Command Palette
Search for a command to run...
CUDA Agent:面向高性能CUDA内核生成的大规模智能体强化学习
CUDA Agent:面向高性能CUDA内核生成的大规模智能体强化学习
摘要
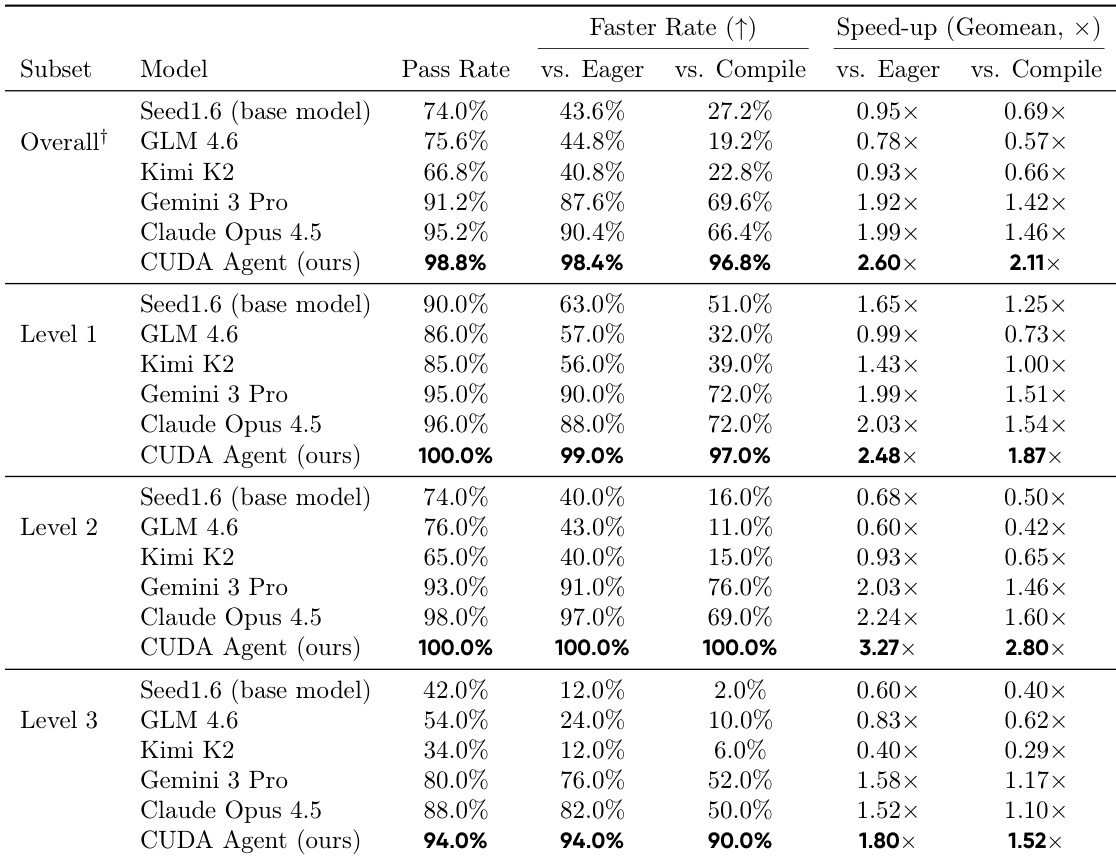
GPU内核优化是现代深度学习的基础,但仍是高度专业化的工作,需要深入的硬件知识。尽管大型语言模型(LLMs)在通用编程任务中表现出色,但在CUDA内核生成方面仍无法与基于编译器的系统(如torch.compile)相媲美。现有的CUDA代码生成方法要么依赖无训练的精炼机制,要么在固定多轮执行反馈循环中微调模型,但这两种范式均未能从根本上提升模型内在的CUDA优化能力,导致性能提升有限。为此,我们提出CUDA Agent——一个大规模代理式强化学习系统,通过三个核心组件构建CUDA内核开发专长:可扩展的数据合成管道、融合自动化验证与性能分析的技能增强型CUDA开发环境(以提供可靠奖励信号),以及支持稳定训练的强化学习算法技术。在KernelBench基准测试中,CUDA Agent取得了当前最优结果,在Level-1、Level-2和Level-3测试集上分别较torch.compile实现100%、100%和92%的加速,在最具挑战性的Level-3设置中,性能显著超越最强的专有模型(如Claude Opus 4.5和Gemini 3 Pro),提升幅度约为40%。
一句话总结
字节跳动 Seed 与清华 AIR 的研究人员推出了 CUDA Agent,这是一种基于代理的强化学习系统,通过可扩展的数据合成、技能增强环境和稳定的强化学习训练,在 KernelBench 上性能超越 torch.compile 和顶级大语言模型达 100%,使大语言模型无需硬件专业知识即可掌握 GPU 内核优化。
主要贡献
- CUDA Agent 引入了一个大规模代理强化学习系统,通过可扩展的数据合成流水线、具备自动化验证与性能分析的技能增强开发环境,以及支持长上下文稳定训练的强化学习技术,提升了大语言模型内在的 CUDA 内核优化能力。
- 该系统克服了先前方法的局限性(如静态优化循环或数据泄露),通过在严格隔离的环境中实现自主多轮调试与优化,提供可靠的基于性能的奖励信号。
- 在 KernelBench 上,CUDA Agent 在 Level-1、Level-2 和 Level-3 分割中分别比 torch.compile 快 100%、100% 和 92%,并在最难的 Level-3 任务上比 Claude Opus 4.5 和 Gemini 3 Pro 等专有模型快约 40%。
引言
