Command Palette
Search for a command to run...
CiteAudit:你引用了它,但你读过吗?面向大语言模型时代的科学引用验证基准
CiteAudit:你引用了它,但你读过吗?面向大语言模型时代的科学引用验证基准
Zhengqing Yuan Kaiwen Shi Zheyuan Zhang Lichao Sun Nitesh V. Chawla Yanfang Ye
摘要
科学研究依赖于准确的引用以实现归属认定与学术诚信,然而大型语言模型(LLMs)的兴起带来了一种新型风险:生成看似合理但实际上对应于不存在的学术文献的虚假引用。此类“幻觉式”引用已在顶级机器学习会议的投稿及已接收论文中被观察到,暴露出同行评审机制的脆弱性。与此同时,参考文献数量的迅速增长使得人工核查变得不切实际,而现有的自动化工具在面对噪声大、格式多样的引用数据时仍显脆弱,且缺乏统一的评估标准。为此,我们提出了首个针对科学写作中虚假引用的综合性基准测试与检测框架。我们的多智能体验证流程将引用核查分解为五大步骤:论断提取、证据检索、段落匹配、推理判断以及校准后的最终评估,用以判断被引用的文献是否真正支持其声称的论点。我们构建了一个跨多个领域的大规模人工验证数据集,并定义了统一的指标体系,用于衡量引用的忠实性(citation faithfulness)与证据的一致性(evidence alignment)。基于前沿大模型的实验结果表明,当前主流模型存在显著的引用错误。我们的框架在准确率与可解释性方面均显著优于现有方法。本研究首次建立了适用于大语言模型时代的可扩展引用审计基础设施,为提升科学引用的可信度提供了切实可行的技术工具与评估体系。
一句话总结
来自圣母大学和理海大学的研究人员构建了首个用于检测科学写作中大模型“虚构引用”的大规模基准与多智能体验证框架,实现了对引用真实性的可扩展、可解释审计。
主要贡献
- 研究人员引入了首个大规模、人工验证的幻觉引用检测基准,涵盖多个领域和引用类型,并采用标准化评估协议,以支持可复现的引用保真度研究。
- 研究人员提出了一种多智能体验证框架,将引用检查分解为协调的阶段——主张提取、证据检索、段落匹配、上下文推理和校准判断——以稳健处理嘈杂、真实世界的引用格式。
- 在最先进的大语言模型上的实验揭示了广泛的引用错误,该框架在检测准确性和可解释性方面显著优于现有基线,为审稿人和出版商提供了可扩展的工具。
引言
