Command Palette
Search for a command to run...
推测性解码
推测性解码
Tanishq Kumar Tri Dao Avner May
摘要
自回归解码受限于其固有的顺序执行特性。投机解码(Speculative Decoding)已成为加速推理的标准方法:它利用一个快速的草稿模型(draft model)预测来自较慢目标模型(target model)的后续 token,并通过目标模型的单次前向传播对这些预测进行并行验证。然而,投机解码本身仍依赖于投机与验证之间的顺序依赖关系。为此,我们提出“双重投机解码”(Speculative Speculative Decoding, SSD)以将上述操作并行化。在验证进行的同时,草稿模型可预测可能的验证结果,并预先为这些结果生成投机序列。若实际验证结果落在预测集合中,则可直接返回投机结果,从而完全消除草稿生成阶段的开销。本文识别了双重投机解码面临的三大关键挑战,并提出了系统性的解决方案。基于此,我们提出了名为 Saguaro 的优化型 SSD 算法。实验表明,相较于优化的投机解码基线,Saguaro 的实现速度提升高达 2 倍;与开源推理引擎下的自回归解码相比,速度提升则高达 5 倍。
一句话总结
斯坦福大学、普林斯顿大学和Together AI的研究人员提出了SAGUARO,一种“双重投机解码”方法,通过提前预判验证结果消除草稿开销,在开源推理中相比先前的推测解码方法最高提速2倍,相比自回归解码最高提速5倍。
主要贡献
- 双重投机解码(SSD)通过在验证仍在进行时,预先为多种可能的验证结果进行推测,打破了标准推测解码中的顺序依赖,当预测与实际结果匹配时可立即返回token。
- 作者识别了SSD设计中的三个关键挑战,并提出SAGUARO——一种优化算法,可在不增加验证器负载的前提下扩展推测计算,保持正确性并支持异步操作。
- 在多个开源推理引擎上的评估显示,SAGUARO相比优化后的推测解码基线最高提速2倍,相比自回归解码最高提速5倍,同时在延迟和吞吐量方面均有提升。
引言
作者利用推测解码加速大语言模型推理:使用快速草稿模型预测多个后续token,再与目标模型并行验证。然而,现有方法仍受限于顺序依赖:必须等待验证完成后才能开始下一轮推测。其主要贡献是双重投机解码SSD,该框架通过为多种可能的验证结果预先推测,实现草稿与验证的并行化,消除顺序约束。SSD相比先前的推测解码最高提速2倍,相比自回归生成最高提速5倍,同时兼容先进的草稿模型和树状推测技术。
方法
