Command Palette
Search for a command to run...
RubricBench:使模型生成的评分标准与人类标准对齐
RubricBench:使模型生成的评分标准与人类标准对齐
摘要
随着大语言模型(LLM)对齐技术从简单的文本补全演进至复杂且高度精细的生成任务,奖励模型(Reward Models)正日益转向基于评分量表(rubric-guided)的评估方式,以缓解表面层面的偏差问题。然而,当前社区尚缺乏统一的基准来评估这一评估范式,因为现有基准在判别复杂性以及真实评分量表标注(ground-truth rubric annotations)方面均存在不足,难以支撑严谨的分析。为弥补这一空白,我们提出了RubricBench——一个精心构建的基准,包含1,147组成对比较样本,专为评估基于评分量表的评估方法的可靠性而设计。该基准的构建采用多维度筛选流程,聚焦于具有细微输入复杂性与误导性表面偏差的高难度样本,并为每条样本配备由专家标注的、原子级的评分量表,其内容严格源自原始指令。全面实验结果表明,人工标注的评分量表与模型自动生成的评分量表之间存在显著能力差距,表明即便是最先进的模型,在自主指定有效评估标准方面仍面临困难,其表现远落后于人类引导下的评估水平。
一句话总结
香港城市大学、腾讯、麦吉尔大学-Mila 和伊利诺伊大学斯普林菲尔德分校的研究人员提出了 RubricBench,这是一个包含 1,147 个专家标注的成对比较的基准测试,用于评估基于评分标准引导的大型语言模型对齐能力,揭示了人类与模型生成的评分标准在处理细微、有偏见输入时的关键差距。
主要贡献
- RubricBench 引入了首个统一基准测试,包含 1,147 个专家标注的成对比较,旨在评估基于评分标准引导的奖励模型,解决了现有数据集中缺乏区分性复杂度和真实评分标准标注的问题。
- 该基准采用多维过滤流程,聚焦于具有复杂输入和误导性表面偏差的困难样本,并结合严格从指令中导出的原子评分标准,以实现对评分标准质量和偏好准确性的严格评估。
- 实验显示,人类标注与模型生成的评分标准之间存在 27% 的准确率差距,表明即使最先进的模型也无法自主指定有效的评估标准,凸显认知错位是评分标准引导奖励建模的核心瓶颈。
引言
