Command Palette
Search for a command to run...
HoMMI:从人类示范中学习全身移动操作
HoMMI:从人类示范中学习全身移动操作
Xiaomeng Xu Jisang Park Han Zhang Eric Cousineau Aditya Bhat Jose Barreiros Dian Wang Shuran Song
摘要
本文提出“全身移动操作接口”(Whole-Body Mobile Manipulation Interface, HoMMI),这是一个数据采集与策略学习框架,能够从无需机器人参与的真人演示中直接学习全身移动操作任务。我们通过增强通用移动接口(UMI),引入第一人称(e.g., ego-centric)视觉感知,以捕捉移动操作所需的全局上下文信息,从而实现便携、无机器人依赖且可规模化扩展的数据采集流程。然而,若简单地将第一人称感知纳入系统,会导致观测空间与动作空间中的人机具身差异(embodiment gap)显著扩大,从而极大增加策略迁移的难度。为有效弥合这一鸿沟,我们提出了一种跨具身的手眼协同策略架构,该架构包含:(1)具身无关的视觉表征;(2)松弛化的头部动作表征;以及(3)一种全身控制器,该控制器在满足机器人特定物理约束的前提下,通过协调全身运动来执行手眼轨迹。上述设计共同支撑了需要双手操作、全身协调、自主导航及主动感知的长时程移动操作任务。相关实验结果及演示视频可在以下网址查看:https://hommi-robot.github.io
一句话总结
斯坦福大学与丰田研究所的研究人员推出了 HoMMI 框架,该框架通过第一人称视角感知,直接从无需机器人的真人演示中学习全身移动操作;它利用 3D 视觉表征和“注视点”动作弥合具身差异,在真实机器人上实现精确的双手协调、导航与主动感知。
主要贡献
- HoMMI 通过在 UMI 基础上增强第一人称感知,实现了从无需机器人的真人演示中可扩展地学习全身移动操作,捕捉用于导航与双手协调的全局上下文,同时避免昂贵的遥操作。
- 为弥合人机具身差异,它引入了具身无关的 3D 视觉表征和放松的“3D 注视点”头部动作空间,使主动感知策略可迁移至具有不同形态与颈部约束的机器人。
- 系统集成了一种约束感知的全身控制器,协调基座、躯干和手臂运动,在物理限制下跟踪末端执行器轨迹,从而在大型真实环境中完成精确、长时程的操作任务。
引言
