Command Palette
Search for a command to run...
利用学习进阶指导科学学习中的 AI 反馈
利用学习进阶指导科学学习中的 AI 反馈
Xin Xia Nejla Yuruk Yun Wang Xiaoming Zhai
摘要
生成式人工智能(AI)能够为形成性评价反馈提供可扩展的支持,然而,目前大多数由 AI 生成的反馈仍依赖于领域专家撰写的特定任务评分量表。尽管此类方法效果显著,但量表的编制耗时费力,且难以在不同教学场景中实现广泛推广。学习进阶(Learning Progressions, LPs)提供了一种基于理论框架的学生理解发展表征,或可成为解决上述局限的替代方案。本研究旨在探讨一种基于学习进阶的评分量表生成流程,是否能够生成与基于专家撰写任务量表所引导的 AI 反馈具有同等质量的反馈效果。研究选取了 207 名中学生撰写的化学科学解释文本,对其由 AI 生成的反馈进行了分析。研究比较了两种生成路径:(a)由人类专家设计、针对特定任务的评分量表所引导的反馈;(b)在评分及反馈生成之前,基于学习进阶自动推导出的特定任务评分量表所引导的反馈。两名人类编码员采用多维度评分量表对反馈质量进行了评估,该量表涵盖清晰度(Clarity)、准确性(Accuracy)、相关性(Relevance)、参与度与激励性(Engagement and Motivation)以及反思性(Reflectiveness)五个维度(共包含 10 个子维度)。评估显示,编码员间的一致性较高,百分比一致率在 89% 至 100% 之间,可估算维度的 Cohen's κ系数范围为 0.66 至 0.88。配对样本 t 检验结果显示,在上述各维度上,两种生成路径之间均未发现统计学意义上的显著差异:清晰度(t₁ = 0.00, p₁ = 1.000;t₂ = 0.84, p₂ = 0.399)、相关性(t₁ = 0.28, p₁ = 0.782;t₂ = -0.58, p₂ = 0.565)、参与度与激励性(t₁ = 0.50, p₁ = 0.618;t₂ = -0.58, p₂ = 0.565)以及反思性(t = -0.45, p = 0.656)。上述发现表明,基于学习进阶的评分量表生成流程可作为专家撰写任务量表的可行替代方案。
一句话总结
