Command Palette
Search for a command to run...
通过奖励建模增强图像生成中的空间理解
通过奖励建模增强图像生成中的空间理解
Zhenyu Tang Chaoran Feng Yufan Deng Jie Wu Xiaojie Li Rui Wang Yunpeng Chen Daquan Zhou
摘要
近年来,文本到图像生成技术在视觉保真度与创造力方面取得了显著进展,但也对提示(prompt)的复杂性提出了更高要求,尤其是在编码复杂空间关系方面。在这些场景下,往往需要多次采样才能获得满意的结果。为应对这一挑战,我们提出一种新方法,旨在增强当前图像生成模型的空间理解能力。我们首先构建了一个包含超过8万组偏好对的SpatialReward-Dataset。基于该数据集,我们设计了SpatialScore——一种用于评估文本到图像生成中空间关系准确性的奖励模型,在空间关系评估任务上的表现甚至超越了当前领先的专有模型。进一步实验表明,该奖励模型能够有效支持复杂空间生成任务中的在线强化学习。在多个基准测试上的大量实验结果表明,我们提出的专用奖励模型在提升图像生成的空间理解能力方面实现了显著且一致的性能提升。
一句话总结
北京大学与字节跳动Seed的研究人员提出SpatialScore,一种基于80,000+偏好对训练的奖励模型,旨在增强文生图生成中的空间理解能力,支持有效的强化学习,并在多个基准测试中超越专有模型的空间准确性表现。
主要贡献
- 作者引入SpatialReward-Dataset,一个由人工精心筛选的80,000组对抗性偏好对数据集,用于评估文生图生成中的空间关系准确性,填补了可靠空间评估数据的空白。
- 作者开发了SpatialScore,该奖励模型在该数据集上训练,能更准确地评估复杂空间关系,优于主流专有模型,为强化学习提供更精确的反馈。
- 作者将SpatialScore集成到在线强化学习中,并采用top-k过滤策略,相较于基础模型,在多个基准测试中实现了持续且显著的空间理解能力提升。
引言
作者利用强化学习改进文生图模型处理复杂空间关系的能力——这对生成准确、构图正确的场景至关重要,尤其当提示词描述物体布局时。以往的奖励模型,无论是基于CLIP还是视觉语言模型(VLM)驱动的,都难以检测空间错误,常错误奖励错误布局;而基于规则或专有系统则要么过于简单,要么成本过高,不适合在线强化学习。其主要贡献是SpatialScore,一种在80,000组对抗性偏好数据集(SpatialReward-Dataset)上训练的奖励模型,可可靠评估空间准确性并超越主流专有模型;他们进一步将其集成到在线强化学习中,采用top-k过滤策略,在多个基准测试中实现空间推理能力的持续提升。