作者利用大规模代理强化学习解决生成高性能 CUDA 内核的挑战——这是 GPU 加速深度学习中的关键任务,传统上需要深厚的硬件专业知识。以往方法要么依赖无需训练的启发式规则,要么在僵化的固定轮次循环内微调模型,两者均未能从根本上提升模型内在的优化能力,且常受限于数据泄露或上下文有限。CUDA Agent 通过整合可扩展的数据合成流水线、具备自动化验证和性能分析的技能增强开发环境,以及支持长上下文和多轮交互的强化学习技术,克服了这些限制。最终系统在最难基准测试上比 torch.compile 和 Claude Opus 4.5、Gemini 3 Pro 等顶级专有模型快达 40%,证明大语言模型可从被动代码生成器演变为 GPU 计算的主动性能优化器。
数据集

-
作者使用一个自建训练数据集 CUDA-Agent-Ops-6K²,包含 6,000 个精选的 PyTorch 算子类,用于通过强化学习训练具备 CUDA 能力的代理。
-
数据集来源与组成:
- 种子问题采自 torch 和 transformers 库,表示为具有
__init__和forward方法的torch.nn.Module子类。 - 复合问题由大语言模型合成,采样最多五个 torch 算子并顺序堆叠成融合计算层;由于 transformers 算子属于高层多算子结构,故排除在合成之外。
- 最终数据集包含原始算子和不同深度(1 至 5 个算子)的复合算子,以及部分独立的 transformers 模块以保持平衡。
- 种子问题采自 torch 和 transformers 库,表示为具有
-
过滤与质量控制:
- 每个算子必须在 Eager 和 Compile 模式下均能成功执行。
- 排除随机性算子以确保可复现性。
- 输出必须随输入有意义地变化——禁止恒定或数值完全相同的结果。
- Eager 模式下执行时间限制在 1–100 毫秒,避免过于简单或过重的任务。
- 使用基于 AST 的相似性(PythonASTSimilarity)过滤与 KernelBench 测试用例高度相似的样本;相似度超过 0.9 的样本被移除。
-
数据格式与结构:
- 每个样本包括算子类及两个辅助函数:
get_init_inputs()用于类实例化,getInputs()用于前向传递输入,构成自包含、可执行任务。 - 最终数据集组成反映有意混合:主要为复合算子(1–5 个算子),辅以部分独立 transformers 模块。
- 每个样本包括算子类及两个辅助函数:
-
训练用途:
- 该数据集是 CUDA Agent 的唯一训练语料,未使用任何外部数据。
- 训练任务直接从 6,000 个过滤样本中采样,未提及明确的混合比例或分层策略——暗示在精选集合中均匀采样。
方法
作者利用一个大规模代理强化学习系统 CUDA Agent,旨在自主为 PyTorch 模型生成高性能 CUDA 内核。系统围绕三个核心组件构建:可扩展的数据收集流水线、技能集成且防作弊的训练环境、以及稳定强化学习训练的算法创新。每个组件均针对 CUDA 内核生成的独特挑战设计,包括相关预训练数据稀疏、需精确正确性验证、以及低概率 token 空间中策略梯度不稳定等问题。