作者利用评分标准引导的评估方法,解决随着大型语言模型输出日益复杂化,奖励模型与用户意图之间日益扩大的错位问题。以往的奖励模型往往偏爱表面特征(如冗长或格式),而非实际任务完成度;虽然生成式奖励模型试图通过思维链(Chain-of-Thought)合理化判断,但缺乏可验证约束的支撑。现有基准测试因样本过时、缺乏区分难度及缺少人类标注评分标准作为真实基准,无法严格测试基于评分标准的评估。作者的主要贡献是 RubricBench,一个包含 1,147 个具有挑战性的成对比较的精选基准测试,配备专家标注、指令导出的评分标准。实验表明,人类与模型生成评分标准之间存在显著的 27% 性能差距,揭示当前模型难以自主定义有效的评估标准——这是实现可信对齐必须解决的瓶颈。
数据集

-
作者使用 RubricBench,该基准包含 1,147 个成对比较,每个比较配有一个仅从指令中导出的专家标注评分标准,以避免响应感知泄露。评分标准结构为原子二元检查(是/否),以便进行细粒度诊断。
-
数据来源于现有高质量基准:HelpSteer3、PPE 和 RewardBench2。这些数据经过筛选,移除“简单”配对,仅保留能暴露模型评估失败的区分性示例。
-
该基准涵盖五个领域:聊天(36.5%)、编程(23.9%)、STEM 推理(23.8%)、指令遵循(8.8%)和安全(7.0%)。大多数示例包含 4–6 个评分标准项,评分标准保持简洁——长度与指令相当,而非响应。
-
过滤在三个维度上进行:
• 输入复杂度:保留包含明确和隐含多部分要求的指令(如“向祖父母解释区块链”隐含避免术语)。
• 输出表面偏差:保留被拒绝的响应通过长度(≥1.5 倍)、格式(如 Markdown/JSON)或语气(过度自信语言)误导的配对。
• 过程错误:使用判断模型识别推理错误(幻觉、逻辑漏洞、约束侵蚀),需通过 CoT 检查。 -
标注由 9 位专家标注员完成——领域从业者和计算机科学博士生,具备深厚的 NLP 评估经验,确保准确捕捉技术和隐含约束。
-
该基准不用于训练;它旨在评估奖励模型(RMs),测试其对齐人类导出、基于指令的评分标准的能力,而非表面或最终答案线索。
方法
作者采用三阶段流程构建和验证与指令对齐的评分标准,以评估模型响应。该框架从源池整理开始,经过人类标注原子评分标准项,最后通过多层质量控制确保结构完整性和语义客观性。
第一阶段:整理。系统摄入来自不同领域(聊天、指令遵循、编程、STEM 和安全)的指令,并应用多维过滤评估输入复杂度、输出偏差和过程有效性。例如,指令“你能帮我写一封 10 天通知邮件给我的老板,他的名字是 Walt?我辞职的公司是‘Common Market’”将评估其多约束合规性、事实依据和无幻觉推理步骤。此阶段确保仅结构良好、可评估的指令进入标注。
