Command Palette
Search for a command to run...
异构智能体协同强化学习
异构智能体协同强化学习
Zhixia Zhang Zixuan Huang Xin Xia Deqing Wang Fuzhen Zhuang Shuai Ma Ning Ding Yaodong Yang Jianxin Li Yikun Ban
摘要
我们提出了一种名为异构智能体协同强化学习(Heterogeneous Agent Collaborative Reinforcement Learning, HACRL)的新学习范式,旨在解决孤立式同策略优化(on-policy optimization)中存在的效率低下问题。HACRL 实现了“协同优化、独立执行”:在训练阶段,异构智能体共享经验回放轨迹(rollouts)以相互提升性能;而在推理阶段,各智能体则独立运行。与基于大语言模型(LLM)的多智能体强化学习(MARL)不同,HACRL 无需协调部署;与同策略/异策略蒸馏(on-/off-policy distillation)方法相比,HACRL 支持异构智能体间的双向互学习,而非单向的“教师 - 学生”知识迁移。基于该范式,我们提出了 HACPO 算法。该算法通过 principled(有理论依据的)经验回放共享机制,最大化样本利用率并促进跨智能体的知识迁移。为缓解智能体间的能力差异及策略分布偏移问题,HACPO 引入了四种定制化机制,并在无偏优势估计与优化正确性方面提供了理论保障。在多种异构模型组合及推理基准测试上的广泛实验表明,HACPO 能持续提升所有参与智能体的性能,其平均表现优于 GSPO 算法 3.3%,同时仅需一半的经验回放成本。
一句话总结
来自北京航空航天大学及合作机构的研究人员提出了 HACRL,这是一种使异构智能体能够在无需协调部署的情况下共享已验证的 rollout 以实现共同进步的范式。其算法 HACPO 引入了双向学习机制,在推理基准测试中表现优于 GSPO,同时将 rollout 成本降低了一半。
主要贡献
- 异构智能体协同强化学习(HACRL)通过使异构智能体在训练期间共享已验证的 rollout,同时在推理时保持独立执行,解决了孤立策略优化效率低下的问题。
- 提出的 HACPO 算法通过四种定制机制实现了该范式,这些机制缓解了能力差异和策略分布偏移,确保了无偏的优势估计并最大化样本利用率。