数据集
-
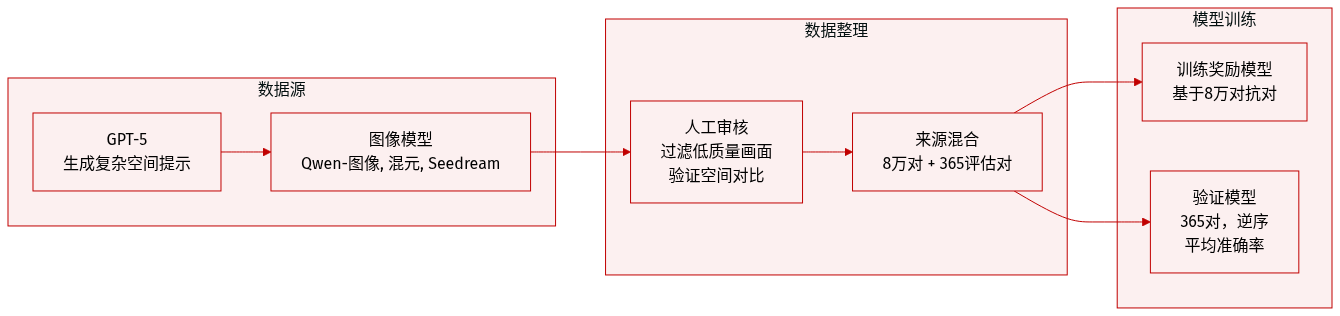
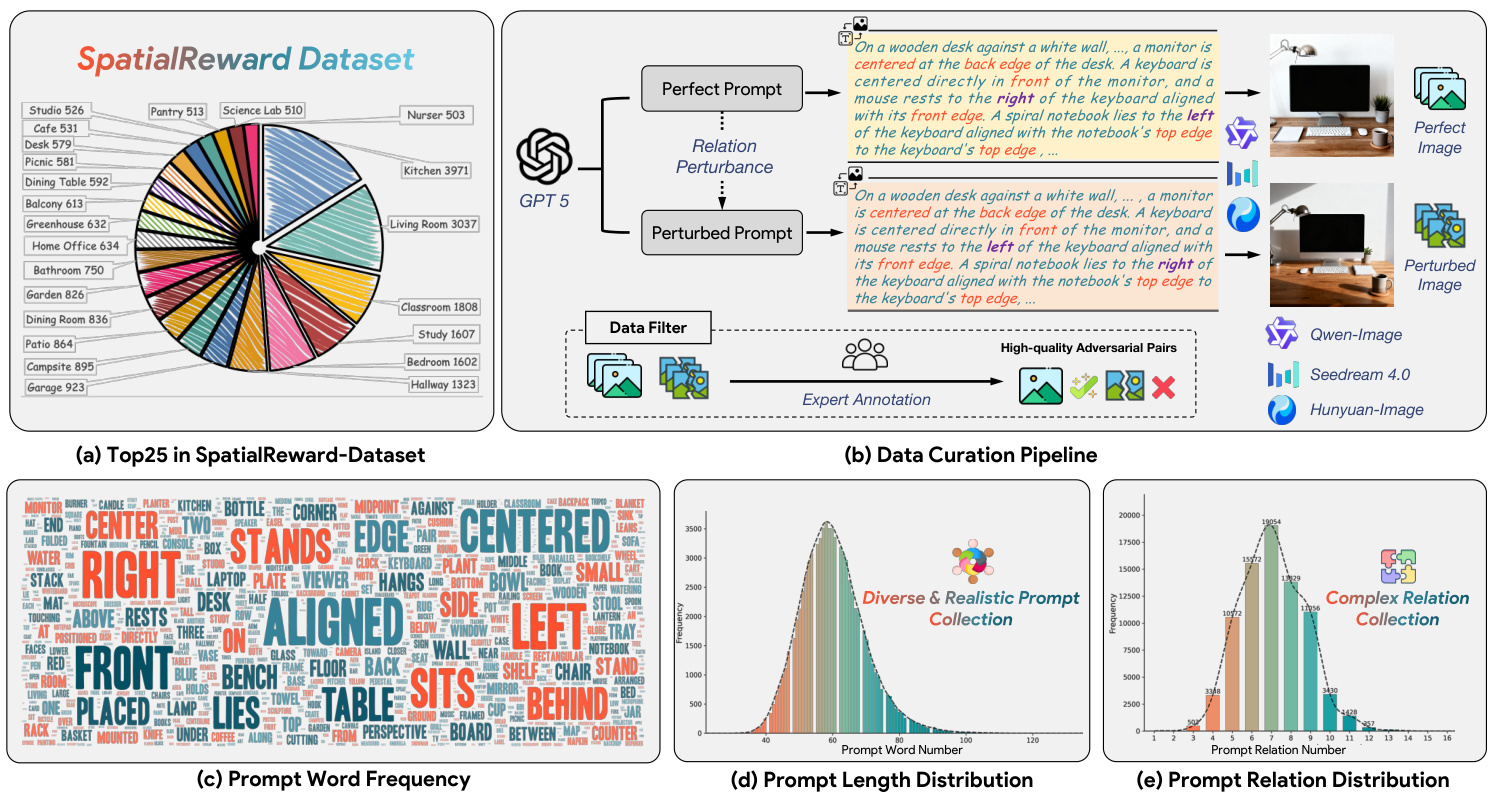
作者使用SPATIALREWARD-DATASET作为奖励模型训练的基础,该数据集包含80,000组对抗性图像对,每组由“完美”图像(由干净提示生成)和“扰动”图像(由空间关系修改后的提示生成)组成,旨在隔离空间推理错误。
-
数据集构建始于GPT-5生成描述多物体空间关系的复杂提示。GPT-5随后通过修改一个或多个空间关系(如交换位置、左右偏移)来扰动每个提示,同时保持其余内容不变。图像由Qwen-Image、HunyuanImage-2.1和Seedream4.0生成——这些模型因强大的文图对齐能力而被选中,以减少后期过滤需求。
-
所有80,000组图像对均经过人工审核:完美图像必须完全满足提示中的空间约束;扰动图像必须在指定空间关系上明显偏离。不符合任一标准的图像对将被剔除。提示词长度和空间复杂性显著高于GenEval,支持更高的构图多样性。
-
为评估,作者使用相同的生成和验证流程构建了一个包含365组偏好对的独立基准。人工标注者验证每组以确保可靠的真值。评估包括专有模型(GPT-5、Gemini-2.5 Pro)、Qwen2.5-VL系列(7B–72B)和现有奖励模型(PickScore、ImageReward、UnifiedReward、HPS)。为减轻顺序偏差,每组图像对以相反顺序评估两次,最终准确率取两次平均值。
-
未提及裁剪或元数据构建。重点在于提示驱动生成和人工验证,以确保空间保真度和对比性。该数据集设计使奖励模型能够专门针对空间推理能力进行训练和评估。
方法
作者采用两阶段框架:首先训练专用奖励模型SpatialScore,然后将其部署到在线强化学习循环中,以增强图像生成的空间推理能力。架构核心是微调视觉语言模型主干,输出概率奖励分数,随后在策略优化阶段使用基于组的优势估计和top-k过滤策略以减轻偏差。
奖励模型基于Qwen2.5-VL-7B构建,其原始语言建模头被替换为线性奖励头 Rϕ,将图文联合嵌入映射为标量奖励。为建模不确定性并提高排序鲁棒性,作者采用高斯公式:在指令提示末尾插入特殊标记,其最后一层嵌入通过MLP投影为参数 μ 和 σ,定义一维高斯分布 s∼N(μ,σ2)。奖励分数从该分布中采样。对于每组偏好对 (c,yw,yl),模型执行两次前向传播计算分数 sw 和 sl,并通过二元交叉熵损失优化Bradley-Terry模型:
LReward(θ)=Ec,yw,yl[−logσ(Rϕ(Hϕ(yw,c))−Rϕ(Hϕ(yl,c)))].训练使用LoRA保留预训练知识,并为每组偏好对使用1000次蒙特卡洛采样以稳定梯度估计。模型在SpatialReward-Dataset的80,000组偏好对上训练,这些数据对由扰动提示中的空间关系并通过Qwen-Image、Seedream 4.0和Hunyuan-Image生成对应图像对,再经专家标注确保高质量对抗性数据对。完整数据整理流程(包括提示扰动、图像生成和过滤阶段)请参见框架图。
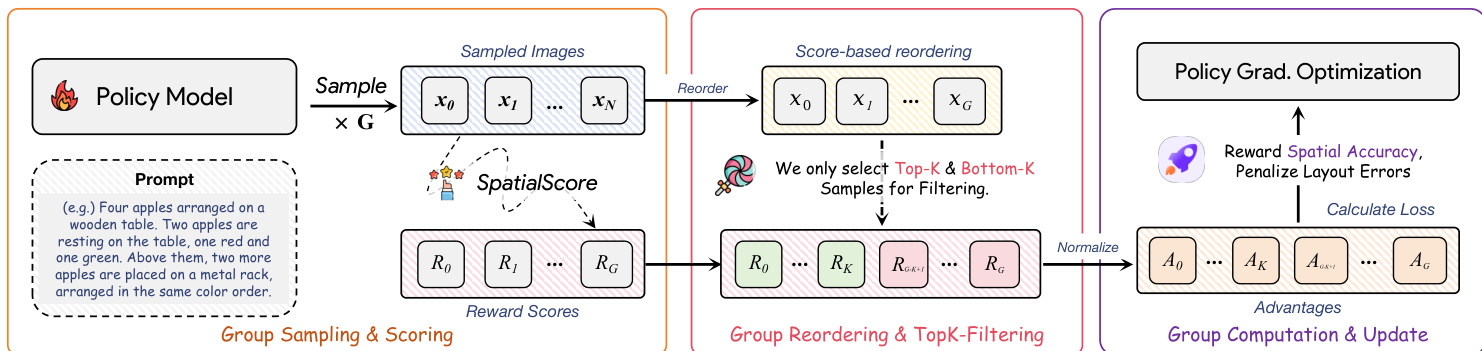
在策略优化阶段,作者将SpatialScore集成到GRPO算法中,使用FLUX.1-dev作为基础生成器。策略 πθ 通过源自流匹配的SDE为每个提示采样一组 G 张图像,实现随机探索。每张图像由SpatialScore评分,组内优势通过归一化分数计算:
Ai=std({R(x0i,c)}i=1G)R(xi0,c)−mean({R(x0i,c)}i=1G).为应对优势偏差——即简单提示因组均值膨胀导致高质量样本获得负优势——作者引入top-k和bottom-k过滤策略。仅使用得分最高和最低的 k 个样本计算组统计量并更新策略,确保奖励信号平衡。策略随后通过裁剪代理目标优化:
LGRPO(θ)=∣S∣1i∈S∑T1t=0∑T−1min(rti(θ)Ati,clip(rti(θ),1−ϵ,1+ϵ)Ati),并附加KL惩罚以约束与参考策略的偏离。如训练流程图所示,该过程直接奖励空间准确性并惩罚布局错误,实现对空间理解的定向增强。
实验
- SPATIALSCORE,一个微调的7B奖励模型,在评估复杂多物体空间关系时达到最先进的准确率(95.77%),优于GPT-5和Gemini-2.5 Pro等专有模型,同时适合在线强化学习的低成本需求。
- 在线强化学习中用于微调Flux.1-dev时,SPATIALSCORE显著提升生成图像的空间推理能力,尤其在长而复杂的提示下,优于基于规则的GenEval训练变体——后者在空间保真度上退化并引入伪影。
- 强化学习增强的模型在域内和域外基准测试(DPG-Bench、TIIF-Bench、UniGenBench++)中表现一致提升,性能接近GPT-Image-1等专有模型,显示出超越空间任务的广泛泛化能力。