作者利用真人演示学习全身移动操作,无需机器人遥操作,解决了现实任务中机器人学习规模化的一个关键瓶颈。以往使用手持设备(如 UMI)的系统因手腕中心感知缺乏全局上下文,而第一人称视角方法在视觉与运动学领域均存在巨大具身差异——常需额外机器人数据或限制任务于固定基座。HoMMI 通过结合头戴式摄像头与重构的策略架构克服此问题:它使用具身无关的 3D 视觉表征处理视角不匹配,采用放松的“注视点”动作空间适应不同颈部运动学,以及约束感知的全身控制器将手眼轨迹转化为可行且协调的机器人运动。这使得复杂、长时程的移动操作技能(包括导航、双手协调与主动感知)可直接从真人演示迁移至真实机器人。
数据集
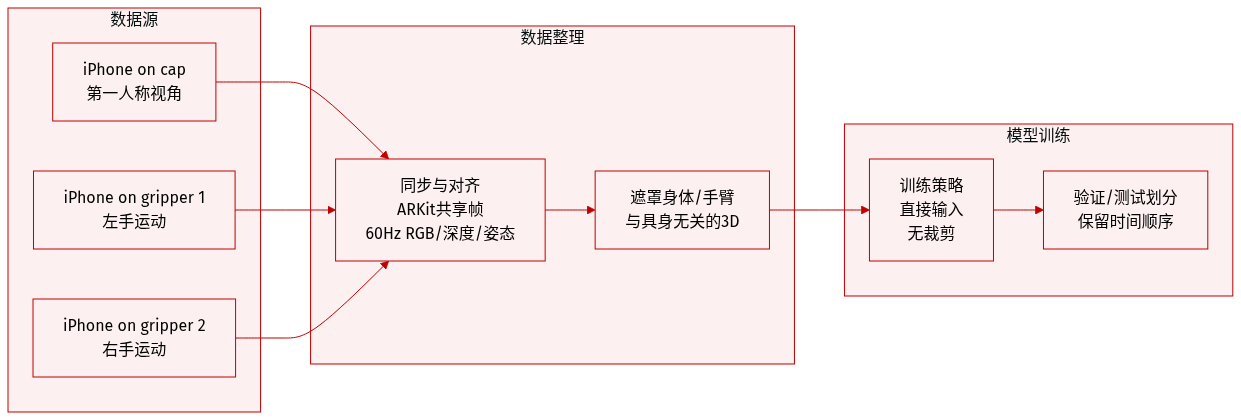
- 作者使用基于三部 iPhone 构建的自定义数据采集接口:两部安装在夹爪上,一部安装在帽子上,实现无需机器人的第一人称、双手移动操作演示。
- 数据包括每设备 60Hz 同步采集的 RGB 视频、深度图、6 自由度位姿和夹爪宽度,通过 Apple ARKit 多设备协作对齐至共享坐标系。
- 系统通过提供直接视觉与触觉反馈避免 VR 引发的晕动症,使操作轻量直观。
- 观测数据被处理为具身无关的 3D 视觉表征,屏蔽身体与手臂特定元素,以泛化至不同具身。
- 此多模态轨迹数据直接输入策略学习管道,无需额外预处理或裁剪,保留时空对齐。
方法
作者采用跨具身的手眼策略架构,旨在弥合真人演示者与目标移动操作器在视觉、运动学与空间上的差异。系统基于端到端训练的扩散策略,以短观测窗口 Ot=ot−To+1,…,ot 为条件,预测动作序列 At=at+1,…,at+Tp。为确保可迁移性,策略集成三项核心算法创新:3D 视觉表征、3D 注视点动作表征与夹爪中心空间框架。
参见框架图,其展示了从数据采集到策略推理再到机器人部署的完整流程。策略输入多模态观测,包括头部与手腕 RGB 图像、深度衍生点云及本体感知。这些数据经具身无关视觉编码器处理后融合为全局嵌入,作为 Diffusion Transformer (DiT) 主干的条件。策略输出 23 维动作向量,包含双手末端执行器位姿(各 9D:3D 位置 + 6D 旋转矩阵列向量)、3D 注视点与夹爪宽度。
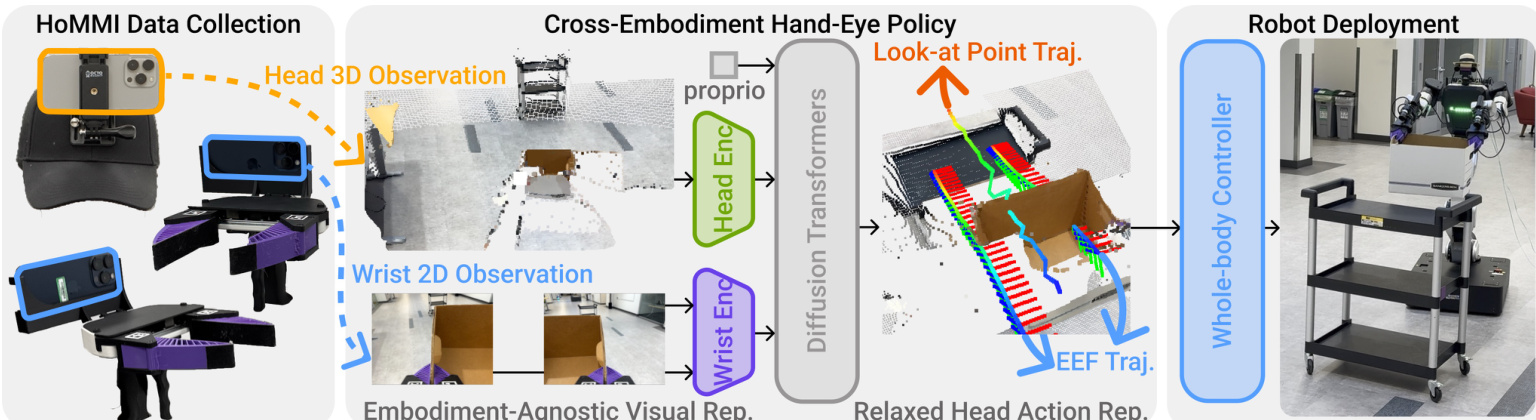