作者利用大语言模型在科学写作中的兴起,应对日益增长的威胁:幻觉引用——看似合理但实际不存在的参考文献,破坏研究完整性。现有自动化工具难以处理真实世界引用中的噪声,且缺乏标准化基准,而人工验证已无法在大规模上实现。他们的主要贡献是一种多智能体验证框架,将引用检查分解为专门阶段——主张提取、证据检索、匹配、推理和判断——并配以首个大规模、人工验证的基准,涵盖多种引用类型和领域。该系统在准确性和可解释性方面优于现有基线,为研究人员和出版商提供实用、可扩展的基础设施,以审计引用并恢复对学术参考的信任。
数据集

作者使用CiteAudit,一个用于检测引用幻觉的基准,由两个主要部分组成:真实引用和人工合成的幻觉引用。以下是数据集的构建和使用方式:
-
来源与组成:
- 真实引用来自OpenReview和Google Scholar,手动对照权威记录(标题、作者、会议、年份、DOI)验证。
- 幻觉引用由已验证的BibTeX条目通过受控扰动生成,扰动依据幻觉类型分类(标题、作者、元数据错误)。
-
关键子集详情:
- 真实世界集:高质量、自然发生的错误(例如错误作者、会议、不存在的论文),手动验证但受限于劳动强度。
- 生成集(2,500个实例):
- 标题错误(1,000个):通过关键词替换、改写或GPT-4o-mini主题条件合成生成。
- 作者错误(1,000个):通过添加/删除作者、姓名交换或完全虚构生成。
- 元数据错误(500个):会议不匹配、年份偏移或伪造DOI。
- 复合幻觉(多个字段错误)始终标记为幻觉。
-
处理与标注:
- 所有引用均经过自动网络检索,随后由作者团队手动交叉检查。
- 标注严格:仅核心元数据(标题、作者、会议、年份、DOI)必须与权威来源匹配;忽略次要格式问题。
- 每个引用至少由两名作者审查;未解决的案例被排除。随机子集进行一致性审计。
-
数据集在评估中的使用:
- 生成测试集(共5,000个:2,500个真实 + 2,500个幻觉)在错误类型上平衡,以实现公平、细粒度的模型评估。
- 生成的幻觉经过验证,匹配真实世界错误分布(卡方检验:p ≈ 0.97)。
- 不使用自动化或众包标注——所有标注均由作者验证以确保高置信度。
该设计支持在自然发生和系统扰动的幻觉场景下,对引用验证系统进行可复现、受控的评估。
方法
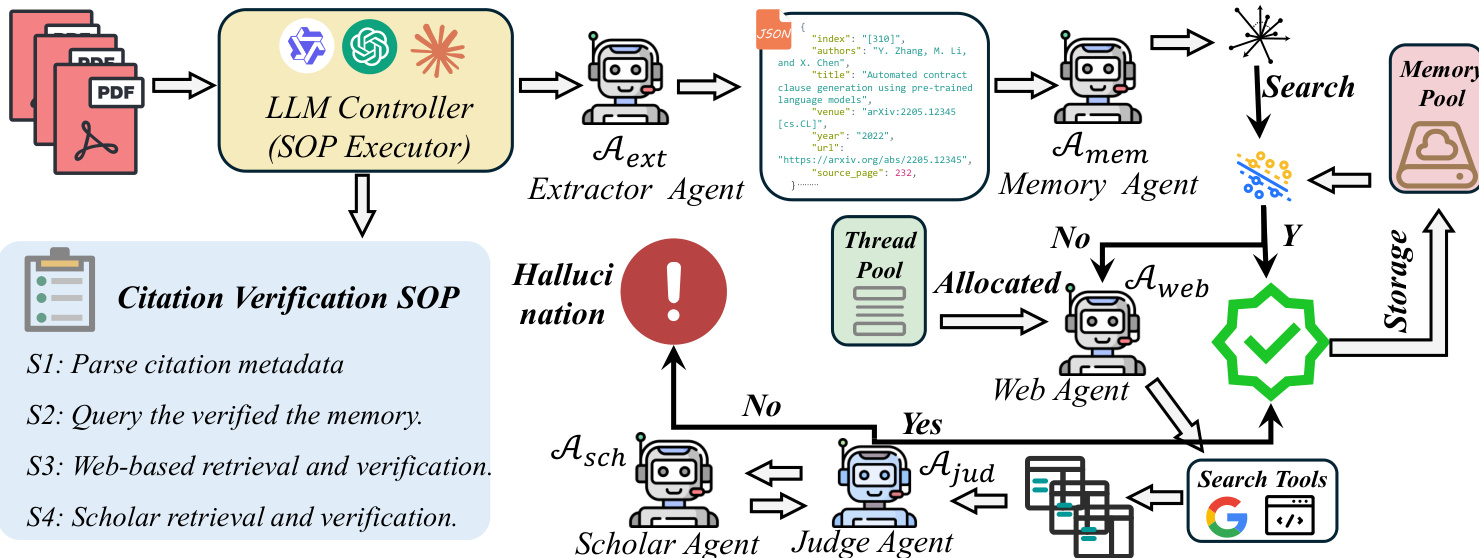
作者利用由分层标准操作程序(SOP)管理的去中心化多智能体框架,系统审计学术引用的存在性和元数据完整性。系统将引用验证视为一个多阶段证据验证问题,其中每个引用 ri 根据其结构化元数据元组 Mi={mT,mA,mU,mV}(代表标题、作者、URL和会议)定义的严格一致性标准 Sc 进行评估。如果全局学术图 Gscholar 中不存在对应条目或 Sc=0,则引用被分类为伪造,其中 Sc 通过提取字段与真实字段在字符级别精确匹配的指示函数乘积计算:
Sc=k∈{T,A,U,V}∏I(mk=m^k)该框架由作为SOP执行器的LLM控制器协调,将验证任务分解为基于预定义阶段(S1–S4)的顺序和可并行图。管道始于提取智能体(Aext),该智能体使用视觉集成OCR工具摄取原始PDF,并将非结构化引用字符串映射为不可变的JSON元数据,保留原始作者意图而不扭曲语义。此结构化输出作为所有下游验证的基础。
请参阅框架图以可视化智能体交互和决策流程。记忆智能体(Amem)随后对双端知识库 K 执行高速语义查找,通过引用与存储记录嵌入之间的余弦相似度计算置信度分数 smem:
smem(Mi)=k∈Kmax(∣∣Enc(Mi)∣∣⋅∣∣Enc(k)∣∣Enc(Mi)⋅Enc(k))如果 smem>τ(其中 τ=0.92),引用通过“快速路径”立即验证并存储在记忆池中以供将来重用。否则,任务分配给网络搜索智能体(Aweb),该智能体通过Google搜索API检索并深度爬取前五个结果的完整内容,确保证据基于实际文本数据而非片段。
判断智能体(Ajud)随后使用严格验证函数评估提取的元数据 Mi 与检索到的证据 E 之间的对齐:
Fjudge(Mi,E)=f∈{T,A,U,V}∏I(ExactMatch(Mif,E))成功匹配触发存储在记忆池中;不匹配则将引用升级到学者智能体(Asch),该智能体对权威存储库(如Google Scholar)进行低频、高精度爬取,以检索规范真实记录 M^i。判断智能体对此记录执行最终字符级对齐。如果此最终检查失败,引用被标记为幻觉并附带溯源报告;否则,引用被验证并存储。
整个管道使用通过vLLM部署的Qwen3-VL-235B A22模型实现,智能体实例化为特定角色:规划模型用于任务路由,Aext 用于OCR和模式映射,Amem 基于Mem0框架用于持久知识保留,Aweb 用于深度网络爬取,Ajud 用于严格匹配,Asch 用于权威检索。系统在多线程池(大小=4)上运行,使用确定性推理(温度=0.0),并采用结构化提示驱动的SOP以确保可复现、可审计的决策。规划智能体(仅任务路由)与判断智能体(仅严格匹配)的角色分离强制执行确定性并防止启发式混淆。
实验
- 我们的模型在检测幻觉引用时不会错误拒绝真实引用,通过强制严格真实性而非宽松合理性,优于现有系统。
- 在真实世界基准上,它实现了最高的准确率、精确率、召回率和F1分数,显著超越替代方案,并在嘈杂、模糊条件下表现稳健。