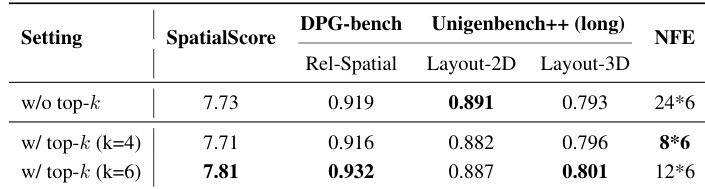
- 消融实验证实,扩大SPATIALSCORE的主干规模可提高准确性,7B变体在性能和训练效率间取得最佳平衡;强化学习训练中的top-k过滤加速收敛并降低计算成本,同时不牺牲质量。
- SPATIALSCORE的有效性也扩展到其他基础模型如Qwen-Image,在多个基准测试中持续提升空间理解能力,验证了其作为空间复杂图像生成奖励信号的通用性和鲁棒性。
作者使用其专用奖励模型SpatialScore指导Flux.1-dev的在线强化学习,在多个基准测试中相较于基础模型和基于规则奖励训练的变体,实现了空间推理能力的显著提升。结果表明,该方法在长提示和域外评估中持续改进空间对齐能力,显示出更强的泛化能力和对复杂多物体空间描述的更忠实遵循。

作者使用其专用奖励模型SpatialScore指导图像生成的在线强化学习,在多个基准测试中实现空间理解能力的显著提升。结果表明,该方法不仅在域内空间评估上优于基础Qwen-Image模型,还在域外空间子维度(包括短提示和长提示设置)上表现更优。这些提升表明,使用SpatialScore进行奖励引导训练增强了模型准确渲染提示中描述的复杂多物体空间关系的能力。

作者使用其专用奖励模型SPATIALSCORE指导Flux.1-dev的在线强化学习训练,在多个评估维度上实现空间理解能力的显著提升。结果表明,该方法优于基础模型和基于规则奖励训练的变体,尤其在复杂空间关系和长提示上表现突出。增强后的模型在综合对齐基准上也接近GPT-Image-1等专有系统的表现。
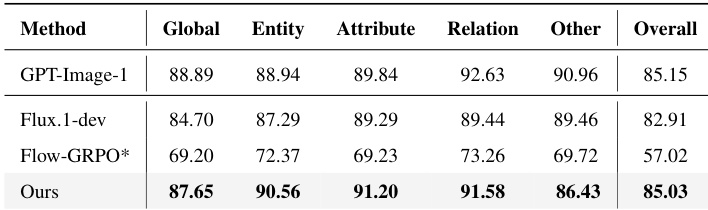
作者使用其专用奖励模型SPATIALSCORE指导Flux.1-dev的在线强化学习训练,在多个空间推理维度(包括物体定位和属性一致性)上实现性能提升。结果表明,该方法持续优于基础模型,尤其在复杂多物体空间关系上表现突出,同时相比基于规则奖励训练的模型展现出更好的泛化能力。该方法通过聚焦细粒度空间对齐而非依赖通用文图匹配,实现更高的整体得分。

作者在在线强化学习训练中采用top-k过滤策略,以平衡不同难度提示的奖励分布,从而降低计算成本同时维持或提升性能。结果表明,使用k=6可获得最佳权衡,在空间推理基准上得分更高,函数评估次数少于未过滤基线和k=4变体。该优化在不牺牲空间理解质量的前提下实现更高效的训练。