Command Palette
Search for a command to run...
Proact-VL:面向实时 AI 伴侣的主动式 VideoLLM
Proact-VL:面向实时 AI 伴侣的主动式 VideoLLM
Weicai Yan Yuhong Dai Qi Ran Haodong Li Wang Lin Hao Liao Xing Xie Tao Jin Jianxun Lian
摘要
主动且实时的交互体验对于拟人化人工智能(AI)伴侣至关重要,但其实现仍面临三大关键挑战:(1)在连续流式输入条件下实现低延迟推理;(2)自主决策响应时机;(3)在满足实时性约束的同时,有效控制生成内容的质量与数量。本文通过两种具有代表性的游戏场景——解说员与游戏向导——构建 AI 伴侣原型,并因其便于自动化评估而被选为研究载体。我们提出了“实时游戏基准”(Live Gaming Benchmark),这是一个涵盖三种典型场景的大规模数据集,包括单人解说、联合解说以及用户引导。在此基础上,我们进一步提出了 Proact-VL 框架,该通用框架能够将多模态语言模型转化为具备主动性与实时交互能力的智能体,使其能够模拟人类对环境进行感知与交互。大量实验结果表明,Proact-VL 在响应延迟与生成质量方面均表现优异,同时保持了强大的视频理解能力,充分证明了其在实时交互应用中的实用价值。
一句话总结
Yan、Dai 及来自多所机构的同事介绍了 Proact-VL,这是一个将多模态模型转化为实时游戏解说与指导的主动智能体框架。通过解决延迟和自主响应时机等挑战,该方法在新型“实时游戏基准”(Live Gaming Benchmark)中超越了以往的方法,实现了类人的交互式 AI 伴侣。
主要贡献
- 针对连续流输入中低延迟推理和自主响应时机的挑战,作者引入了“实时游戏基准”(Live Gaming Benchmark),这是一个涵盖单人解说、双人解说和用户指导场景的大规模数据集。
- 本文提出了 Proact-VL,这是一个通用框架,通过将分块输入输出模式与轻量级自主响应决策机制相结合,将多模态语言模型塑造为主动智能体。