- 消融研究确认关键角色:学者智能体作为权威验证的最终安全网,LLM判断器实现对格式噪声的语义弹性,网络搜索智能体通过快速路径过滤确保效率。
- 专有LLM因不透明、不可靠的检索行为表现不佳,突显了透明、基于证据的验证工具的需求。
- 案例研究展示了元数据不匹配(如标题、作者)的细粒度检测,提供超越二元分类的可解释、结构化验证,对学术完整性至关重要。
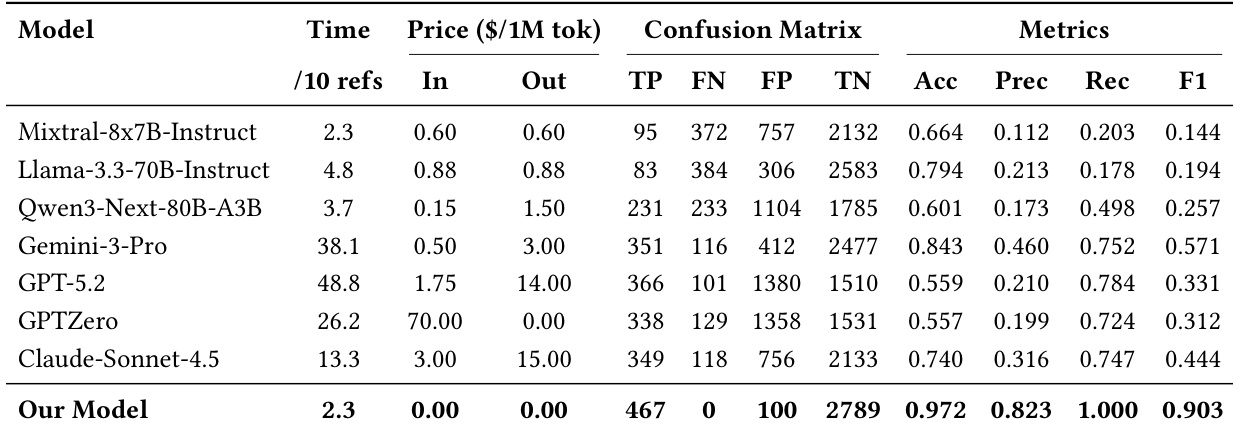
作者使用生成基准和真实世界测试集评估引用验证模型,揭示大多数现有系统难以平衡检测幻觉引用与保留真实引用。他们提出的模型在检测伪造参考方面接近完美,同时在真实引用上保持低误报率,在准确性和成本效率方面优于基线。消融研究确认每个组件——网络搜索、语义推理和权威验证——在实现这种稳健高效性能中起关键作用。
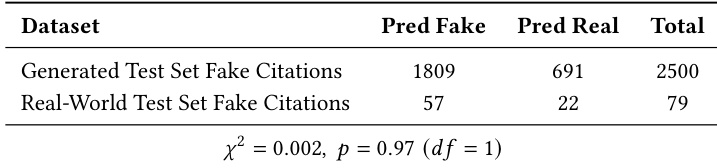
作者在生成基准上评估其引用验证模型与多个基线,显示它实现了接近完美的召回率,零假阴性,并保持高精确率,在平衡幻觉检测和真实引用保留方面优于其他模型。他们的模型也无API成本,处理引用的速度与最高效的基线相当,利用轻量级智能体和外部工具而非依赖昂贵的LLM推理。结果确认系统能够强制执行严格的真实性约束,同时保持成本效益和可扩展性。
作者评估其引用验证框架与消融变体,显示移除学者智能体显著降低召回率,而用字符串匹配替换LLM判断器会大幅降低精确率和F1分数。禁用网络搜索智能体使处理时间增加八倍,确认其在保持效率中的作用。这些结果表明每个组件对系统的平衡准确性、可靠性和速度均有独特贡献。
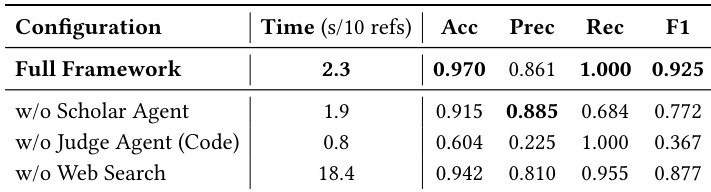
作者在生成基准上评估其引用验证模型与多个基线,显示它实现了接近完美的召回率,零假阴性,同时保持高精确率和低假阳性。他们的模型在成本效率方面也优于商业LLM,无货币成本且速度匹配或超越,因其架构将LLM使用限制在高层判断,而将验证卸载给轻量级智能体。结果表明模型强制执行严格的引用真实性而非依赖合理性,导致在受控和真实世界设置中更可靠、可解释的验证。
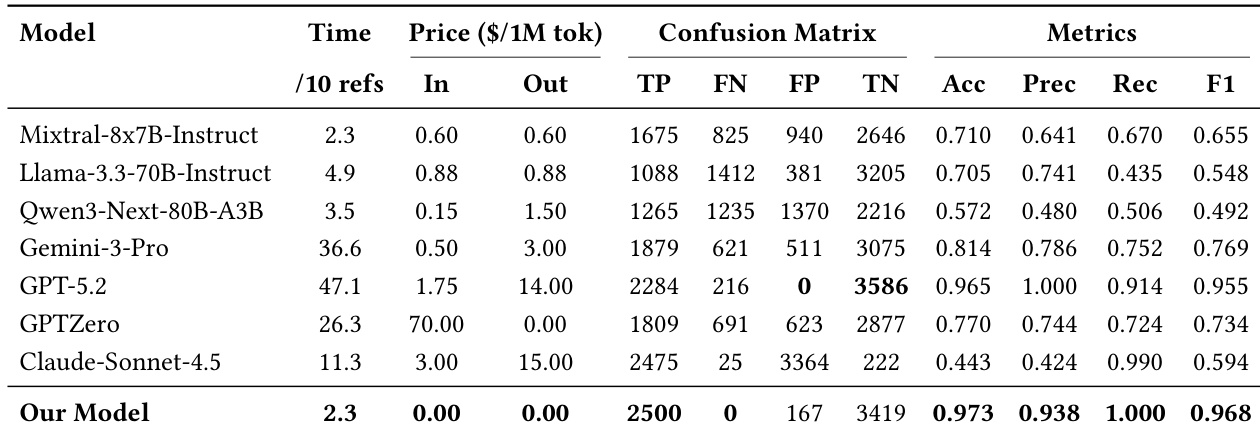
作者在两个测试集上评估引用验证模型:一个具有受控幻觉的生成基准和一个具有自然发生错误的真实世界集。结果显示,现有模型难以平衡检测伪造引用与保留真实引用,而他们提出的系统通过结合轻量级智能体与权威验证实现了高准确性和可靠性。该框架还通过将重型LLM使用限制在最终判断而非完整检索,保持了效率和成本效益。