佐治亚大学和加齐大学的研究人员提出了一种基于学习进程(LP)驱动的评分标准流程,该流程生成的针对初中化学解释的AI反馈效果与专家编写的评分标准相当,从而实现了无需任务特定人工评分标准设计的、理论支撑的可扩展形成性评估。
主要贡献
- 本研究通过用从学习进程自动推导出的评分标准替代耗时费力的专家编写评分标准,解决了AI生成反馈中的可扩展性瓶颈问题。学习进程映射了学生在科学概念上的发展路径。
- 该研究引入了一种基于LP的流程,用于生成针对初中化学解释的反馈,并通过人工编码员对207名学生回答的评估,从五个维度比较其质量与专家评分标准引导反馈的质量。
- 在清晰性、相关性、参与度与动机、反思性等维度上,两种反馈流程之间未发现统计学上的显著差异,表明基于LP的评分标准可作为专家设计评分标准的一种可行且可扩展的替代方案。
引言
作者利用学习进程(LPs)——一种基于实证的学生理解发展模型——自动生成针对科学教育中具体任务的评分标准,以提供AI反馈。这解决了当前AI反馈系统的一个关键瓶颈:这些系统依赖耗时且需专家编写的评分标准,限制了其在多样化课堂任务中的可扩展性。尽管先前研究表明,在详细评分标准指导下,AI可以生成有用的反馈,但为每个新任务构建此类评分标准并不现实。作者证明,基于LP的评分标准生成的AI反馈,在清晰性、相关性和反思性等维度上,其质量在统计上与专家编写的评分标准无异——表明LP可作为可复用的教学基础,自动创建评分标准,实现高质量反馈的大规模扩展。

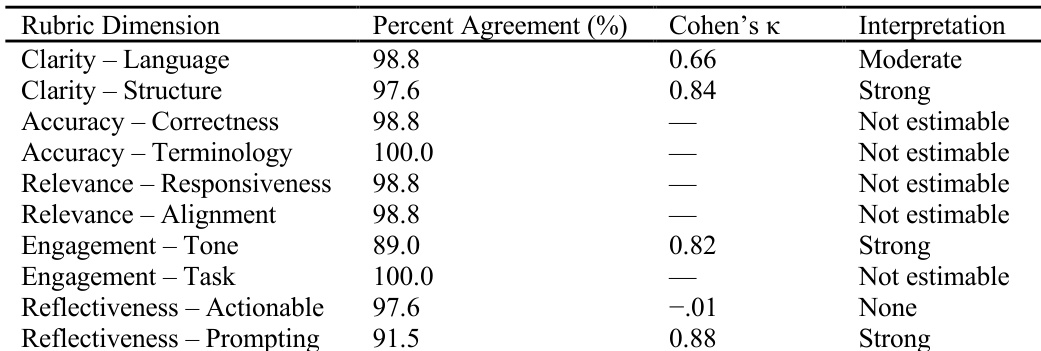
数据集
-
作者从一个包含1200份响应的更大池中随机抽取了207份匿名初中生回答,这些回答通过符合NGSS的在线评估系统收集。由于匿名化,未提供人口统计信息,但样本反映了广泛的美国地理分布。
-
所有回答均来自一个聚焦气体性质的开放式化学任务,该任务源自下一代科学评估任务集。学生分析四种气体样本在可燃性、体积和密度方面的数据,并解释哪些气体可能是相同的,同时用证据支持其推理。
-
该任务旨在评估科学解释能力——特别是使用适当术语将证据与主张联系起来——并作为评估AI生成形成性反馈的唯一情境。
-
反馈评估聚焦于五个维度:清晰性、准确性、相关性、参与度与动机、反思性。该数据集专门用于测试不同AI反馈流程对学生解释的响应方式,并比较这些维度上的反馈质量。
方法
