Command Palette
Search for a command to run...
DARE:通过分布感知检索将LLM Agents与R统计生态系统对齐
DARE:通过分布感知检索将LLM Agents与R统计生态系统对齐
Maojun Sun Yue Wu Yifei Xie Ruijian Han Binyan Jiang Defeng Sun Yancheng Yuan Jian Huang
摘要
大型语言模型(LLM)智能体虽能自动化数据科学工作流,但由于 LLM 在统计知识与工具检索方面存在局限,许多在 R 语言中实现的高严谨性统计方法仍未得到充分利用。现有的检索增强方法多聚焦于函数级语义,而忽视了数据分布特征,导致检索匹配效果次优。为此,我们提出了 DARE(Distribution-Aware Retrieval Embedding,分布感知检索嵌入),这是一种轻量级、即插即用的检索模型,通过将数据分布信息融入函数表示,以优化 R 语言包的检索效果。本文的主要贡献包括:(i)RPKB,一个源自 8,191 个高质量 CRAN 包的精选 R 包知识库;(ii)DARE,一种融合分布特征与函数元数据的嵌入模型,旨在提升检索相关性;(iii)RCodingAgent,一个面向 R 语言的 LLM 智能体,支持可靠的 R 代码生成,并配套一套统计分析任务,用于在真实分析场景中系统评估 LLM 智能体的性能。实证结果表明,DARE 在包检索任务上的归一化折损累计增益(NDCG@10)达到 93.47%,在参数量显著更少的情况下,性能较当前最先进的开源嵌入模型提升了高达 17%。将 DARE 集成至 RCodingAgent 后,下游分析任务的性能亦获得显著提升。本研究有效缩小了 LLM 自动化能力与成熟的 R 统计生态之间的差距。
一句话总结