- 在多种异构模型组合和推理基准测试上的广泛实验表明,HACPO 始终能提升所有参与智能体的性能,平均表现优于 GSPO 3.3%,同时仅使用一半的 rollout 成本。
引言
具有可验证奖励的强化学习(RLVR)已成为训练强大推理模型的标准方法,但由于孤立的策略内采样(即每个智能体生成并丢弃自己的轨迹),其计算成本高昂。先前的方法如多智能体强化学习需要协调执行,这对于独立部署而言并不切实际;而知识蒸馏通常强制从教师到学生的单向传递,限制了异构模型间的双向学习。作者引入了异构智能体协同强化学习(HACRL)及其算法 HACPO,使独立智能体能够在训练期间共享已验证的 rollout 以实现共同进步。该框架通过跨多个智能体重用轨迹来最大化样本效率,并通过四种定制机制解决能力差异和策略分布偏移问题,从而确保无偏优化。
方法
作者提出了异构智能体协同策略优化(HACPO),这是一个旨在促进异构大语言模型(LLM)智能体之间 rollout 共享和知识转移的新框架。与通常依赖联合响应的传统多智能体强化学习(MARL)或遵循单向路径的知识蒸馏不同,HACRL 通过跨智能体重用 rollout,实现了独立执行与相互学习。
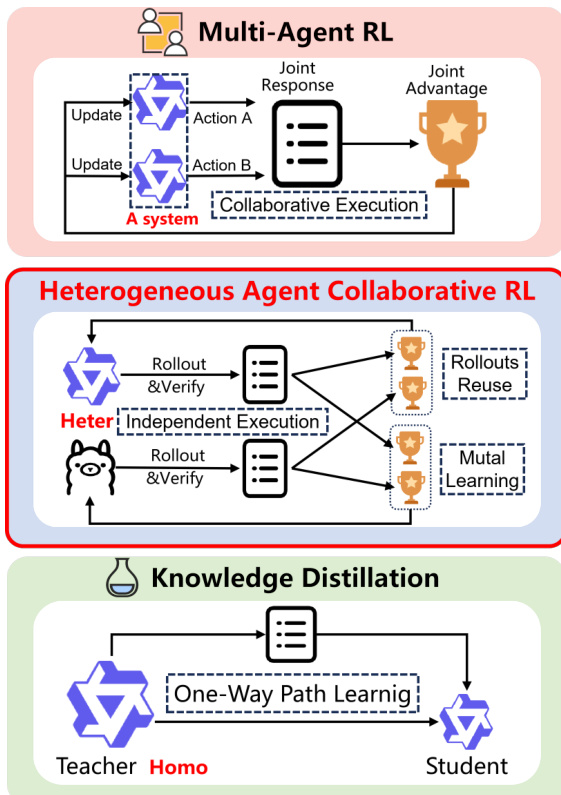
HACRL 的核心目标是通过最大化结合自生成经验(Jhomo)和跨智能体信息(Jhete)的联合目标来优化每个智能体 k。这种公式化使智能体能够从同伴的多样化能力中受益,同时管理由异构性带来的挑战。
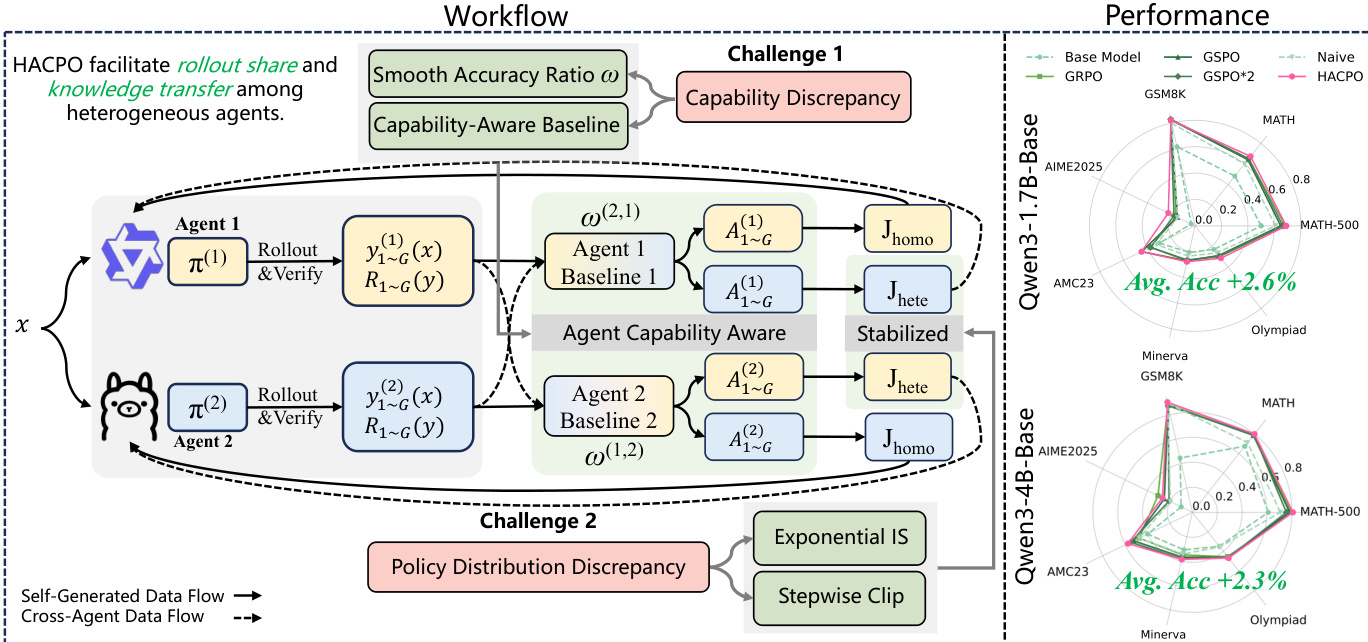
如工作流图所示,训练过程涉及两个主要挑战:能力差异和策略分布差异。为解决这些问题,HACPO 包含了四种定制修改。
智能体能力感知优势估计 标准的组相对优势估计仅依赖自生成奖励,这在异构设置中并非最优。HACPO 引入了一个能力调整基线 μ^t(k),该基线利用所有智能体的奖励,并根据其相对能力进行重加权。响应 yt,i(k) 的优势定义为:
At,i(k)=σt,jointR(yt,i(k))−μ^t(k)其中 σt,joint 是所有智能体奖励的标准差。基线 μ^t(k) 使用能力比率 ωt(k,j) 计算:
μ^t(k)=nG1j=1∑ni=1∑Gωt(k,j)R(yt,i(j))这里,ωt(k,j) 表示智能体 k 与智能体 j 之间的平滑性能比率,确保基线在不同能力的智能体之间得到适当校准。
模型能力差异系数 为了进一步处理能力差距,该框架在利用跨智能体样本更新智能体时,直接将能力比率应用于优势。当智能体 k 从智能体 j 生成的响应中学习时,有效优势被缩放:
A~t,i(k)=ωt(j,k)At,i(j)该机制鼓励从更强的智能体中进行激进学习,同时对来自较弱智能体的样本采用保守更新策略。
指数重要性采样 为了纠正生成样本的策略与被更新策略之间的分布不匹配,HACPO 采用序列级重要性采样。对于由智能体 j 生成并用于更新智能体 k 的响应 yt,i(j),重要性比率如下:
st,i(k,j)=πθold(j)(yt,i(j))πθt(k)(yt,i(j))∣yt,i(j)∣1鉴于智能体间的策略差异可能很大,作者引入了非梯度指数重加权以减轻激进更新:
s~t,i(k,j)=st,i(k,j)⋅(sg[st,i(k,j)])α其中 α≥0 控制保守程度。
逐步裁剪 最后,为了稳定训练并防止跨智能体 rollout 主导梯度更新,HACPO 利用非对称裁剪方案。与标准的对称裁剪不同,跨智能体重要性比率的严格上限被限制为 1.0:
st.i(k,j)∈[1.0−δ,1.0]此外,在每个训练步骤中应用逐步裁剪策略。随着参数更新次数 k 的增加,下界收紧:
clip(st,i(k,j))=clip(st,i(k,j),1−δ+k⋅δstep,1.0)这确保了随着训练步骤的推进,跨智能体响应受到越来越严格的约束,从而在异构协同策略优化过程中保持稳定性。
实验
- 在三种异构设置(状态、大小和模型架构)下的实验验证,HACPO 通过促进不同能力智能体间的双向知识交换,优于单智能体基线和朴素的多智能体方法。
- 定性分析证实,更强的模型从较弱智能体的互补探索信号和 informative 错误中受益,而较弱的模型则从更强同伴的指导中获益,证明学习并非纯粹的单向过程。
- 消融研究表明,智能体能力感知优势估计和梯度调制对于纠正系统性偏差和平衡异构智能体间的学习率至关重要。
- 逐步裁剪的必要性被确立为稳定训练的关键机制,可防止跨智能体响应中不可预测的重要性采样值引起的严重不稳定性。
- 在不同模型组合(包括不同架构和分词器)上的结果证实了所提方法在从异构 rollout 中提取可迁移知识方面的鲁棒性和泛化能力。