Command Palette
Search for a command to run...
模式寻找与均值寻找相结合实现快速长视频生成
模式寻找与均值寻找相结合实现快速长视频生成
摘要
将视频生成从秒级扩展至分钟级面临一个关键瓶颈:尽管短时视频数据丰富且保真度高,但具备连贯性的长视频数据却极为稀缺,且仅局限于特定领域。为解决这一问题,我们提出一种新型训练范式——“模式探索”(Mode Seeking)与“均值探索”(Mean Seeking)相结合,通过统一的表示框架,基于解耦扩散变换器(Decoupled Diffusion Transformer)实现局部保真度与长期连贯性的解耦。该方法采用在长视频上通过监督学习训练的全局流匹配(Flow Matching)头,以捕捉叙事结构;同时引入局部分布匹配(Distribution Matching)头,通过模式探索型反KL散度(mode-seeking reverse-KL divergence),将滑动窗口内的生成内容对齐至一个冻结的短视频教师模型。这一策略使得模型能够仅依靠有限的长视频数据,通过监督流匹配学习长程时序连贯性与运动规律,同时通过将学生模型的每个滑动窗口段与冻结的短视频教师对齐,继承局部真实感,从而实现仅需几步即可生成分钟级长视频的高效生成器。实验评估表明,该方法有效弥合了保真度与生成时长之间的鸿沟,在提升局部清晰度、运动自然性以及长程一致性方面均取得显著进展。项目主页:https://primecai.github.io/mmm/。
一句话总结
斯坦福大学与 NVIDIA 的研究人员提出了一种解耦扩散变换器(Decoupled Diffusion Transformer),该模型结合了监督流匹配以实现长期一致性,以及与短视频教师模型的逆 KL 对齐以提升局部真实性,从而实现快速、分钟级视频生成,并显著提升保真度与时间一致性。
主要贡献
- 我们引入了一种解耦训练范式,通过模式寻求的逆 KL 散度,将长视频生成器的滑动窗口片段与冻结的短视频教师模型对齐,在无需额外短视频数据的前提下保留局部保真度。
- 我们的解耦扩散变换器采用独立的流匹配与分布匹配头,共同从有限的长视频中学习长程叙事结构,并从教师模型中学习局部真实性,两者均从共享表示中解码。
- 在推理阶段仅使用分布匹配头,我们实现了快速的几步生成,可生成分钟级视频,同时保持清晰的局部运动与长程一致性,有效弥合了保真度与时间跨度之间的鸿沟。
引言
作者利用解耦训练范式应对生成分钟级视频的挑战——由于数据稀缺,长期一致性与局部保真度通常难以兼顾。以往混合短视频与长视频的方法假设时间缩放类似于空间分辨率缩放——作者驳斥了这一类比,指出长视频需要外推新事件和因果结构,而非仅插值帧。现有方法要么为延长时长牺牲局部清晰度,要么依赖昂贵且稀缺的长视频数据集。其核心贡献是一种双头解耦扩散变换器:流匹配头在真实长视频上训练,学习全局叙事结构;分布匹配头则通过模式寻求的逆 KL 散度,将滑动窗口片段与冻结的短视频教师模型对齐——从而在保持局部真实性和长程一致性的同时,实现快速的几步推理。
数据集
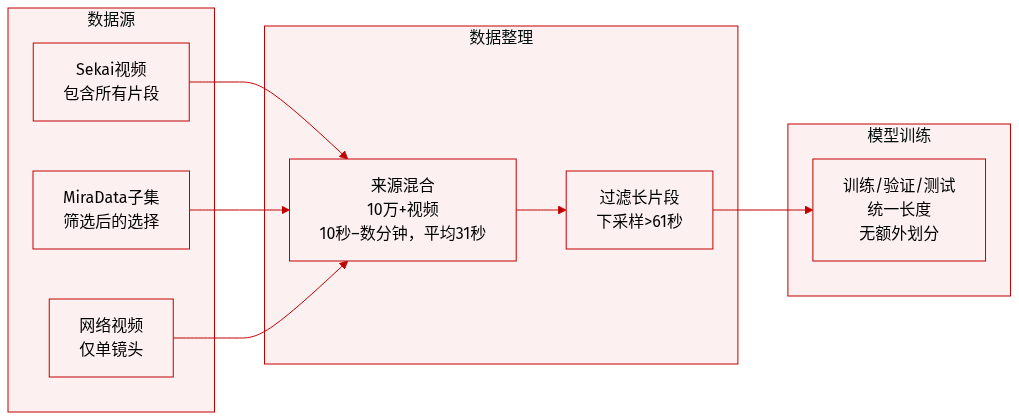
- 作者使用多个来源的数据:Sekai 数据集中的所有视频、MiraData 的筛选子集,以及经单镜头过滤的互联网视频。
- 合并后的数据集包含超过 10 万条视频,每条时长 10 秒至数分钟,平均 31 秒。
- 超过 61 秒的视频通过时间下采样以满足上限。
- 数据直接用于训练,未提及混合比例或额外划分——处理重点是通过下采样实现统一长度。