作者利用双重投机解码(SSD)打破传统推测解码中草稿与验证之间的顺序依赖。在SSD中,当目标模型正在验证当前推测时,草稿模型在独立设备上异步运行,预测可能的验证结果(由接受的token数和采样的奖励token定义),并为每种结果并行预推测token序列。若实际验证结果匹配某个预计算结果,则立即返回对应推测,无需实时草稿,从而降低延迟。该框架无损,且要求草稿模型必须部署在与目标模型不同的硬件上,以实现推测与验证的真正重叠。
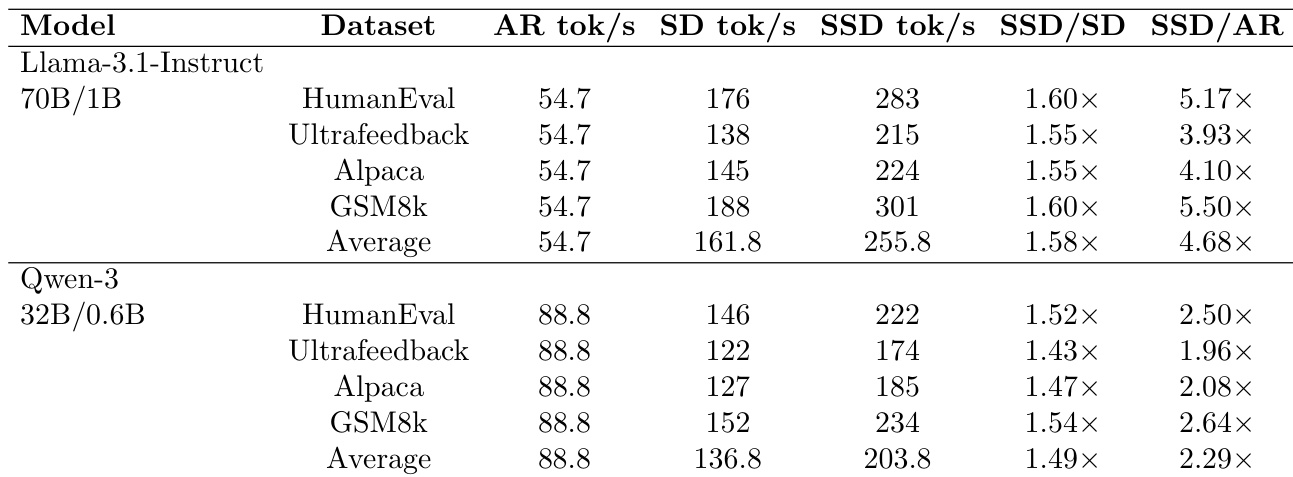
如下图所示,SSD工作流与普通推测解码(SD)不同,它将草稿计算与目标验证时间线解耦。SD迫使草稿在验证期间空闲,而SSD允许草稿并发预计算多个推测分支。图中还展示了端到端性能增益:在Llama-3.1-70B上,SSD相比自回归解码最高实现4.0倍吞吐量提升,相比SD提升2.6倍,证明了推测与验证并行化的有效性。
为实现此目标,作者引入SAGUARO——一种优化的SSD算法,解决三个核心挑战:准确预测验证结果、平衡缓存命中率与推测质量、高效处理缓存未命中。推测缓存是关键组件,它将每个可能的验证结果 vT=(k,t∗) 映射到预计算的推测 sT。在第 T 轮验证期间,草稿模型预测一组可能结果 VT 并并行推测每个结果,将结果存入缓存。收到实际结果后,系统执行缓存查找:若结果存在,则返回预计算token;否则调用回退策略。
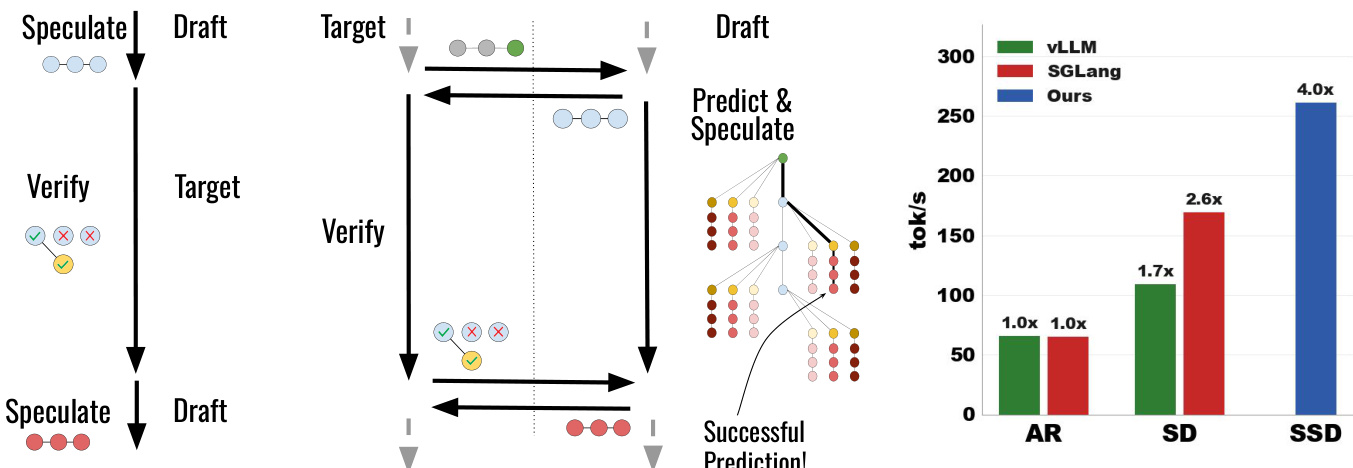
缓存构建由定理12推导出的几何扇出策略指导。给定计算预算 B,算法在序列位置 k∈[0,K] 上分配扇出值 Fk 以最大化缓存命中概率。最优分配遵循几何级数:Fk=F0⋅apk/(1+r)(当 k<K),以及 FK=F0⋅apK/(1+r)⋅(1−ap)−1/(1+r),其中 ap 是草稿的接受率,r 是缓存命中率的幂律指数。该分配反映了直觉:更长的验证结果可能性更低,应分配更少的推测资源。下图可视化了该策略:当在位置 k=2 验证推测时,草稿为可能的奖励token准备 F2=3 个推测分支,而为无token接受的情况仅分配 F0=1。
为提高缓存命中率,SAGUARO引入了一种新颖的采样方案,使草稿分布偏向增加缓存token上的残余概率质量。Saguaro采样方案 σF,C(z) 将前 F 个草稿logits按因子 C∈[0,1] 降权,使残余分布 r(⋅)∝max(ptarget(⋅)−pdraft(⋅),0) 更集中于这些token。这增加了奖励token落在缓存中的可能性,但可能降低接受率。该权衡通过超参数 C 管理,可调以平衡命中率和接受率。