来自多个机构的研究人员提出了 DARE,这是一种轻量级检索模型,它独特地将数据分布特征与函数元数据相结合,以增强 R 包的搜索能力。该方法显著优于现有方法,并驱动了 RCodingAgent,弥合了大语言模型(LLM)自动化与成熟的 R 统计生态系统之间的差距。
主要贡献
- 作者提出了 DARE,这是一种轻量级嵌入模型,它将数据分布特征与函数元数据融合以提高检索相关性;同时推出了 RPKB,这是一个包含 8,191 个高质量 CRAN 包的精选知识库。
- 作者提出了RCodingAgent,一个面向 R 语言的 LLM 智能体,支持可靠的 R 代码生成,并配套一套统计分析任务,用于在真实分析场景中系统评估 LLM 智能体的性能
- 实证结果表明,DARE 在包检索任务上的 NDCG@10 达到 93.47%,比最先进模型高出最多 17%;将其集成到 RCodingAgent 中,使下游分析任务的性能提升了最多 56.25%。
引言
大语言模型代理正越来越多地用于自动化数据科学工作流,但由于训练数据偏向 Python 以及对统计工具兼容性缺乏理解,它们难以利用 R 生态系统中可用的严谨统计方法。先前的检索增强方法之所以失败,是因为它们仅依赖查询与函数描述之间的语义相似性,而忽略了决定统计方法是否适用的关键数据分布特征(如稀疏性或维度)。为了解决这一问题,作者提出了 DARE,这是一种轻量级检索模型,它将数据分布特征与函数元数据融合以改进 R 包选择,同时推出了 RPKB 知识库和用于端到端统计分析的 RCodingAgent 框架。
数据集
-
数据集构成与来源 作者通过从综合 R 档案网络(CRAN)中精选 R 包,构建了一个名为 RPKB 的专用知识库。最终仓库包含 8,191 个高质量的 R 函数,这些函数已索引至 ChromaDB,严格聚焦于核心统计原语和计算算法,同时排除了通用实用函数或描述模糊的函数。
-
每个子集的关键细节 数据集在函数级别进行组织,并辅以合成的元数据。每个条目包含函数描述、用法、参数和返回值等细粒度细节。关键在于,作者利用大语言模型为每个函数生成“数据画像”,推断出数据模态、分布假设、维度以及特定约束(例如处理缺失值或数据类型)等属性。
