Command Palette
Search for a command to run...
ArtHOI:基于视频先验的 4D 重建生成可 Articulated 的人 - 物交互
ArtHOI:基于视频先验的 4D 重建生成可 Articulated 的人 - 物交互
Zihao Huang Tianqi Liu Zhaoxi Chen Shaocong Xu Saining Zhang Lixing Xiao Zhiguo Cao Wei Li Hao Zhao Ziwei Liu
摘要
在不依赖三维或四维监督信号的情况下,合成具有物理合理性的可 Articulated(关节化)人机交互(HOI)仍是一项根本性挑战。尽管近期出现的零样本方法利用视频扩散模型来合成人机交互,但其应用范围主要局限于刚性物体的操作,且缺乏显式的四维几何推理能力。为弥合这一差距,我们将可 Articulated 人机交互的合成问题建模为基于单目视频先验的四维重建问题:仅利用扩散模型生成的视频,在无三维监督的条件下重建完整的四维可 Articulated 场景。该基于重建的方法将生成的二维视频视为逆渲染问题的监督信号,从而恢复出在几何上自洽且物理上合理的四维场景,这些场景天然地满足接触约束、关节运动约束以及时序一致性。为此,我们提出了 ArtHOI——首个通过视频先验进行四维重建以实现零样本可 Articulated 人机交互合成的框架。其核心设计包括:1)基于光流的部件分割:利用光流作为几何线索,在单目视频中解耦动态区域与静态区域;2)解耦式重建流程:由于在单目模糊性下,人体运动与物体关节运动的联合优化往往不稳定,我们首先恢复物体的关节构型,随后以重建后的物体状态为条件合成人体运动。ArtHOI 有效 bridged(桥接)了基于视频的生成果与几何感知重建,生成了兼具语义一致性与物理合理性的交互场景。在多种可 Articulated 场景(例如开启冰箱、橱柜、微波炉等)的实验中,ArtHOI 在接触精度、穿透抑制以及关节运动保真度等方面均显著优于现有方法,从而通过“重建引导的合成”范式,将零样本交互合成从刚性物体操作拓展至更复杂的可 Articulated 物体操作。
一句话总结