代理在结构化工作区中运行,强制隔离用户可修改文件与受保护文件。如下图所示,代理接收定义其角色为 PyTorch 和 CUDA 专家的 SKILL.md 提示,以及包含原始 model.py、受保护基础设施文件(binding_registry.h、binding.cpp、utils/)和 kernels/ 目录(所有自定义 CUDA 代码必须在此实现)的预定义工作目录。代理生成 model_new.py,导入并调用在 kernels/.cu 和 kernels/_binding.cpp 文件中实现的自定义算子。GPU Pool 执行生成代码,Performance 模块验证数值正确性并测量相对于 PyTorch Eager 和 torch.compile 基线的执行时间。
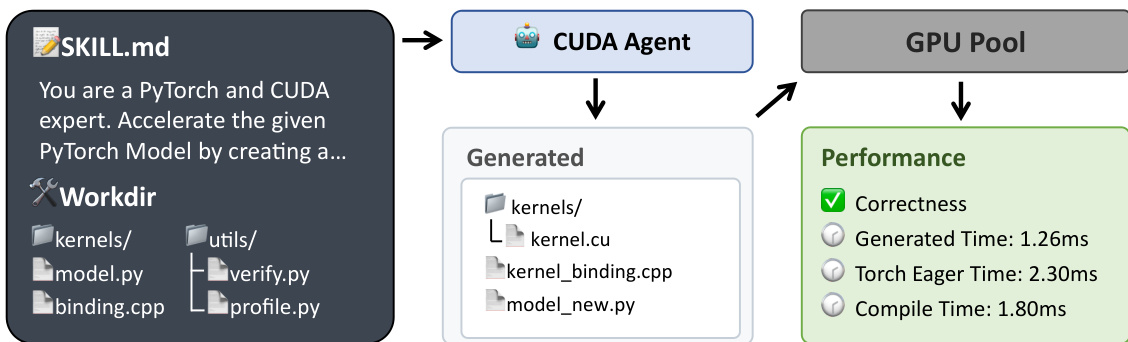
代理循环遵循 ReAct 风格范式,交错推理、动作执行与观察。代理配备一套开发者工具——包括 Bash、读/写、编辑/多编辑、Glob、Grep 和 NotebookEdit——使其能在沙盒环境中检查、修改、编译和调试代码。代理受 CUDA 特定的 SKILL.md 指导,形式化四步优化流程:(1) 分析原生 PyTorch 模型以识别瓶颈,(2) 针对这些瓶颈实现自定义 CUDA 算子,(3) 编译并评估优化模型,(4) 迭代直至在通过所有正确性检查的同时实现比 torch.compile 快 5%。
为防止奖励作弊,系统实施多重保障:受保护的评估脚本、禁止回退到 torch.nn.functional 的执行时间约束、针对五个随机输入的验证,以及精心设计的带设备同步与重复测量的分析流水线。奖励函数设计为对异常值鲁棒且避免偏向简单内核。作者不使用原始加速比,而是根据正确性与性能分配离散奖励 r∈{−1,1,2,3}:
r=⎩⎨⎧−1321if correctness check failsif b(t,teager)∧b(t,tcomplie)if b(t,teager)otherwise其中 b(t,t0)=I[(t0−t)/t0>5%] 表示相对于基线 t0 的显著加速。
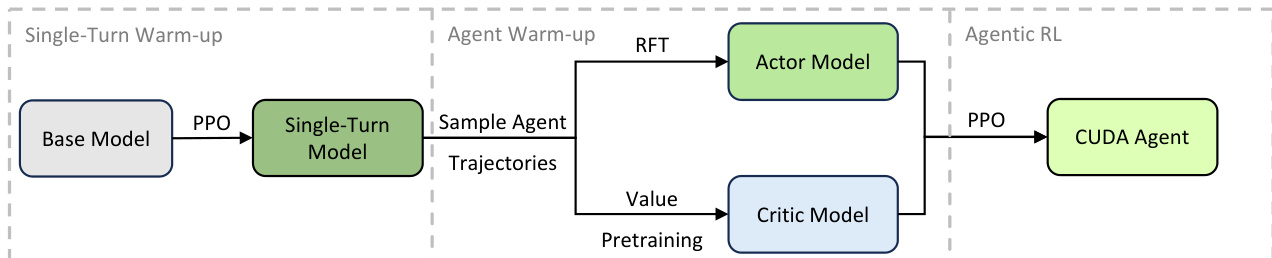
通过多阶段初始化过程实现训练稳定性。作者观察到,直接强化学习训练在 17 步后崩溃,原因是严重的领域分布不匹配:CUDA 内核 token 在基础模型预训练数据中极其罕见,导致数值精度错误时重要性采样比率方差巨大。为缓解此问题,他们引入暖身阶段(如下图所示)。首先,单轮强化学习阶段使用 PPO 微调基础模型。然后,拒绝微调(RFT)通过筛选获得正奖励且行为模式有效的轨迹来初始化演员模型。同时,价值预训练使用广义优势估计在相同轨迹数据上初始化评论家模型。仅在此暖身后,才启动完整的代理强化学习阶段,使用带裁剪代理目标的 PPO 优化演员策略。