-
模型使用与训练策略 作者利用该语料库训练了一个用于统计编程的语义搜索引擎。他们采用了一种数据增强策略,即让大语言模型为每个函数生成 30 个多样化的用户风格搜索查询。这些提示旨在描述数据问题和约束,而不透露函数或包名称,确保模型学会基于分析意图而非关键词匹配来检索工具。
-
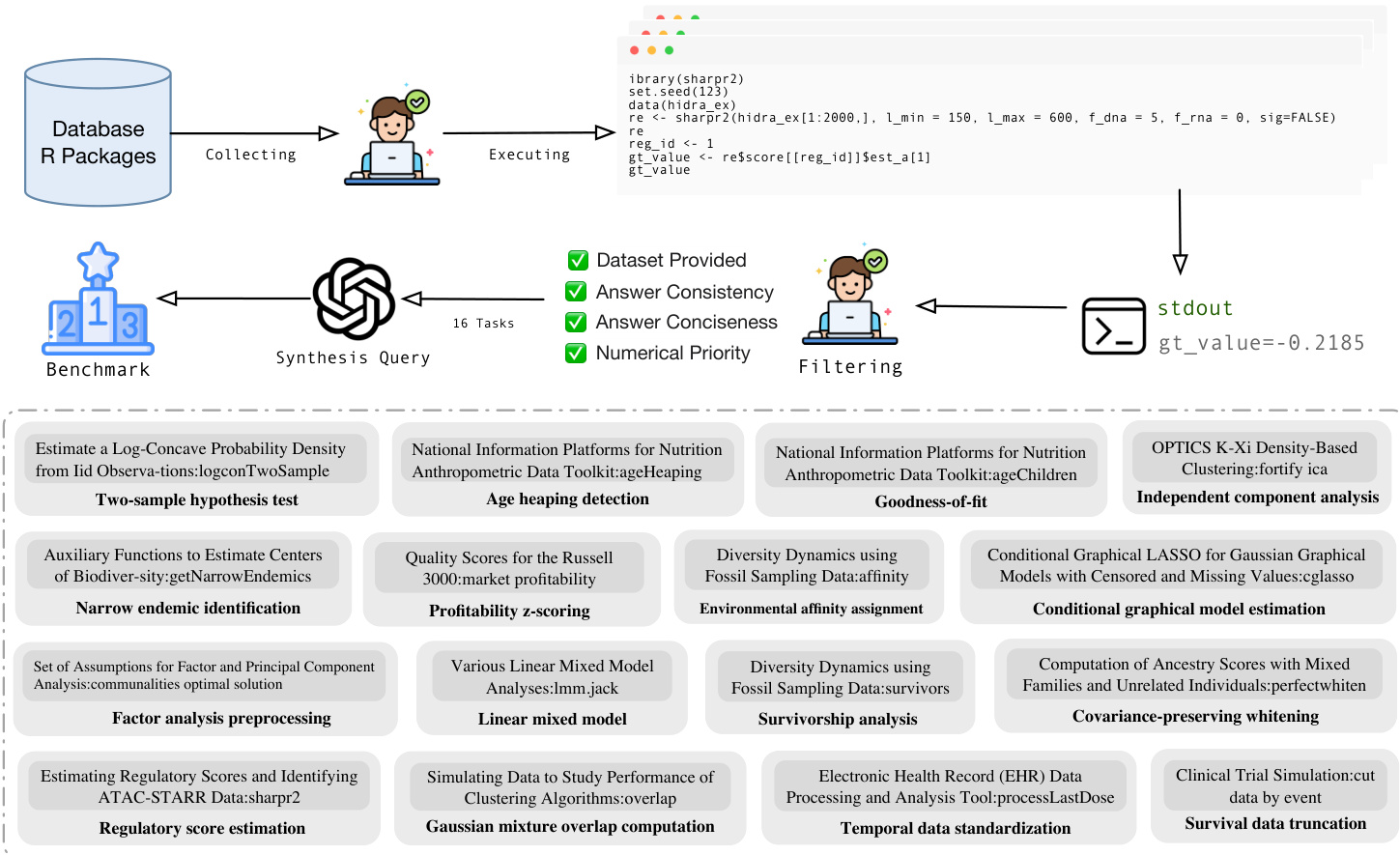
处理与评估框架 为了进行评估,团队创建了一个包含 16 个代表性统计分析任务的基准测试,涵盖假设检验和生存分析等领域。他们从仓库中提取真实的 R 脚本,执行它们以验证真实输出,然后提示大语言模型生成与这些验证结果配对的自然语言查询。评估查询强制执行严格约束,例如要求特定的随机种子,并强制打印特定的真实指标,以确保可重复性并准确评估代理性能。
方法
提出的框架 DARE 通过结合结构化数据画像与自然语言描述,解决了标准语义检索的局限性。如框架图所示,该系统与仅依赖函数描述的传统方法形成对比。相反,DARE 将检索过程建立在用户的自然语言查询和源自数据集特征的结构化数据画像之上。
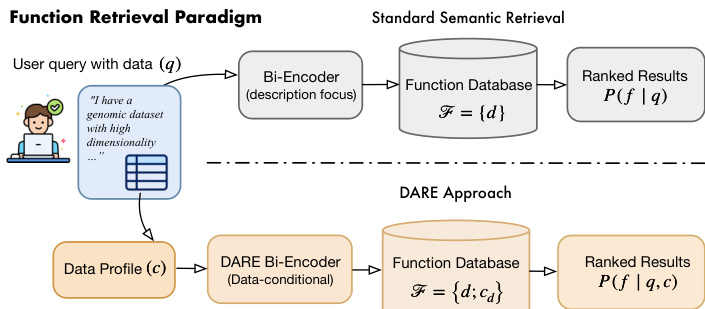
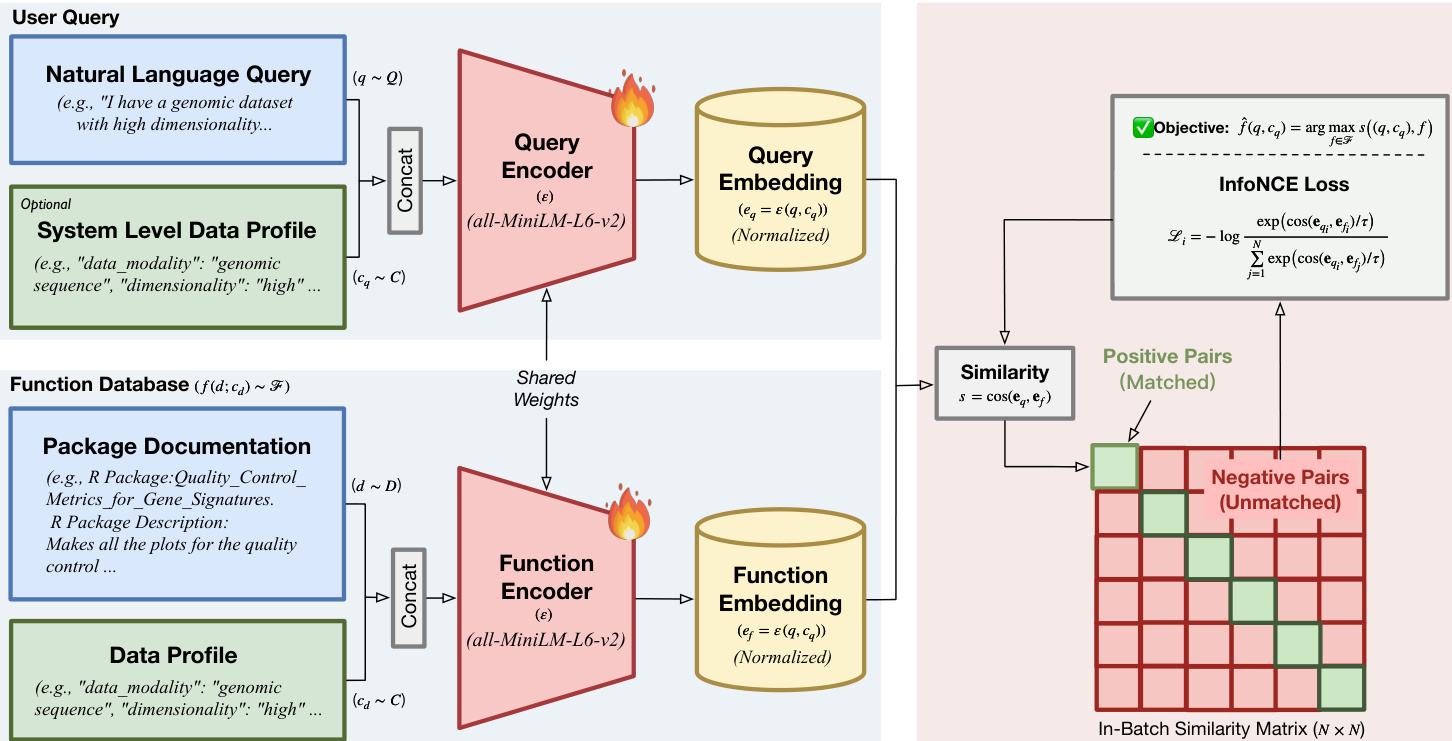
该方法的核心利用了一个具有共享权重的双编码器架构,该架构从预训练的句子转换器初始化。作者将共享编码器网络定义为 ε(⋅),它将输入文本映射到共享向量空间。对于查询端,系统将自然语言请求 q 与查询端数据画像 cq 拼接,生成查询嵌入 eq=ε([q;cq])。同样,对于函数数据库,每个候选函数由其文档 d 及其固有的数据画像 cd 表示,生成功数嵌入 ef=ε([d;cd])。相关性得分使用这些表示之间的余弦相似度计算:
s(eq,ef)=cos(eq,ef)=∥eq∥2∥ef∥2eq⊤ef.这种分解使得可以通过对预计算的函数嵌入进行最大内积搜索来实现高效检索。为了训练模型,作者采用了带有批内负样本的 InfoNCE 目标。给定大小为 N 的小批量,第 i 个样本的损失函数将配对的函数视为正样本,将批次中所有其他函数视为负样本:
Li=−logj=1∑Nexp(cos(eqi,efj)/τ)exp(cos(eqi,efi)/τ),其中 τ 是一个可学习的温度参数。如下图所示,该过程涉及将用户查询和函数文档编码为嵌入,计算批内相似度矩阵,并优化目标以最大化匹配对的相似度,同时最小化不匹配对的相似度。
为了促进端到端的统计分析,检索模块被集成到一个名为 RCodingAgent 的基于大语言模型的代理中。该代理首先调用 DARE 来检索满足分析意图和数据兼容性约束的候选 R 包和函数。检索到的函数会附带结构化元数据(包括参数规范和用法示例)返回,并注入到大语言模型的上下文中。这使得代理能够执行迭代推理、工具检索和 R 代码生成。该工作流展示了代理如何处理用户查询、检索最相关的函数,并执行编码步骤以生成最终观察结果。

该系统使用一个基准测试管道进行评估,该管道收集 R 包并合成查询以测试检索和执行能力。该管道涉及从数据库收集函数、执行代码以生成真实输出,并根据数据集提供、答案一致性和数值优先级等标准过滤结果。该基准测试涵盖了多样化的统计任务,包括假设检验、密度估计和数据转换,确保全面评估检索系统处理复杂数据科学工作流的能力。
实验
- 合成查询生成和检索基准测试验证了 DARE 在识别和排名统计函数方面达到了最先进性能,通过有效区分统计相似但分布不同的工具,显著优于更大的通用嵌入模型。
- 效率分析表明,与重型基线相比,DARE 提供了更高的吞吐量和超低延迟,证实了其适用于需要快速工具检索的实时代理工作流。
- 在统计分析任务上针对不同大语言模型代理的集成实验显示,DARE 大幅提高了端到端成功率,通过提供精确的、感知分布的检索信号,有效弥合了轻量级和前沿模型在工具利用方面的差距。