南洋理工大学 S-Lab 的研究人员提出了 ArtHOI,这是首个通过将从单目视频先验重构的任务重新表述为 4D 重建问题,从而合成可动人机交互的零样本框架。与以往仅限于刚性物体的端到端生成方法不同,ArtHOI 采用基于光流的分割技术和解耦的两阶段流程,以恢复如打开橱柜等复杂可动场景中的物理合理动力学。
主要贡献
- 现有的零样本方法难以合成与可动物体之间物理合理的交互,因为它们依赖于刚性体假设,且缺乏显式的 4D 几何推理。
- ArtHOI 引入了一种新颖的两阶段重建流程,将单目视频生成作为逆渲染的监督信号,利用基于光流的分割和解耦优化,在无 3D 监督的情况下恢复可动物体动力学和人体运动。
- 在打开冰箱和橱柜等多样化场景中的实验表明,ArtHOI 在接触精度、穿透减少和可动保真度方面显著优于先前的方法。
引言
合成与可动物体(如打开橱柜或门)之间物理合理的人机交互,对于推动机器人技术、虚拟现实和具身智能的发展至关重要。以往依赖视频扩散模型的零样本方法在该领域表现不佳,因为它们将物体视为刚性体,且缺乏显式的 4D 几何推理,导致结果在物理上不合理,且无法建模复杂的部件级运动学。为了解决这些局限性,作者提出了 ArtHOI,这是首个将可动交互合成表述为基于单目视频先验的 4D 重建问题的零样本框架。该方法利用解耦流程,首先利用光流线索恢复物体可动性,然后基于重建的物体状态合成人体运动,从而在无需 3D 监督的情况下确保几何一致性和物理合理性。
方法
作者通过将问题表述为 4D 重建问题,解决了从单目视频先验合成物理合理的可动人机交互的难题。为了解决在弱 2D 监督下人体运动与物体可动性之间的歧义,他们采用了解耦的两阶段重建框架。如框架图所示,该流程接收单目视频,并利用 3D 高斯重建完整的 4D 可动场景。该架构将优化过程分为两个阶段:第一阶段在运动学约束下恢复物体可动性,第二阶段则基于重建的几何结构细化人体运动。
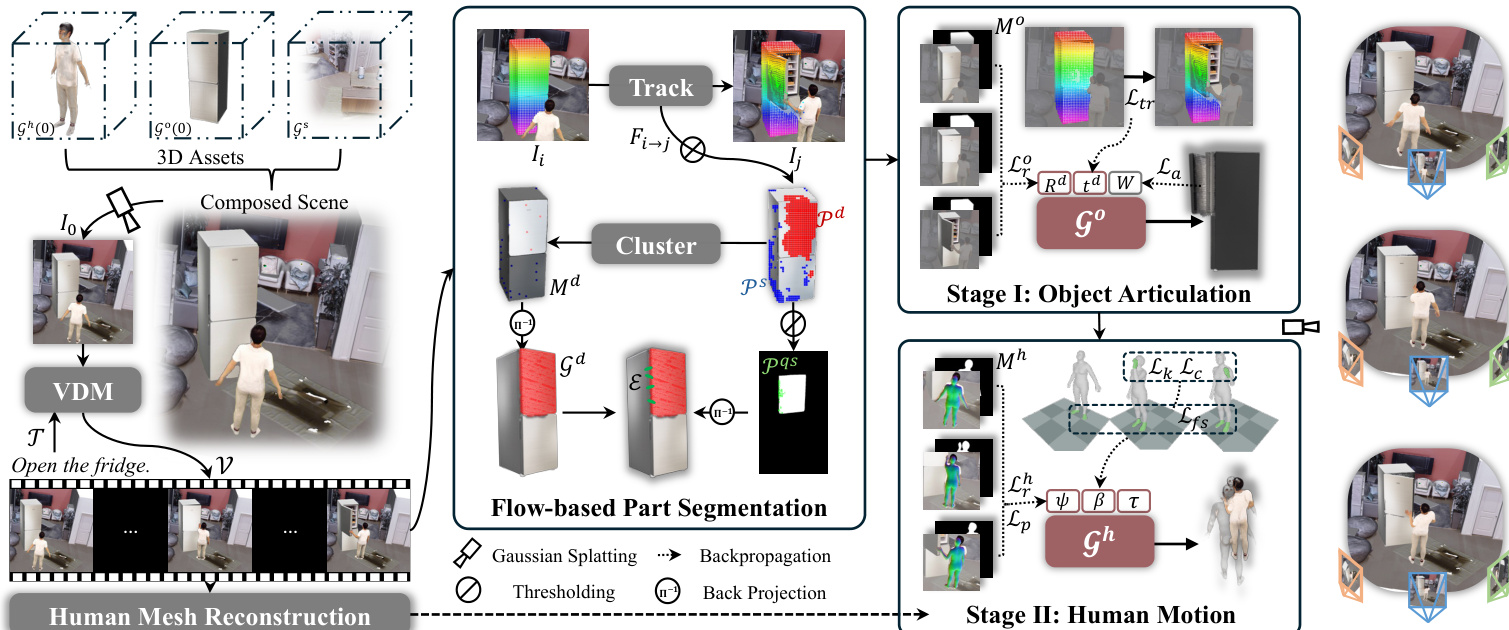
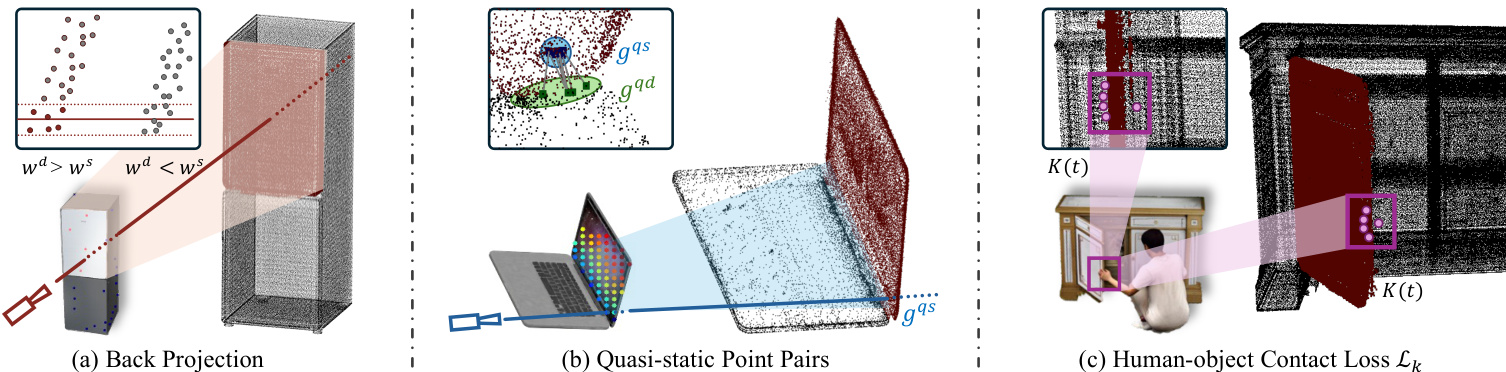