3D 视觉表征通过将第一人称头部摄像头观测提升至 3D 空间来缓解视觉差异。每帧生成点云(通过 iPhone 深度或立体估计),划分为 16×16 区域并下采样为 512 个标记。每个块由 DINO-v3 ViT 特征编码,并附加其 3D 位置的正弦编码。为减少外观不匹配,通过将点云变换至左右夹爪坐标系并剔除 z<0 的点来屏蔽手臂点。注意力池化层将这些几何感知标记聚合为头部观测嵌入 Fego。手腕图像通过共享 DINO-v3 ViT 编码器处理,缩放至 224×224,并由 CLS 标记 Fwrist 表示。本体感知与之拼接形成完整观测嵌入。
如下图所示,3D 头部观测锚定在夹爪坐标系中,手臂点被屏蔽,位置编码用于将外观与几何绑定。
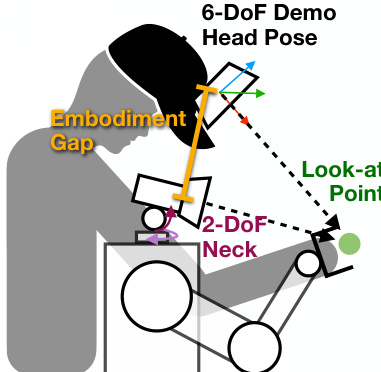
为解决运动学差异,策略不输出 6 自由度头部位姿,而是预测 3D 注视点 ℓt∈R3。此放松表征保留主动感知意图,同时尊重机器人 2 自由度颈部约束。训练时,ℓt 计算为头部相机射线与场景点云的交点。推理时,头部控制器将 ℓt 转换为可行朝向:构造旋转矩阵 Rt=[x^ty^td^t],其中 d^t=∥ℓt−ct∥ℓt−ct 为从当前头部位置 ct 指向注视点的单位向量,x^t 为当前 x 轴在垂直于 d^t 平面上的归一化投影,y^t=d^t×x^t。若投影接近零,则使用世界向上向量确保数值稳定性。
下图说明 3D 注视点如何将感知意图与运动学约束解耦,使机器人能实现任务相关凝视而不精确模仿人类头部姿态。
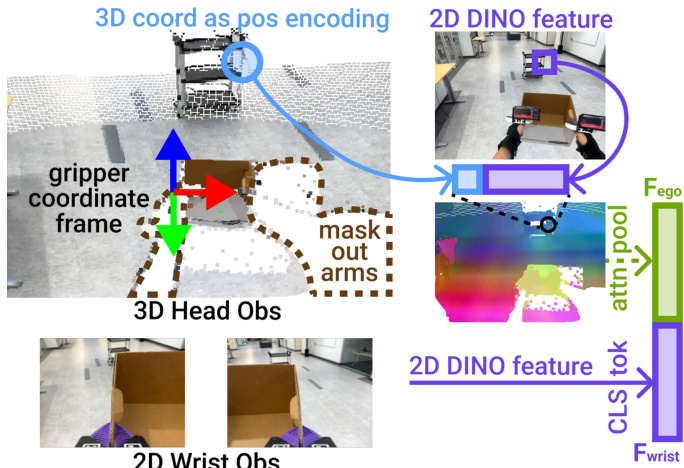
所有观测与动作均以夹爪中心坐标系表达以保持空间一致性。头部点云、注视点与夹爪位姿均变换至左夹爪坐标系,将策略推理锚定于执行任务的操纵器。这缓解了因头部高度、颈部自由度与相机位置差异导致的漂移。
策略采用 Diffusion Policy 与 DiT 主干实现,以全局观测嵌入为条件,通过 DDIM 调度器训练预测噪声。模型使用 768 维嵌入、10 层、12 个注意力头与 RMS 归一化。观测下采样至 20Hz,To=2,Tp=32。动作维度为 23D:每夹爪 9D(3D 位置 + 6D 朝向)、3D 注视点与 2D 夹爪宽度。训练使用 AdamW,余弦学习率调度,权重衰减 1×10−6,共 500 个周期。
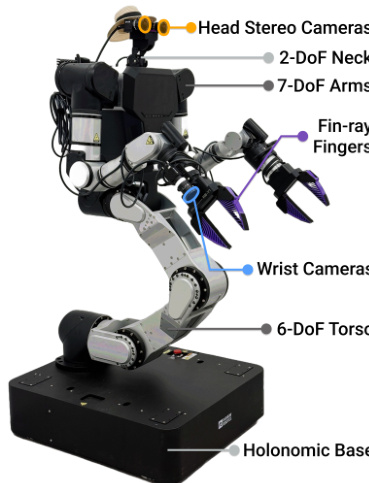
硬件平台为 Rainbow Robotics RB-Y1 双手移动操作器,配备 6 自由度躯干、两个 7 自由度手臂、2 自由度颈部与全向基座。定制 fin-ray 手指匹配数据采集所用 UMI 夹爪。头戴式立体相机与手腕 RGB 相机提供第一人称与手腕视角。传感堆栈使用通过 PoE 交换机与 10 Gbps 光纤连接至外部工作站的 GigE 相机,运行策略推理与控制。