- 大量实验表明,Proact-VL 在保持强大视频理解能力的同时,实现了更优的响应延迟和质量,在 TimeDiff 和 F1 等指标上超越了现有方法。
引言
为实时视频流创建类人 AI 伴侣,需要在低延迟推理与自主决定何时说话及说话多少的能力之间取得平衡。以往的方法难以实现这种平衡:主动模型往往生成冗长的回复且延迟较高,而实时系统则缺乏对说话行为的控制,导致要么喋喋不休,要么出现破坏性的沉默。为了解决这些问题,作者提出了 Proact-VL,该框架结合了分块视频处理、用于自主响应时机的轻量级机制以及用于稳定训练的多层级损失函数。该系统使 AI 智能体能够在游戏场景中提供简短、连续且具备上下文意识的解说,同时保持强大的视频理解能力。
数据集
实时游戏数据集概览
作者精心策划了一个专门的多模态数据集,旨在训练用于实时游戏解说和指导的主动 AI 伴侣。
-
数据集构成与来源 核心集合包含 561 小时的高质量英文解说视频,涵盖 12 款不同流派的热门游戏大作。作者从 YouTube 获取这些数据,优先选择专业锦标赛转播和专家网红频道,以确保高叙事密度和语言连贯性。所有视频均以 420p 分辨率存档,以在视觉保真度与流媒体效率之间取得平衡。
-
各子集的关键细节
- 训练集: 涵盖 10 款特定游戏(包括《赛博朋克 2077》、《英雄联盟》和《我的世界》),并整合了两个通用流媒体数据集(LiveCC 和 Ego4D),总计 128,000 个样本。
- 实时游戏基准(Live Gaming Benchmark): 一个包含 3,014 个样本的片段级测试套件。其中包括来自 10 款游戏的 2,640 个片段的域内子集,以及来自 Ego4D 的 134 个样本和来自域外游戏的 240 个片段的通用子集。
- 实时游戏基准 - 流媒体(Live Gaming Benchmark-Streaming): 一个长程评估集,包含 10 个从单人解说和双人解说场景中精选的完整视频(时长从 30 分钟到 2 小时不等)。
-