请参考框架图,了解此整理逻辑及其对评分标准生成的下游影响的可视化映射。
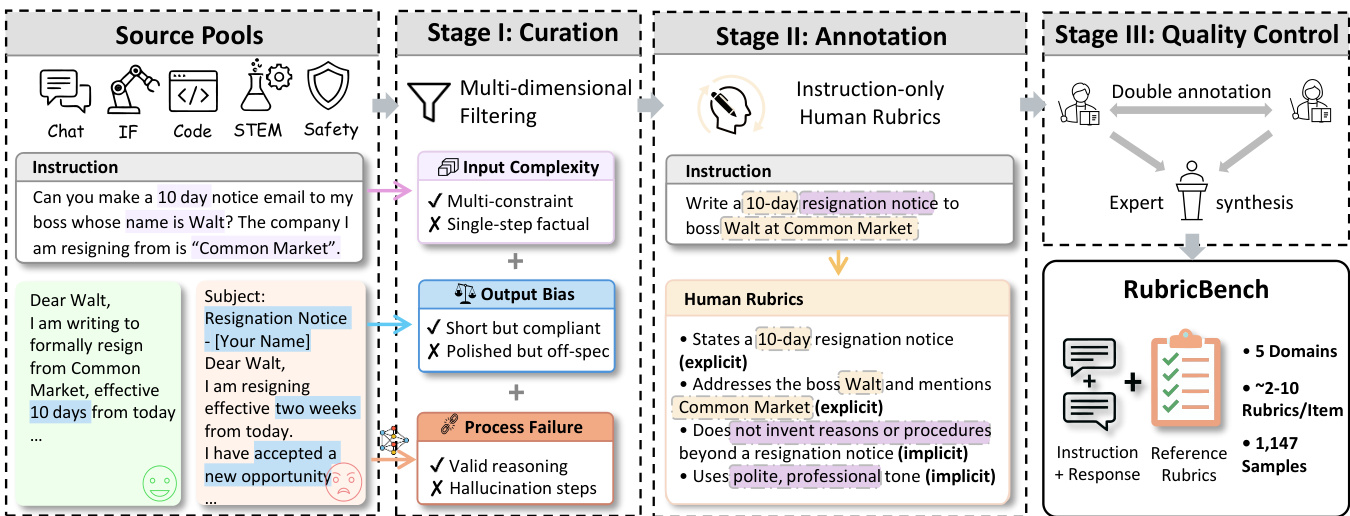
第二阶段:标注聚焦于生成仅基于指令的人类评分标准。标注员直接从指令中导出二元(是/否)标准,不接触候选响应,以防止事后偏见。每个评分标准项必须映射到五个领域之一:推理、内容、表达、对齐或安全。对于辞职邮件示例,评分标准项包括明确约束如“声明 10 天辞职通知”和隐含约束如“使用礼貌、专业语气”。协议强制结构原子性——每个评分标准包含 2–10 项,每项表述为单一、可验证的约束——以便独立评估。
第三阶段:质量控制实施三层验证协议。首先,专家协调将双标注评分标准合成为共识版本,移除主观或非必要项。其次,结构验证检查逻辑一致性、最小冗余和严格指令对齐。第三,压力测试使用保留的模型响应验证评分标准,特别是在安全和推理任务上,确保跨质量水平的区分能力。最终输出 RubricBench 包含约 1,147 个指令-响应对,每样本 2–10 个评分标准项,标准化为原子清单以便跨源比较。
标准化过程将人类和模型生成的评分标准转换为原子项的扁平集合:
R={r1,…,rM},R~={r~1,…,r~K}.这使精确的结构对齐度量成为可能,并通过 Qwen3-30B-A3B(temperature = 0.0)的确定性解码实现自动化评估。此外,部署元评估提示,以 1–5 分尺度评分每条评分标准规则的意图必要性(N),衡量该规则对用户明确或隐含意图的重要性——确保评分标准基于任务需求而非评估者解释。
实验
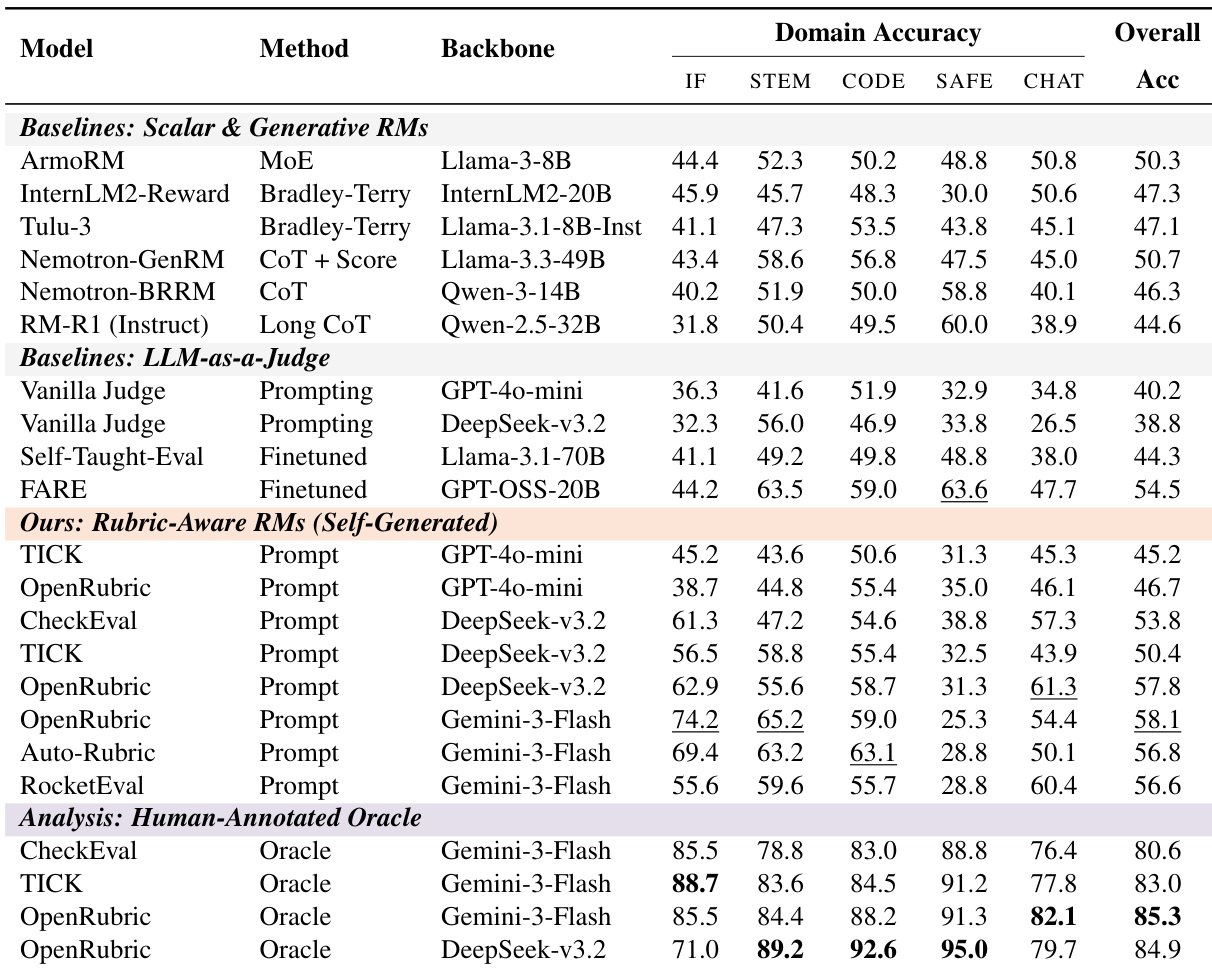
- 自动化判断器在 RubricBench 上表现出清晰的性能层级,确认该基准可区分评估器质量。
- 无明确评分标准时,即使强模型性能也接近随机水平,表明其缺乏推断细粒度评估标准的内在能力。
- 引入自生成评分标准可适度提升性能,但存在巨大且持续的“评分标准差距”——人类标注评分标准在所有模型上均持续提升约 26% 的准确率。
- 该差距不会因增加测试时计算量、更多采样评分标准或更深层优化而缩小,证明其源于评分标准误指定,而非推理或扩展限制。
- 模型生成的评分标准与人类优先级不一致:产生无关或过度僵化的规则,遗漏关键约束,注意力分配错误,导致判断倒置。
- 即使使用完美的人类评分标准,性能仍稳定在约 85%,揭示模型在最终决策中忽略或误权绑定约束的持续执行错误。
