频)为条件自回归生成 Lottie 标记:θ∗=argminθ−∑i=1LlogP(xs[i]∣xc;xs<i;θ)。推理时,生成的标记序列通过确定性逆变换还原为有效 Lottie JSON 文件,确保完整重建保真度。
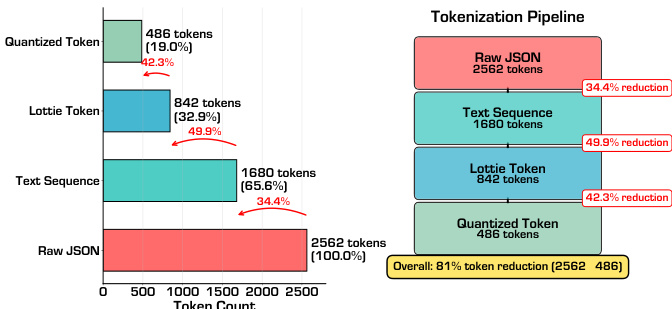
分词管道实现显著压缩:如下图所示,原始 Lottie JSON(平均 2562 个标记)经结构化文本序列(1680 个标记)、命令-参数格式(842 个标记)最终压缩至 486 个标记——减少 81%。此效率使模型可集中学习动画语义而非格式语法。
数据标注时,作者将 Lottie 动画渲染为视频,使用 VLM 生成多级描述:粗略整体说明后接更精细时间细节,使用“开始时”和“然后”等提示。强调几何和运动的关键词以提升文本遵循准确性。对于图文到动画,选择单帧并提示 VLM 关注前景对象运动。对于视频到动画,渲染视频本身作为多模态指令,简化标注。如下图所示,此方法支持三种生成模式:文本到动画、图文到动画、视频到动画,每种均生成匹配输入规范的矢量动画。
模型架构整合 Qwen2.5-VL 骨干与自定义 Lottie 分词器及词汇表,支持无缝处理交错多模态输入。分词设计遵循关注点分离、词汇效率、重建保证和模型兼容性原则,确保离散表示不损害输出的矢量特性。解码时,数值参数通过 p=sttoken−ot 恢复,文本内容由预训练分词器解码,保留语义一致性。最终输出为可渲染的 Lottie JSON 文件,保持分辨率独立性、可编辑性和完整矢量保真度。
实验
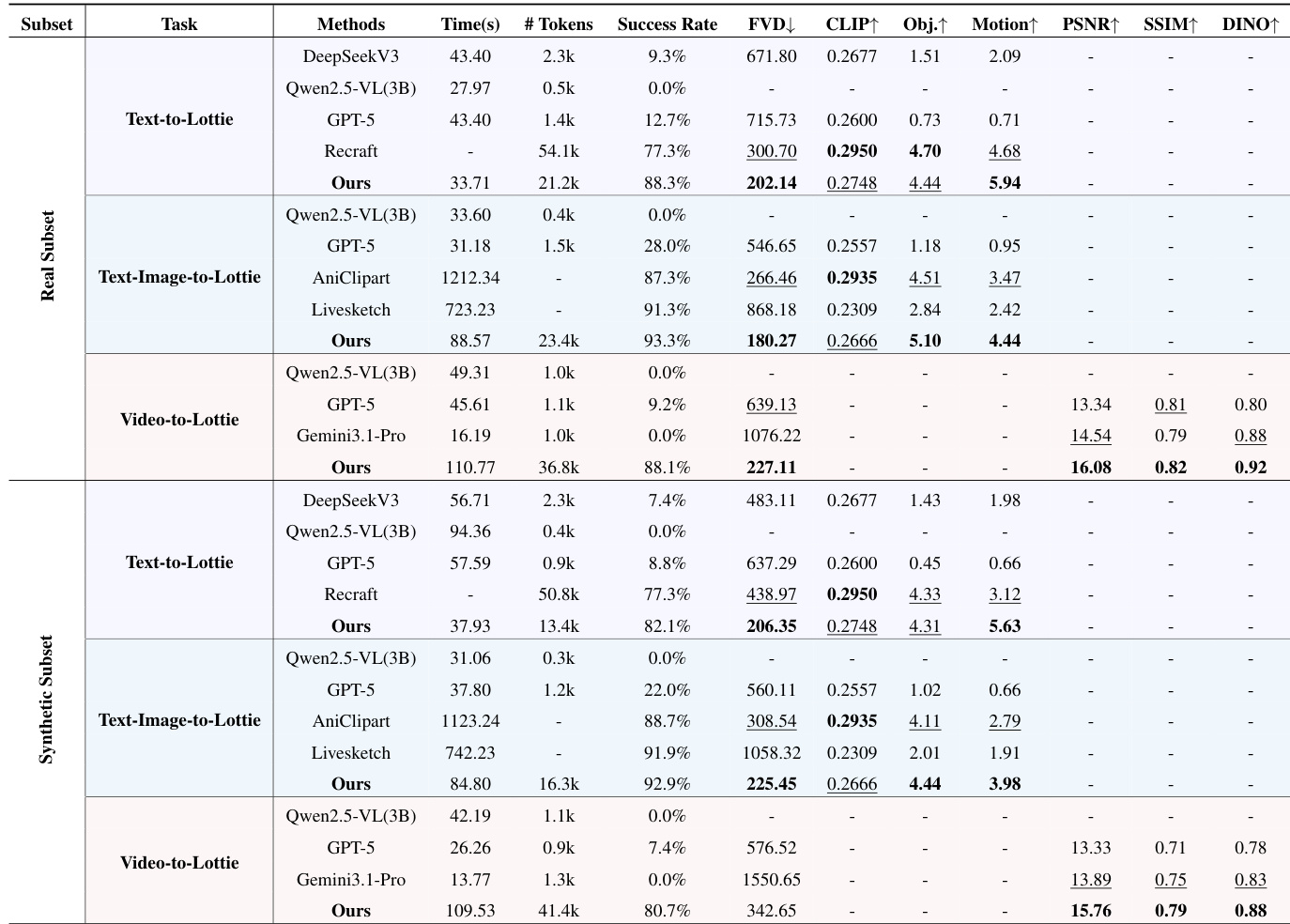
- OmniLotte 在文本到动画、图文到动画、视频到动画任务中全面优于所有基线,实现卓越的视觉质量、运动保真度和语义对齐。
- 定性结果证实 OmniLotte 生成更准确、更具表现力、视觉更连贯的动画,相较商业工具和 LLM/VLM 基线(存在结构错误、运动错位或成功率低),表现更优。
- 消融研究表明,适度混合 SVG 和 Lottie 数据可优化几何丰富性和运动复杂性,而自定义 Lottie 分词器显著提升生成质量和效率。
- 失败分析显示 OmniLotte 错误多为渲染层面(如缺失样式、时序错位),而基线失败于规范或输入依赖层面,使 OmniLotte 更可靠实用。
