Command Palette
Search for a command to run...
Helios:实时长视频生成模型
Helios:实时长视频生成模型
Shenghai Yuan Yuanyang Yin Zongjian Li Xinwei Huang Xiao Yang Li Yuan
摘要
我们推出了 Helios,这是首个在单块 NVIDIA H100 GPU 上以 19.5 FPS 速度运行、支持分钟级视频生成,且质量媲美强基线模型的 140 亿参数(14B)视频生成模型。我们在三个关键维度上取得了突破性进展:(1)无需依赖常见的抗漂移启发式方法(如自强制、误差缓存或关键帧采样),即可实现对长视频生成中漂移现象的鲁棒性;(2)无需采用标准加速技术(如 KV 缓存、稀疏/线性注意力机制或量化),即可实现实时生成;(3)无需并行训练或分片框架,即可在 80 GB GPU 显存内部署多达四个 14B 模型,同时达到图像扩散模型级别的批量大小。具体而言,Helios 是一个 14B 自回归扩散模型,采用统一的输入表示,原生支持文生视频(T2V)、图生视频(I2V)和视频生视频(V2V)任务。为缓解长视频生成中的漂移问题,我们系统分析了典型的失效模式,并提出简洁而有效的训练策略:在训练过程中显式模拟漂移现象,同时从源头上消除重复运动。在效率方面,我们对历史上下文和噪声上下文进行高度压缩,并减少采样步数,使计算成本与 13 亿参数(1.3B)视频生成模型相当甚至更低。此外,我们引入了基础设施层面的优化措施,在降低显存占用的同时,显著加速了推理与训练过程。大量实验表明,Helios 在短视频与长视频生成任务中均持续优于现有方法。我们计划开源代码、基础模型及蒸馏模型,以支持社区进一步开发与研究。
一句话总结