- 安全关键任务尤其脆弱:自生成评分标准常忽略拒绝逻辑,而人类评分标准可恢复近乎完美的执行。
- 人类评估者在有缺陷的评分标准下表现也差,确认评分标准质量——而非评估者能力——是主导瓶颈。
- 未来进展需对齐评分标准内容与人类价值观和优先级,而非仅扩展生成或优化。
作者通过受控实验隔离评分标准质量对自动判断器性能的影响,比较多种模型上的基础提示、自生成评分标准和人类标注评分标准。结果表明,尽管自生成评分标准比基线方法提升准确率,但与人类撰写的评分标准相比仍存在持续且显著的性能差距——表明评分标准误指定,而非推理能力,是主要瓶颈。该差距在不同模型规模下持续存在,且无法通过增加测试时计算量消除,确认当前模型系统性地无法自主推导有效评估标准。
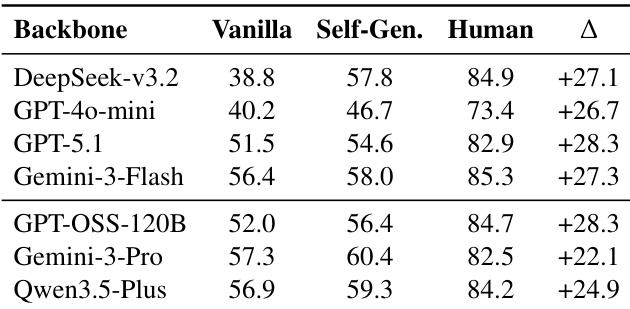
作者评估了多种评分标准生成方法,发现即使模型生成冗长清单,也常未能捕捉人类定义的关键约束,导致高幻觉率和低结构对齐度。CheckEval 实现最高评分标准召回率,表明引入最小人类先验可提升生成标准的有效性。总体而言,结果突显模型生成与人类标注评分标准之间持续的错位,指向评分标准形成——而非推理能力——是自动化评估的主要瓶颈。
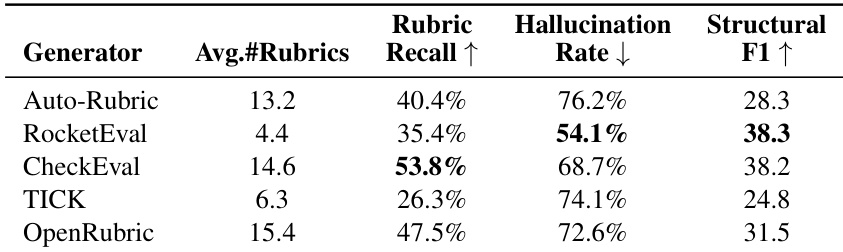
结果表明,即使人类评估者在受限于模型生成评分标准时,准确率也会显著下降,确认评分标准质量——而非评估者能力——是主要瓶颈。该性能差距在人类和模型判断器中均持续存在,强化了误指定评分标准会系统性降低评估可靠性,无论评估者的推理能力如何。

作者使用结构特征分析比较人类撰写和 LLM 生成的评分标准,发现模型生成更僵化且必要性更低的标准,导致评估优先级错位。结果表明,LLM 评分标准包含更高比例的过度严格且缺乏任务相关性的规则,削弱了约束刚性与意图必要性之间的相关性,相较于人类评分标准。这种错位导致判断失败,即使模型生成更长的评分标准集,也表明在价值和约束优先级上存在根本差距。

作者使用 RubricBench 隔离评分标准质量如何影响自动判断器性能,发现自生成评分标准在所有模型家族中始终表现低于人类标注评分标准。结果表明,即使使用相同骨干和验证步骤,注入人类评分标准可提升约 26% 的准确率,揭示评分标准误指定——而非推理能力——是主导瓶颈。该差距无论测试时计算扩展如何均持续存在,确认当前模型尽管在提供时能执行必要评估标准,却无法自主推导。