- 用户研究验证 OmniLotte 在人工评分维度——视觉质量、条件遵循、动画流畅度和几何保真度——占优,自动化指标(对象和运动对齐)与人工判断强相关。
- OmniLotte 实现高成功率(90.7–97.3%)和极低每成功输出生成时间(31 秒),相较基于优化的方法提速 52–530 倍。
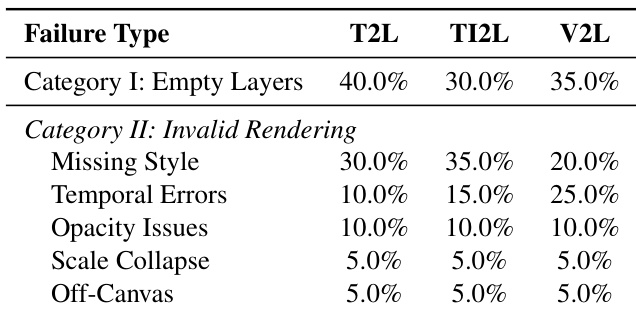
作者分析文本到动画、图文到动画、视频到动画任务中的失败模式,发现空图层生成是最常见结构失败,而渲染问题如缺失样式属性和时序错误主导无效输出。结果显示视频到动画最易出现时序错误,图文到动画则风格相关失败率更高,反映任务特定挑战——对齐视觉与文本输入。
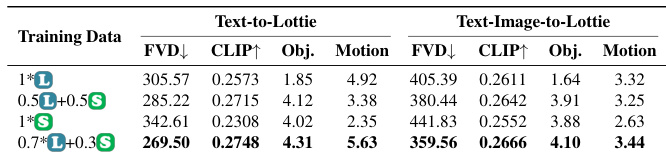
作者评估不同训练数据组合对 OmniLotte 的影响,发现 70% Lottie 与 30% SVG 数据混合在文本到动画和图文到动画任务中表现最佳。此平衡方法提升对象与运动对齐,同时保持视觉质量(以 FVD 和 CLIP 分数衡量)。结果表明适度 SVG 整合增强几何理解而不损害运动复杂性。
作者使用对象对齐和运动对齐等自动化指标评估生成动画,这些指标与人工判断在几何保真度和动画质量方面呈强正相关。结果表明,所提指标比 CLIP 或 FVD 更有效捕捉人类感知质量,验证其用于自动化评估的有效性。

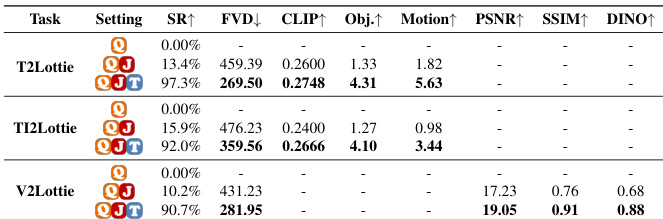
作者使用 OmniLotte 从文本、图文和视频输入生成 Lottie 动画,与多个基线(包括商业工具和大语言模型)对比。结果表明 OmniLotte 始终实现最高成功率,并在 FVD、对象对齐和运动对齐等关键指标上优于其他方法,同时保持高效生成速度。其结构化分词器和针对性训练支持跨所有输入模态的可靠、高保真矢量动画输出。
作者使用 OmniLotte 从文本、图文和视频输入生成 Lottie 动画,在成功率、视觉质量和运动对齐方面持续优于基线。结果表明 OmniLotte 在大多数指标中得分最高,尤其在运动保真度和标记效率方面,同时在真实和合成数据上均表现强劲。该方法相较基于优化和通用 VLM 方法也展现出更优的可靠性和速度。