为了实现运动学建模,系统首先通过基于光流的部件分割流程识别哪些物体区域是可动的。该模块结合了点跟踪、SAM 引导的掩码以及向 3D 的反投影。系统跟踪稠密的 2D 轨迹以将点分类为动态或静态,然后利用 Segment Anything Model 生成二值掩码。这些掩码通过反投影转移到 3D 高斯表示中,在此过程中累积像素影响,将高斯分配给动态或静态集合。为了施加刚性体约束,系统在可动边界处识别准静态点对,以连接动态和静态区域。下图详细展示了单目监督下可动交互的关键组件,包括将掩码映射到 3D 的反投影、连接区域的准静态点对以及接触损失机制。
在第一阶段,系统通过优化动态部分的 SE(3) 变换 Td(t) 来重建物体可动性,同时保持静态部分固定。优化目标整合了用于匹配视频先验的重建损失、用于对齐点轨迹的跟踪损失,以及用于维持绑定对之间连接性的可动损失。总损失公式如下:
{Rd,td}minLro+λaLa+λsLs+λtrLtr.可动损失 La 惩罚绑定对 (gd,gs)∈E 之间距离的变化,确保物体部件作为刚性体移动。该阶段建立了几何一致的 4D 物体骨架。
在第二阶段,基于固定的物体几何结构细化人体运动。作者通过识别人体掩码与物体轮廓重叠但物体掩码缺失的帧来推导 3D 接触关键点,这表明人体手部遮挡了物体。这些 2D 区域利用最近邻动态物体高斯的深度被提升到 3D。随后优化人体参数(SMPL-X),以最小化将手部关节拉向这些 3D 目标的运动学损失,同时结合重建损失、先验损失、脚部滑动损失和碰撞损失。运动学损失定义为:
Lk=t=1∑Tj∈Kt∑∥Jj(θ(t))−Kj(t)∥22,其中 Kj(t) 表示推导出的 3D 接触目标。这确保了无需多视图输入即可实现物理合理的交互。
实验
- 在零样本可动人机交互合成方面的综合实验验证,所提出的方法在几何一致性、物理合理性和时间连贯性方面均优于最先进(SOTA)的基线方法。
- 交互质量评估表明,该方法生成的脚部接触更真实,手 - 物接触率更高,物理穿透更少,同时保持了具有竞争力的运动平滑度。
- 可动物体动力学测试证实,该框架能够准确从单目视频中恢复关节旋转,显著优于专为可动物体估计设计的专用方法。
- 在刚性物体上的实验表明,基于重建的合成具有有效的泛化能力,在接触精度和物理合理性方面优于仅依赖深度先验或视频扩散的方法。
- 针对多样化参与者的用户研究表明,参与者强烈偏好所提出的方法而非所有基线方法,特别是在交互的真实感和接触质量方面。
- 消融研究证实,两阶段解耦优化、可动正则化和运动学损失是关键组件,移除它们会导致收敛不稳定、几何漂移以及人机接触错位。