数据使用与划分策略 作者对 10 款训练游戏采用视频级划分,将 80% 的视频用于训练,10% 用于测试,并预留 10% 供未来使用。在训练过程中,视频被分割为 36 秒的片段,重叠 18 秒,而《我的世界》数据还包含 60 秒的变体。基准子集按响应率(0–30%、30–70% 和 70–100%)进行分层,以确保评估场景的多样性。
-
处理与元数据构建
- 语音处理: 流程使用 WhisperX-large-v3 进行自动语音识别和说话人识别,随后通过基于频率的滤波器去除背景音乐等非人声。
- 细化与标注: Qwen3-Omni-Flash 用于标注副语言细微差别(如停顿和笑声),而 DeepSeek-V3.2-Exp 则用于润色转录文本,修正特定领域术语并过滤不当内容。
- 时间对齐: 为了实现每秒级别的监督,作者通过将单词均匀分布到时间桶中,并在表示持续话语的末尾添加省略号后缀,将片段级字幕转换为秒级序列。
- 提示工程: 在训练期间,系统提示被随机化,以包含特定游戏角色、挖掘出的角色设定,以及针对单人解说、双人解说或指导场景的任务模板。
方法
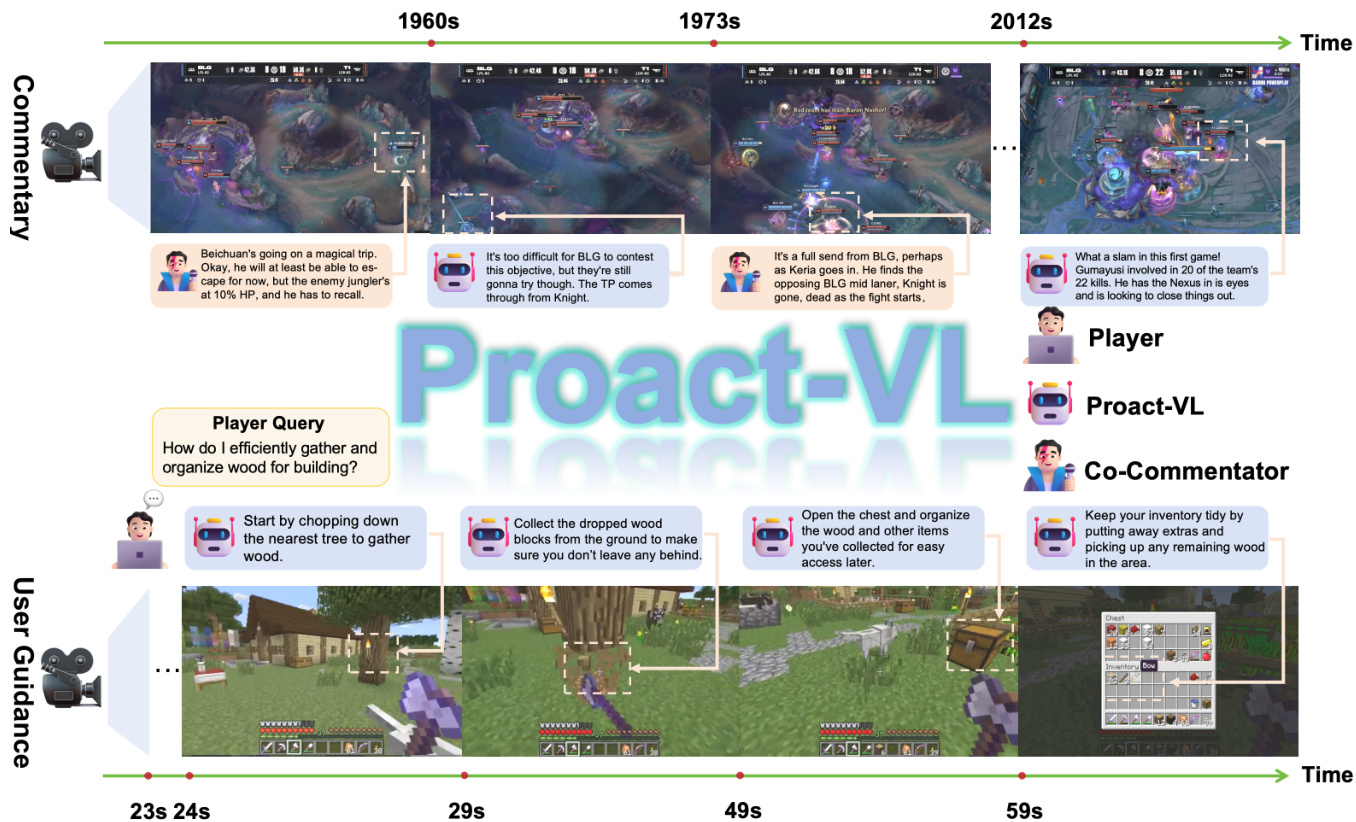
Proact-VL 框架旨在促进实时视频理解与交互,覆盖两个主要游戏领域:实时解说和主动用户指导。如概览图所示,该系统支持从竞技电竞分析到沙盒环境中的教学辅助等多种场景。
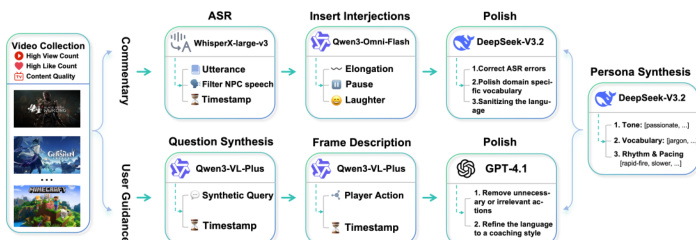
为了实现这种多功能性,作者采用了一套综合的数据合成流程。该过程始于视频收集,随后进行特定领域的处理。对于解说领域,自动语音识别(ASR)提取转录文本,随后通过插入感叹词并进行润色以匹配特定解说员的人设。相反,对于用户指导领域,系统合成潜在的玩家查询并生成细粒度的帧描述。这些描述由大型语言模型进行细化,以生成简洁、以行动为导向的指导指令。
核心架构采用分块处理方法来高效处理流式视频输入。在每个时间步 t,模型接收一个三元组输入:视觉内容 Vt、可选的用户查询 Qt 和环境上下文 Bt。这种结构使系统能够在处理连续流的同时保持时间感知能力。输入被序列化为 ChatML 风格的格式,使用特殊标记明确区分历史、视频片段和查询。