作者使用统一的大型语言模型——GPT-5.1——在两个评估流程中生成反馈,确保方法一致性。对于每个学生回答,模型被提示执行两个核心任务:首先,根据指定评分标准评估该回答;其次,生成与评估结果直接一致的形成性反馈。反馈有意设计为发展适宜、语气支持性强,并聚焦于引导学生提升科学解释能力。
为了隔离评分标准来源对反馈质量的影响,两个流程采用相同的提示策略和输出约束。唯一引入的变量是评分标准的来源——要么是人工编写,要么源自学习进程框架。这种受控设计使我们能够直接比较评分标准来源如何影响生成反馈的质量和实用性。
如下图所示:
实验
- 充气气球实验在受控条件下验证了气体性质的测量,重点关注可燃性、体积、质量和密度。
- 使用被试内设计比较了两种AI反馈流程(专家评分标准与学习进程),两者在所有维度上均产生高质量反馈。
- 通过五维评分标准(清晰性、准确性、相关性、参与度、反思性)评估反馈质量;两种流程在所有维度上得分均接近上限,科学内容完全准确。
- 在任何反馈维度上,两种流程之间均未发现统计学显著差异,表明其效果等效。
- 反思性提示得分略低且更具变异性,表明在鼓励学生反思方面仍有改进空间。
- 结果证实,结构化、任务对齐的AI反馈可大规模可靠地提供科学准确、清晰且激励性的指导。
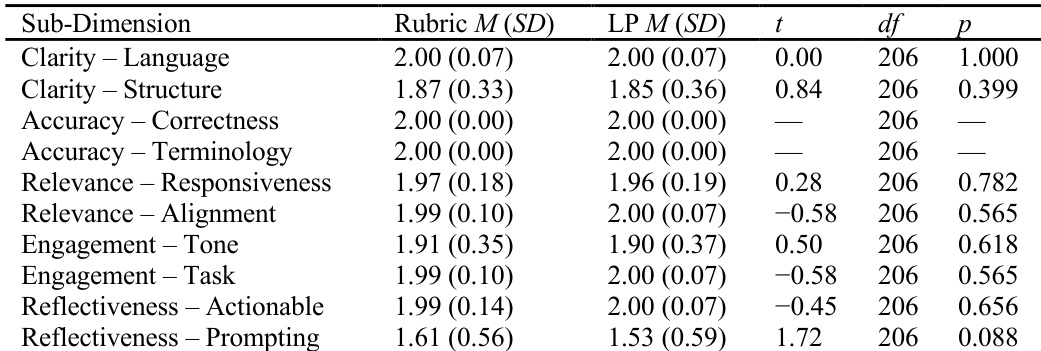
作者使用多维评分标准评估AI生成反馈的五个质量维度,人工编码员在大多数维度上达成高百分比一致性及中等至强的评分者间信度。结果表明,专家评分标准和学习进程流程均持续产生高质量反馈,在任何可评估的子维度上均无统计学显著差异。反馈在准确性、清晰性、相关性和吸引力方面表现一致,但反思性提示在质量上表现出更大的变异性。
作者比较了两种AI反馈流程——一种使用专家设计的评分标准,另一种使用基于学习进程的准则——发现在任何评估维度上,反馈质量均无统计学显著差异。在受控条件下,两种方法均持续产生高质量、科学准确且教学合理的反馈。结果表明,无论是使用专家准则还是基于进展的准则构建AI反馈,均可为学生支持带来同样有效的结果。
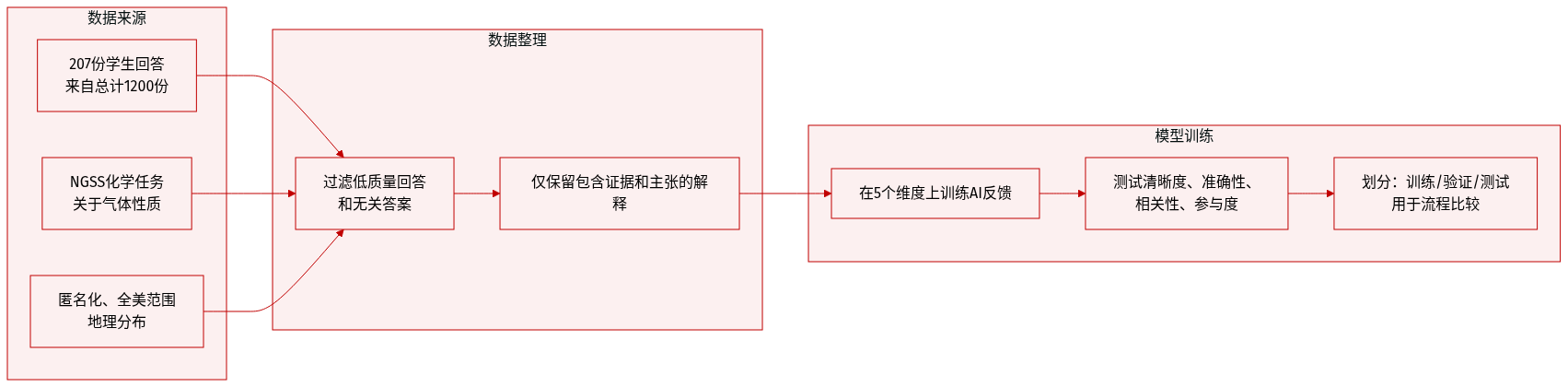
作者通过受控实验比较了四种气体样本的性质,在相同条件下测量可燃性、密度和体积。结果表明,可燃性与密度或体积无相关性,因为可燃与不可燃气体均出现在测量值的整个范围内。数据表明,必须独立评估这些物理性质,才能准确表征每种气体。