方法
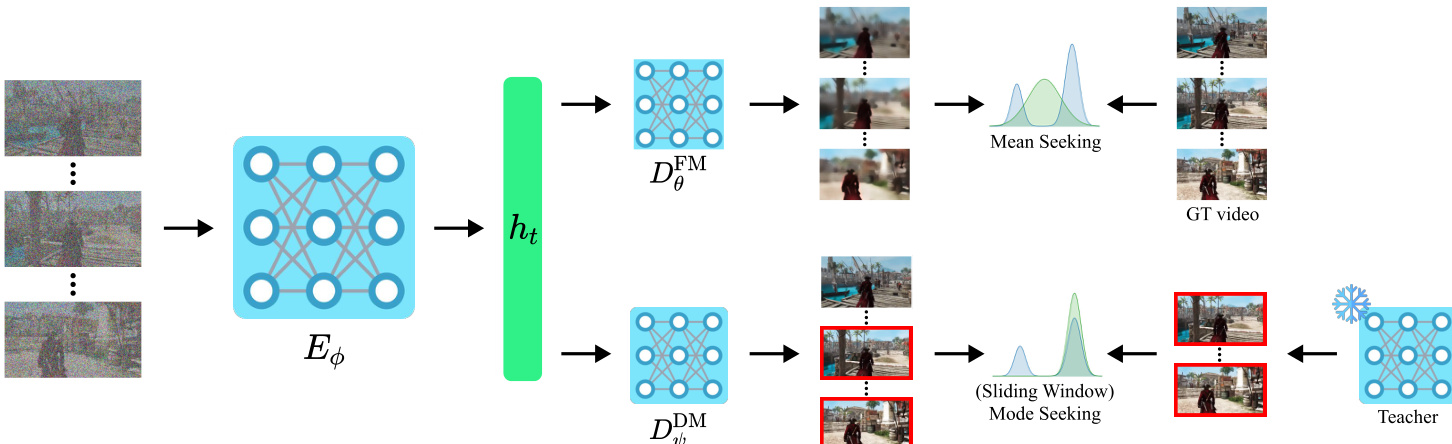
作者采用解耦架构,以协调视频生成中长期一致性与局部真实性的竞争目标。核心设计围绕一个共享条件编码器,该编码器处理含噪长视频潜变量,并馈送两个独立的解码器头,每个头针对不同的训练信号进行优化。该结构使模型能同时从稀缺的长视频中学习全局时间结构,并通过与短视频教师对齐保留高保真局部动态。
条件编码器 Eϕ 接收含噪长视频潜变量 xtlong、时间步 t 和条件 c,输出时空特征张量 ht。架构上,Eϕ 实现为具有全范围时序注意力的视频扩散变换器,作为两个头共享的骨干。该共享表示确保长上下文特征在不同目标间被学习并重用,促进全局与局部建模的一致性。
在 ht 之上附加两个轻量级变换器解码器。第一个 DθFM 参数化流匹配(FM)头,输出全局速度场 uθ(xtlong,t,c)。该头通过在真实长视频上进行监督流匹配训练,最小化预测速度与真实边缘速度 x0long−zlong 之间的均方误差。该目标将模型锚定于真实长视频轨迹,鼓励分钟级时间一致性与叙事结构。
第二个头 DψDM 实现分布匹配(DM)目标。它输出局部速度场 vψ(xtlong,t,c),用于生成滑动窗口片段。这些片段通过逆 KL 损失与专家短视频教师对齐,该损失通过 DMD/VSD 风格的梯度代理实现。具体而言,对于每个窗口 k,模型裁剪预测速度,并与教师在相应含噪窗口上的速度比较。梯度计算为学生“虚假”分数估计器与教师速度之差,乘以时间依赖权重 λ(t),并仅通过生成窗口 x^0(k) 反向传播。该模式寻求信号鼓励学生聚焦于教师的高保真局部模式,从而在无需访问教师训练数据的前提下保留短时域真实性。
参考框架图,该图说明共享编码器 Eϕ 如何同时馈送均值寻求的 FM 头与模式寻求的 DM 头。FM 头由真实长视频监督,而 DM 头通过滑动窗口比较由短视频教师正则化。这种解耦使每个头得以专业化:FM 头学习全局动态,DM 头优化局部质量。
实验
- 验证了仅使用 SFT 的方法(LongSFT、MixSFT)可建立基本时间一致性,但因数据稀缺与平均效应导致模糊和细节丢失。
- 确认仅依赖教师的方法(CausVid、Self-Forcing、InfinityRoPE)初期可保留局部真实性,但随时间推移因误差累积与缺乏长上下文锚定而退化,常导致静止或过于保守的运动。
- 证明所提方法通过解耦全局长上下文学习(通过 SFT)与局部保真对齐(通过教师分布匹配),在运动平滑性、场景一致性与视觉质量方面优于基线。
- 消融研究确认双头架构、滑动窗口教师匹配与长视频 SFT 的必要性——每个组件均独立贡献于长时域一致性与短时域真实性,且无梯度干扰。
- 多项指标与 Gemini-3-Pro 评估的定性与定量结果一致支持该方法生成时间一致、视觉丰富且叙事稳定的长视频。
作者采用解耦双头架构,分别处理长程一致性与短程保真度,结合真实长视频上的监督微调与局部教师分布匹配。结果表明,移除任一组件均导致性能下降,证实全局结构学习与局部纹理保留对高质量长视频生成均至关重要。完整模型在一致性、运动与质量间取得最佳平衡,优于消融变体与基线方法。
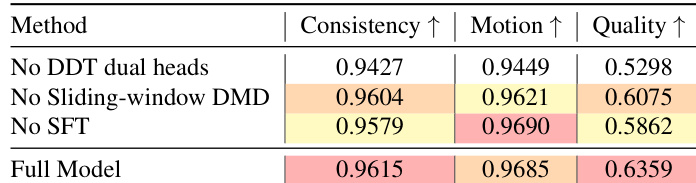
作者采用结合长视频监督微调与局部教师分布匹配的解耦双头架构,生成分钟级视频。结果表明,该方法在保持长程叙事一致性的同时保留高保真运动与视觉细节,优于仅 SFT 或仅教师的基线方法。消融研究确认每个组件——全局 SFT、局部模式寻求与架构分离——对一致性与质量的提升均不可或缺。