北京大学与字节跳动的研究人员推出了 Helios,这是一个 140 亿参数的自回归扩散模型,无需标准加速启发式算法即可实现实时、分钟级的视频生成。通过在训练中模拟漂移并压缩上下文,该模型在有限的 GPU 显存下可部署多个模型,且性能优于以往方法。
主要贡献
- Helios 通过训练策略显式模拟漂移并在源头解决重复运动问题,消除了自强制(self-forcing)和误差库(error-banks)等常见的抗漂移启发式算法,从而解决了实时、分钟级视频生成的挑战。
- 该模型通过压缩历史上下文并重构流匹配(flow matching),将计算成本降低至与 13 亿参数模型相当的水平,在单块 NVIDIA H100 GPU 上实现了 19.5 FPS 的实时速度,且无需标准加速技术。
- 大量实验表明,Helios 在短视频和长视频上均 consistently 优于以往方法,同时支持无需并行框架的训练,并能在 80 GB GPU 显存内容纳多达四个 140 亿参数的模型。
引言
实时、分钟级视频生成的需求对于游戏引擎等交互式应用至关重要,但现有模型难以在速度、时长和质量之间取得平衡。以往的方法通常依赖缺乏复杂运动表现能力的 13 亿小模型,或者依赖自强制和 KV 缓存等昂贵技术来防止时间漂移并加速推理。作者推出了 Helios,这是一个 140 亿参数的自回归扩散模型,在单块 H100 GPU 上实现了 19.5 FPS 的速度,同时支持长视频生成,且无需标准加速或抗漂移启发式算法。他们通过在训练中显式模拟漂移以消除运动伪影、压缩历史上下文以降低计算负载,以及在一个高效的架构中统一文本到视频(T2V)、图像到视频(I2V)和视频到视频(V2V)任务,解决了这些挑战。
方法