对于缓存未命中,SAGUARO采用批大小感知的回退策略。在小批大小时,使用与主推测器相同的高质量草稿模型。在大批大小时(缓存未命中频繁并阻塞整个批次),切换至低延迟备用推测器以最小化延迟。关键批大小 b∗ 通过分析推导,以最大化端到端加速。
系统实现中,目标模型运行在4个H100 GPU上,草稿模型运行在独立的H100上。每轮通过NCCL通信一次,仅交换验证结果(接受token数和奖励token),并接收预计算推测或回退结果。为支持所有 B(K+1)F 个推测分支的并行解码,草稿使用自定义稀疏注意力掩码。如下图所示,该掩码允许每个分支关注已验证前缀(通过“Prefix Mask”块)及其自身分叉路径(通过“Tree Decode Diagonals”),而“Glue & Recurrence”确保分支共享相同的前缀上下文。此设计支持高效的多查询解码,但引入内存访问开销,限制了实际前瞻长度 K。
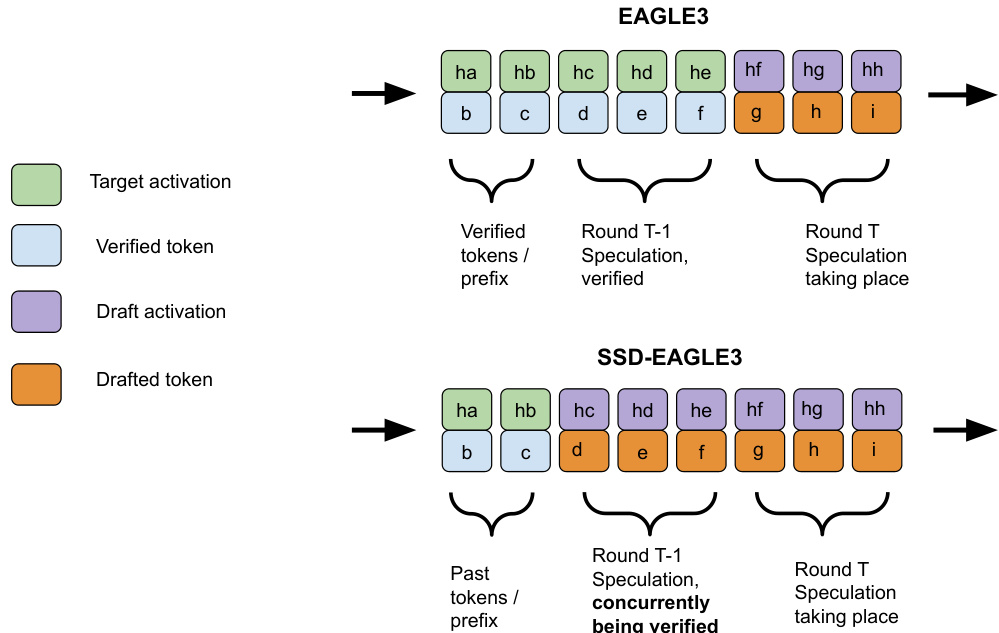
最后,SAGUARO兼容先进的推测解码变体。例如,当与EAGLE-3结合时(该方法根据目标激活调整草稿),SSD-EAGLE-3必须在预推测期间用草稿激活替代不可用的目标激活。下图对比了两者:在标准EAGLE-3中,草稿基于已验证的目标激活;在SSD-EAGLE-3中,它基于自身激活进行后半部分推测,除非草稿经过训练以处理自条件化,否则可能降低质量。
实验
- SAGUARO优于自回归解码和标准推测解码,最高实现5倍加速,推动延迟-吞吐量帕累托前沿,尤其在小批大小时表现突出。
- 理论分析确认SAGUARO的加速取决于缓存命中率、草稿效率和延迟隐藏,在相同推测器下严格优于标准推测解码。
- 几何扇出策略相比均匀策略提升缓存命中率和解码速度,尤其在较高温度下,命中率随缓存大小可预测地扩展。
- SAGUARO采样通过重塑草稿分布偏向缓存token,实现命中率与推测接受率之间的可调权衡。
- 在大批大小时,快速随机备用推测器优于较慢的神经网络推测器;通过增加GPU扩展草稿计算可进一步提升速度(扩大缓存容量)。
- 结果在多个模型族(Llama-3和Qwen-3)中通用,确认该方法在不同架构和数据集上的鲁棒性。
作者在多个模型和数据集上评估SAGUARO与自回归及推测解码基线的对比,显示一致的加速效果。结果表明,SAGUARO比推测解码快1.5至5.5倍,比自回归解码最高快5倍,增益随模型大小和数据集变化。该方法在不同模型族中均有效,确认其泛化能力。