Command Palette
Search for a command to run...
MOOSE-Star:打破复杂性壁垒,开启科学发现的可行训练新范式
MOOSE-Star:打破复杂性壁垒,开启科学发现的可行训练新范式
Zonglin Yang Lidong Bing
摘要
尽管大语言模型(LLMs)在科学发现领域展现出巨大潜力,但现有研究主要集中于推理或反馈驱动的训练,而对生成式推理过程 P(hypothesis∣background)(即 P(h∣b))的直接建模尚未得到充分探索。本文证明,由于从海量知识库中检索并组合灵感所固有的组合复杂性(O(Nk)),直接训练 P(h∣b) 在数学上是不可行的。为突破这一瓶颈,我们提出了 MOOSE-Star,这是一个支持可计算训练与可扩展推理的统一框架。在最优情况下,MOOSE-Star 通过以下三项核心机制将计算复杂度从指数级降低至对数级(O(logN)):(1)基于科学发现概率方程分解出的子任务进行训练;(2)采用动机引导的分层搜索策略,实现高效对数级检索并剪枝无关子空间;(3)利用有界组合机制以增强对检索噪声的鲁棒性。为支持上述研究,我们发布了 TOMATO-Star 数据集,该数据集包含 108,717 篇经分解处理的论文,累计训练消耗达 38,400 GPU 小时。此外,我们的研究表明,尽管暴力采样方法会遭遇“复杂度墙”(complexity wall),MOOSE-Star 却能展现出持续的测试时扩展能力。
一句话总结
MOOSE-STAR 项目的研究人员推出了 MOOSE-STAR,这是一个统一的框架,通过分层搜索和受限组合将计算复杂度从指数级降低到对数级,从而实现了科学发现的可处理训练,并支持在暴力方法失效时进行持续的测试时扩展。
主要贡献
- 提出的 MOOSE-STAR 框架通过将目标分解为子任务、采用动机引导的分层搜索以及利用受限组合,将复杂度从指数级降低到对数级,从而克服了这一障碍。
- 为了支持这一方法,作者发布了包含超过 108,000 篇分解论文的 TOMADO-STAR 数据集,并证明了该方法能够在暴力采样失效的情况下实现持续的测试时扩展。
引言
大语言模型在科学发现方面具有巨大潜力,但当前的研究主要依赖推理策略或反馈驱动的训练,而非直接建模核心的生成推理过程。现有方法面临困难,因为它们依赖外部反馈来优化假设,而不是学习直接从研究背景中生成高质量的想法;理论分析表明,由于指数级的组合复杂度,直接训练该概率在数学上是不可处理的。为了克服这一障碍,作者推出了 MOOSE-STAR,这是一个统一的框架,通过分解任务、采用动机引导的分层搜索将复杂度降低到对数级,并利用受限组合来增强鲁棒性,从而实现了可处理的训练和可扩展的推理。
数据集
-
数据集构成与来源:作者构建了 TOMATO-Star,这是一个大规模数据集,源自 NCBI 数据库中的 108,717 篇开放获取科学论文。该语料库涵盖生物学、化学和认知科学,收录了从 2020 年 1 月到 2025 年 10 月的出版物。
-
各子集的关键细节:
- 训练集:包含 2020 年 1 月至 2025 年 9 月发表的论文。
- 测试集:由 2025 年 10 月发表的论文组成,以确保严格的时间划分并防止数据污染。
- 过滤规则:每个样本都经过四项自动化质量检查,以验证信息的必要性、充分性、背景与灵感之间的互斥性,以及提取灵感的非冗余性。
-
模型使用与处理:
- 预处理:原始 PDF 文档使用 MinerU 转换为 Markdown。