如下硬件示意图所示,机器人集成头部立体相机、2 自由度颈部、带手腕相机的 7 自由度手臂、fin-ray 手指及安装在全向基座上的 6 自由度躯干。
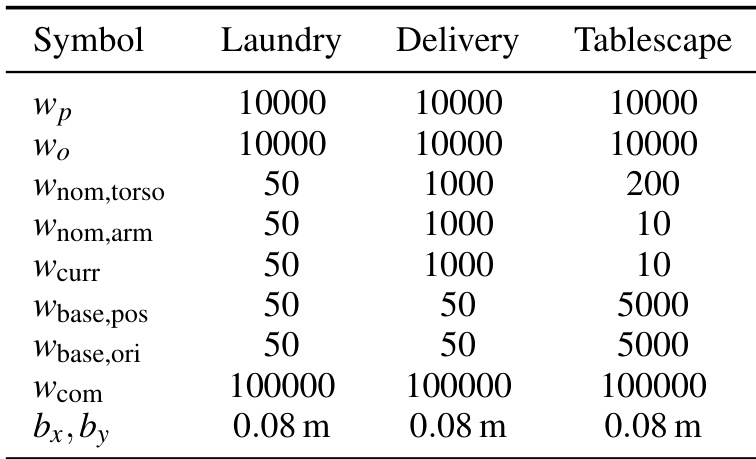
全身控制器使用基于 Mink 的微分逆运动学求解器将策略输出转换为关节速度。求解器最小化目标函数 f(Δq)=Cee+Cnominal+Ccurrent+Ccom,受配置、关节速度、基座速度、避碰与直立姿态约束。双手 SE(3) 跟踪代价 Cee 优先保证末端执行器精度,Cnominal 正则化至类人姿态,Ccurrent 确保运动平滑,Ccom 维持重心在基座上方。求解器异步运行于 100Hz,插值策略指令(10Hz 发出)以向 500Hz 机器人控制环提供连续目标。时间插值对位置线性混合,对朝向使用球面线性插值以消除运动抖动。
系统采用异步策略推理以避免计算阻塞。分离的策略服务器接收带时间戳、延迟校正的观测,执行推理并返回带时间戳的动作块。实时执行桥同步传感器流,丢弃过时动作,并向全身控制器流式传输时间对齐目标,确保感知、策略与控制无缝集成。
实验
- HoMMI 成功将策略从真人演示迁移至具身不同的机器人,验证了跨具身学习在长时程双手移动操作中的有效性。
- 系统在全身协调、长时程导航与主动感知方面表现优异,在洗衣、递送与桌面场景任务中优于所有基线。
- 仅手腕感知无法捕捉全局上下文,导致导航与对齐错误;仅头部感知缺乏局部接触线索,导致抓取失败。
- 直接添加第一人称 RGB 会因具身不匹配与运动学不可行性降低性能,而 HoMMI 的 3D 第一人称表征与注视点控制解决了这些问题。
- 主动头部控制对收集任务相关视觉信息与维持可观测性至关重要,启用后显著提升成功率。
- HoMMI 同时使用手腕与头部视角实现更清晰、任务导向的注意力,提高鲁棒性并降低分布外敏感性。
作者使用跨具身手眼策略,整合手腕与头部相机输入,实现长时程双手移动操作,通过结合局部接触线索与全局场景上下文在多样任务中实现高成功率。结果表明,主动头部控制与 3D 第一人称表征对稳健导航与物体交互至关重要,而仅依赖手腕或头部视角的基线因可观测性有限或具身不匹配而失败。禁用主动感知或省略手腕输入会显著降低性能,证实协调多视角感知与自适应视角控制对可靠现实部署不可或缺。