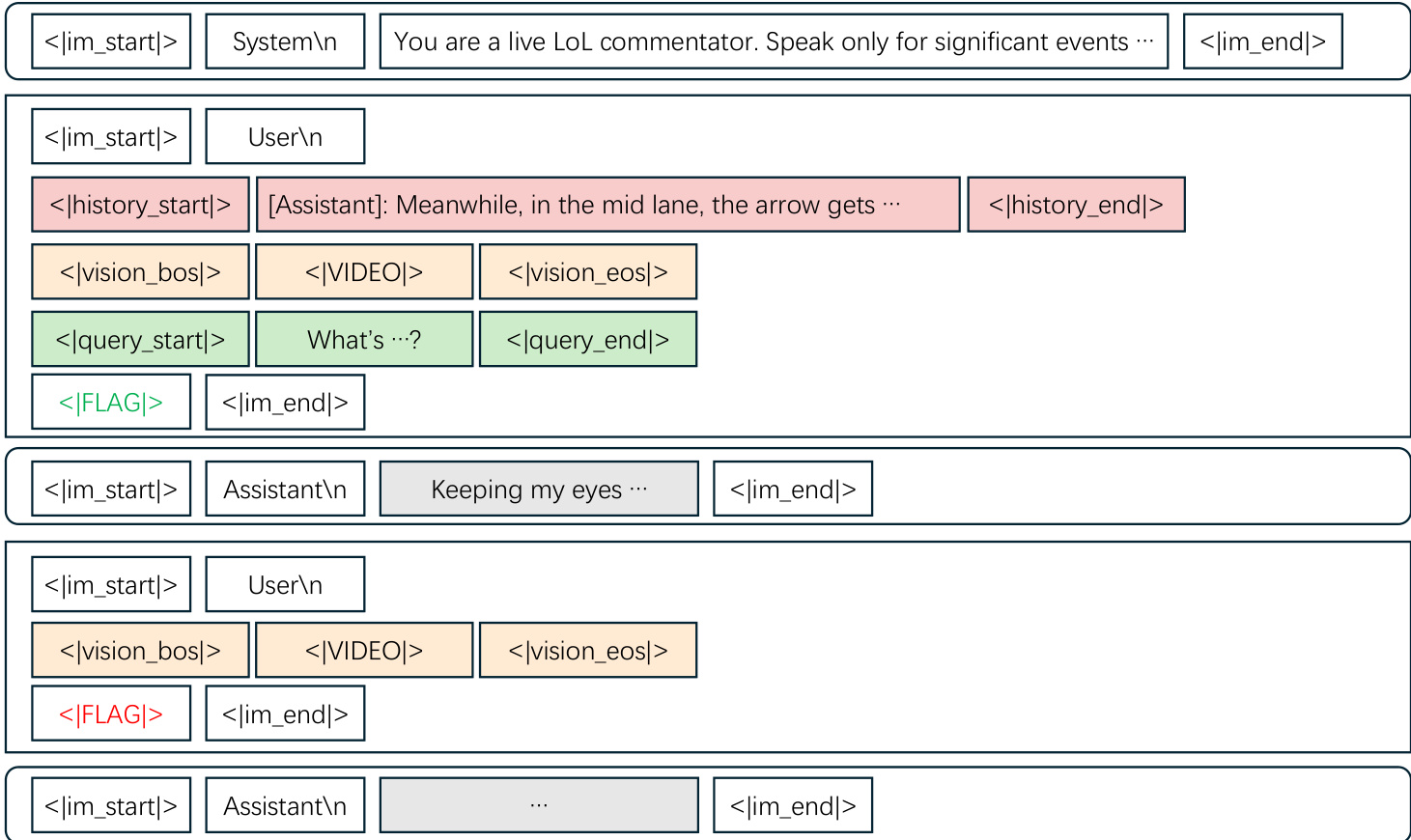
一项关键创新是主动响应机制,它使模型能够自主决定何时说话。系统不再等待明确的提示,而是在每条用户消息的末尾插入一个特殊的决策标记 <|FLAG|>。与该标记对应的隐藏状态被输入到一个轻量级响应头中,以计算说话概率。
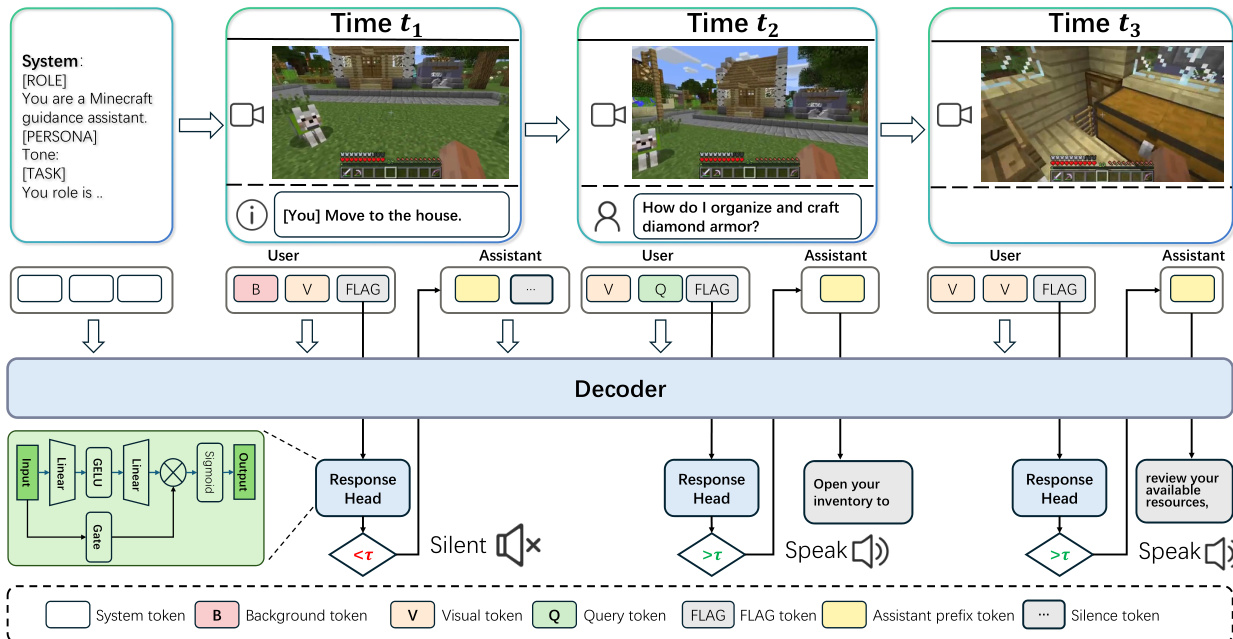
该决策形式化为 pt=σ(MLP(ht)),其中 ht 是隐藏状态。通过将 pt 与阈值 τ 进行比较来做出二元决策。如果触发,模型生成一个解说片段;否则,输出一个静音标记。这种设计实现了一个两阶段推理流程:模型首先决定是否响应,仅在需要时才生成解说片段。
模型通过结合目标函数进行优化,以平衡话语质量和说话行为。主要损失函数监督文本生成,而次要响应损失函数则控制解说的时机。该响应损失包括一个用于处理状态变化的过渡平滑分类组件,以及一个用于确保稳定说话率的正则化项。对于长时流媒体,系统采用双缓存滑动窗口机制,在将旧标记驱逐以保持在内存限制内的同时,维持持久的上下文。
实验
- 实时游戏解说实验表明,与商业及以往的实时基线相比,该模型在文本质量和主动时机方面表现更优,有效地在单人、双人解说和指导场景中平衡了参与度与准确性。
- 在通用和一般解说集上的评估证实了强大的域外泛化能力,模型在未见过的游戏和第一人称视频流中保持了高连贯性和可靠的事件触发能力。
- 长视频流测试显示,该模型在长推理范围内保持了稳定的文本质量和响应行为,证明了其在连续直播中的鲁棒性。
- 消融研究验证了所提出的训练损失是互补的,对于精确的响应时机至关重要;而数据混合分析表明,结合游戏、通用和直播源数据可最大化领域适应性。
- 对推理效率和触发阈值的深入分析表明,该模型具有稳定的低延迟特征,并在响应覆盖率和一致性之间存在清晰的权衡;案例研究突出了模型采用特定人设和处理复杂多说话人动态的能力。