- 分解:本地部署的推理模型(DeepSeek-R1 和 R1-distilled-Qwen-32b)将每篇论文分解为包含研究背景、假设和灵感的结构化元组。
- 假设结构:假设被格式化为“增量假设(Delta Hypotheses)”,其中每个灵感映射到包含动机、机制和方法论层级的特定增量。
- 灵感:真实灵感源自来源引用,并通过 Semantic Scholar 检索到的完整标题和摘要进行增强。
-
其他处理细节:该流程强制要求灵感与假设增量之间保持严格的一对一映射。作者确保背景部分与灵感和假设保持严格独立,以在训练期间维持逻辑完整性。
方法
作者解决了直接建模边缘概率 P(h∣b) 的计算不可处理性问题,由于在全球知识库 I 上进行组合搜索,该概率随 O(Nk) 呈指数级增长。为了解决这一问题,他们引入了 MOOSE-STAR 框架,该框架实现了概率分解理论。这种方法将庞大的生成任务转化为一系列 k 个可管理的子任务:灵感检索和假设组合。通过将搜索与组合解耦,复杂度从指数级降低到线性 O(k×N)。
为了进一步优化线性检索项 O(N),该框架采用了受限组合。作者引入了一个语义容差空间,而不是要求模型从整个数据库中检索确切的真实灵感 i∗。这使得组合模块即使在提供与 i∗ 语义相似的代理灵感 i 时也能稳健运行。
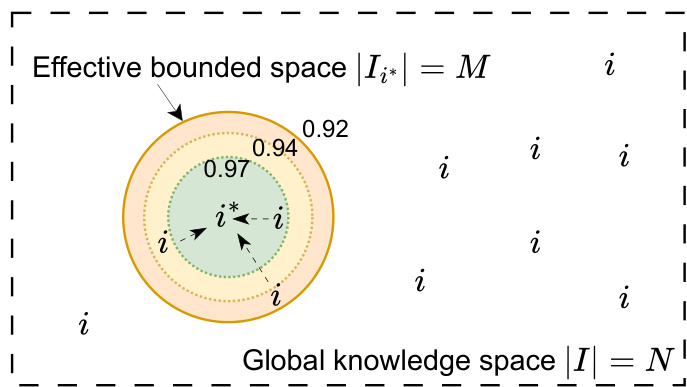
如上图所示,全局知识空间 ∣I∣=N 包含确切的灵感 i∗。有效的受限空间 ∣Ii∗∣=M 代表以 i∗ 为中心的语义邻域,由同心相似性阈值定义。通过训练模型在该受限窗口内使用灵感组合假设,检索复杂度有效地降低到 O(N/M),而组合成本仅随 M 线性增加。由于 N≫M,这种权衡带来了总复杂度的显著净减少。
在此基础上,作者实施了分层搜索以替代对知识库的线性扫描。他们通过对论文嵌入进行自底向上的聚类构建了语义搜索树。在推理过程中,最佳优先搜索(Best-First Search)策略导航该树,剪枝无关分支,并在最佳情况下实现对数级复杂度 O(logN)。最后,引入了动机规划作为高层生成根。通过在研究背景中附加动机变量 m,搜索被引导至特定的语义子空间,进一步将有效搜索空间减少到 Nm<N。整个框架使用基于教师的拒绝采样微调(Rejection Sampling Fine-Tuning)流程在 TOMADO-STAR 数据集上进行训练,该数据集包含超过 100,000 篇处理过的科学论文。
实验
- 分解顺序训练验证了为灵感检索和假设组合微调专用模型显著优于基线,接触受限训练数据进一步增强了针对噪声输入的推理鲁棒性。
- 受限组合实验证实,纳入由噪声灵感生成的数据可以提高假设质量,无论其与真实值的语义相似性处于何种水平。
- 分层搜索展示了优于穷举基线的效率,通过有效剪枝无关分支,在保持高检索准确率的同时将推理调用减少了约三倍。
- 动机规划分析表明,源自增量假设的详细、战略性指令相比简单的需求翻译显著提高了搜索效率。
- 扩展性研究揭示,将任务分解为检索和组合子问题克服了端到端暴力采样中固有的训练僵局,即使在复杂的多步发现中也能实现高成功率。
- 数据扩展实验表明,虽然检索模型呈对数线性提升,但假设组合需要最低的数据阈值才能实现显著增益,然而两项任务均支持可扩展的训练范式。
- 测试时扩展结果强调,所提出方法的引导式结构化方法随着计算资源的增加实现了近乎完美的覆盖,而无引导的暴力采样随着问题复杂度的上升因组合爆炸而彻底失败。