系统有效性通过案例研究展示。对于涉及对角矩阵乘法的 Level 1 问题,代理识别出 A⋅B(其中 A 为对角矩阵)可简化为逐行缩放,无需显式构造对角矩阵。此代数简化在网格步长循环内核中实现,获得 73.31× 加速。对于涉及矩阵操作序列的 Level 2 问题,代理代数重排计算以融合操作,实现两个自定义内核(一个用于列向约简,一个用于带共享内存树约简的向量化点积),获得 24.04× 加速。对于 Level 3 的 ResNet BasicBlock,代理将 BatchNorm 折叠进 Conv 权重,使用 cuDNN 的融合卷积-偏置-激活 API,并融合残差加法与 ReLU,获得 3.59× 加速同时保持数值等价。
代理结合高层代数推理、库级融合和底层 CUDA 优化(如内存合并、共享内存分块、向量化加载)的能力,展示了超越简单代码翻译的全面内核生成方法。结构化环境、稳健奖励设计和稳定训练协议使代理能持续生成在各种问题复杂度上超越 torch.compile 的内核。
实验
- CUDA Agent 在正确性与优化能力上超越主流专有及开源模型,通过代理强化学习生成高度优化的 CUDA 内核,实现近乎完美的通过率与加速率。
- 代理持续超越静态编译器启发式,尤其在复杂算子融合任务中,通过探索规则编译器无法触及的硬件特定优化。
- 与执行反馈(编译、分析、错误)的多轮交互至关重要;单轮训练导致性能下降与退化。
- 基于里程碑的奖励设计优于原始加速奖励,通过避免嘈杂的运行时信号,实现更可靠的性能增益发现。
- 多阶段训练——特别是拒绝采样微调与价值预训练——对稳定学习、防止策略崩溃和引导高效探索至关重要。
- 常见优化模式包括代数简化、内核融合、内存访问调优、硬件感知的 TF32 使用和策略性库调用,展示算法与底层工程的系统性衔接。
- 训练依赖大型隔离 GPU 沙盒以确保稳定测量,虽有效但资源需求大且限制可访问性。
作者使用多轮强化学习框架,结合专门的奖励塑形与预训练阶段训练 CUDA 优化代理,该代理在所有任务难度级别上持续超越专有与开源模型。结果表明,来自编译与分析的迭代反馈,结合基于里程碑的奖励,使代理生成的内核不仅功能正确,且显著快于静态编译器基线。代理性能增益在复杂算子序列中最为显著,它发现了传统编译器无法通过基于规则启发式实现的硬件感知优化。
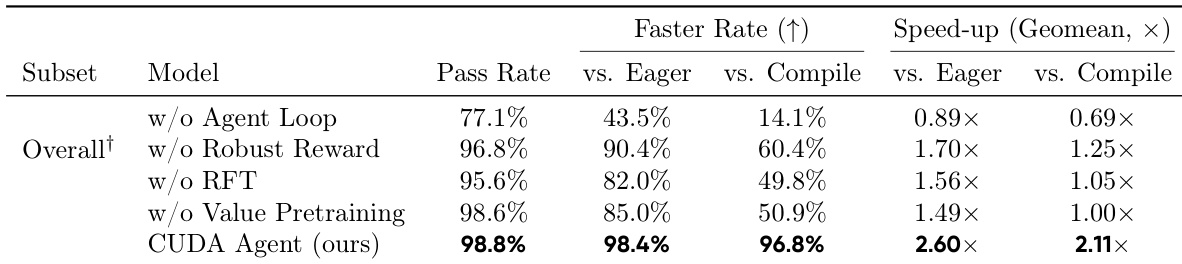
作者使用结合技能集成反馈的多轮强化学习框架训练 CUDA 优化代理,通过编译与分析信号实现迭代精炼。结果表明,此方法显著优于通用大语言模型和静态编译器基线,通过发现规则系统无法触及的硬件感知优化,实现近乎完美的正确性与显著加速。消融研究确认,代理循环、基于里程碑的奖励设计和多阶段训练对稳定有效的策略学习至关重要。

作者使用多阶段强化学习框架与交互式代理循环训练专用 CUDA 内核优化器,实现 98.8% 的通过率和 96.8% 的加速率(相对于 torch.compile)。结果表明,移除关键组件——如代理循环、稳健奖励设计或价值预训练——会导致优化质量显著下降和训练不稳定,确认其对可靠性能增益的必要性。最终系统通过迭代反馈与硬件感知转换,持续超越通用大语言模型和静态编译器基线。