作者提出了 Helios,这是一种自回归视频扩散 Transformer,旨在单块 GPU 上实现实时长视频生成。整体框架如架构图所示。该模型通过将历史上下文 XHist 与噪声上下文 XNoisy 拼接,将长视频生成视为视频续写任务。这种设计促进了表示控制(Representation Control),使系统能够统一文本到视频(T2V)、图像到视频(I2V)和视频到视频(V2V)任务。如果历史上下文为零,模型执行 T2V;如果仅最后一帧非零,则执行 I2V;否则执行 V2V。为了处理历史上下文和噪声上下文的不同统计特性,作者在 DiT 块中引入了引导注意力(Guidance Attention)。该机制明确区分了对干净历史帧和噪声未来帧的处理。在自注意力层中,历史键(keys)通过放大令牌(amplification tokens)进行调制,以选择性地增强其对未来帧生成的影响。在交叉注意力层中,文本提示的语义信息仅注入到噪声上下文中以避免冗余,因为历史上下文已经包含了这些语义。
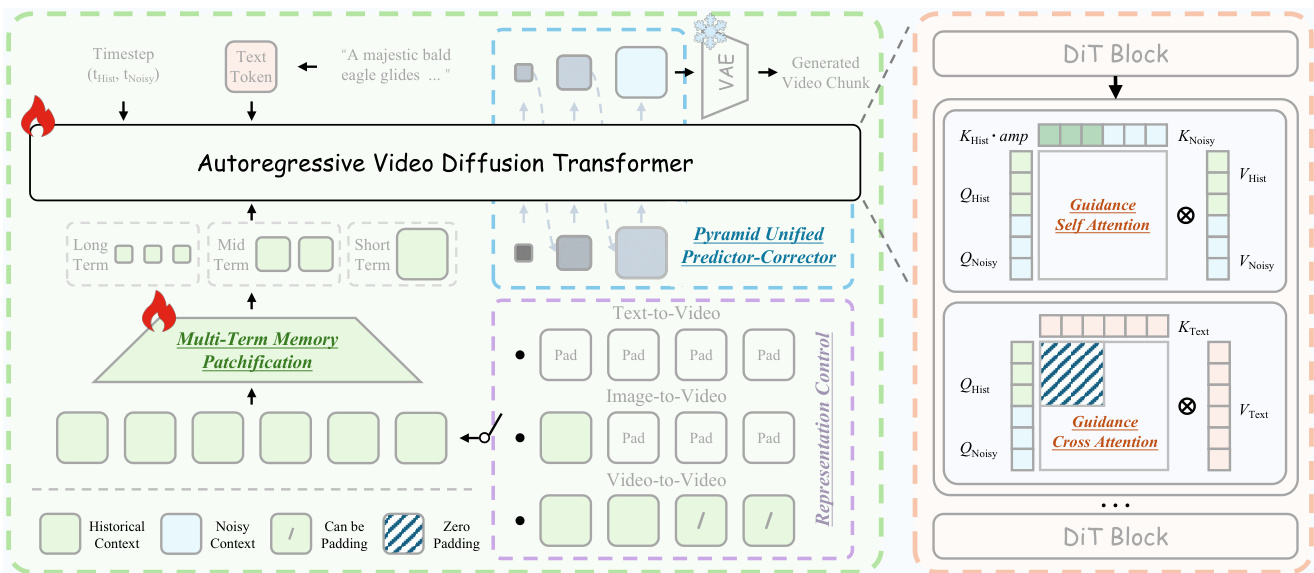
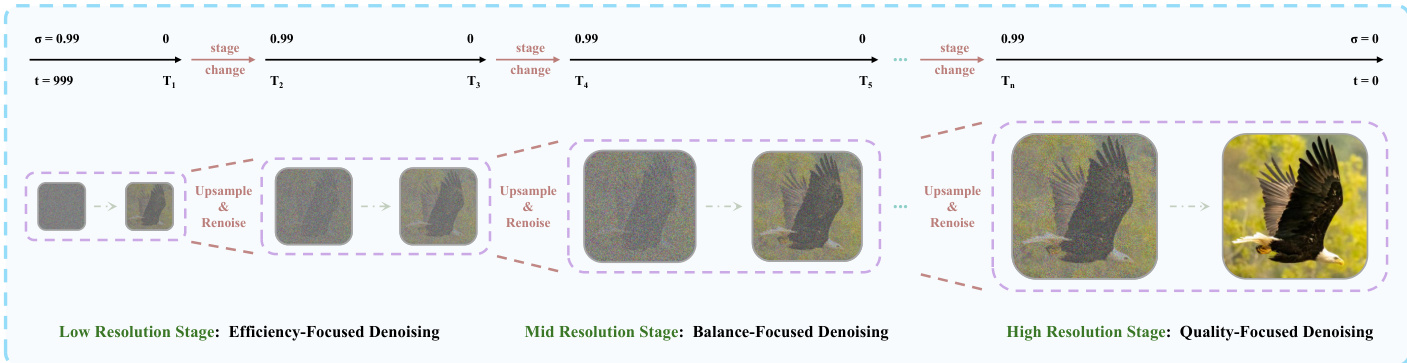
为了降低与大上下文窗口相关的计算开销,作者采用了深度压缩流(Deep Compression Flow)。该策略包含两个主要模块。首先,多期限记忆分块(Multi-Term Memory Patchification)通过将历史上下文划分为短期、中期和长期窗口来压缩历史上下文。对每个部分应用独立的卷积核,且随着时间距离的增加,压缩比也随之提高,从而无论视频长度如何都保持恒定的令牌预算。其次,金字塔统一预测校正器(Pyramid Unified Predictor Corrector)减少了噪声上下文中的冗余。如下图所示,生成过程被划分为多个具有递增空间分辨率的阶段。模型首先从低分辨率去噪开始,以高效地建立全局结构,然后逐步过渡到全分辨率以细化细粒度细节。这种由粗到细的调度显著减少了早期采样步骤中处理的令牌数量。
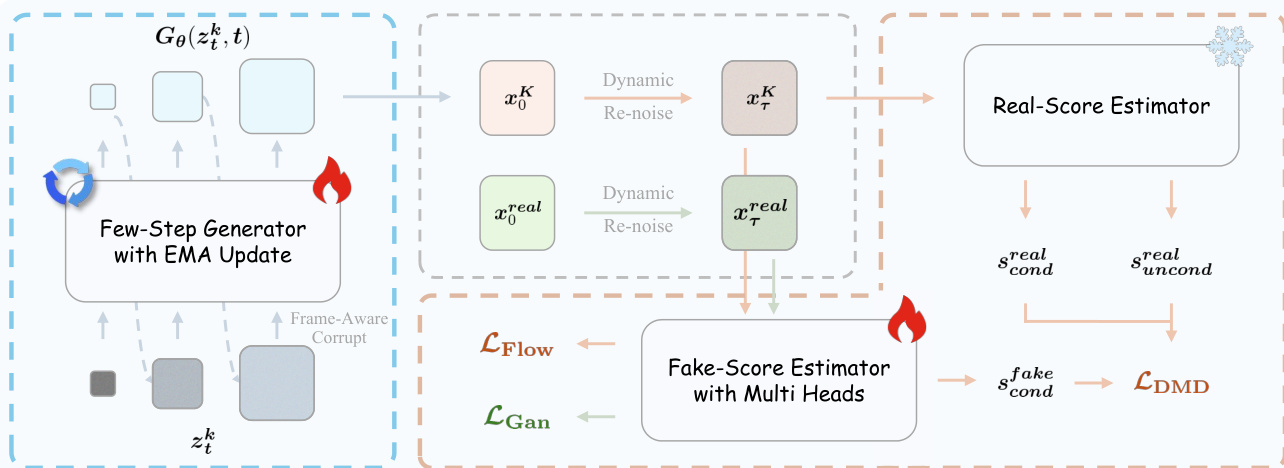
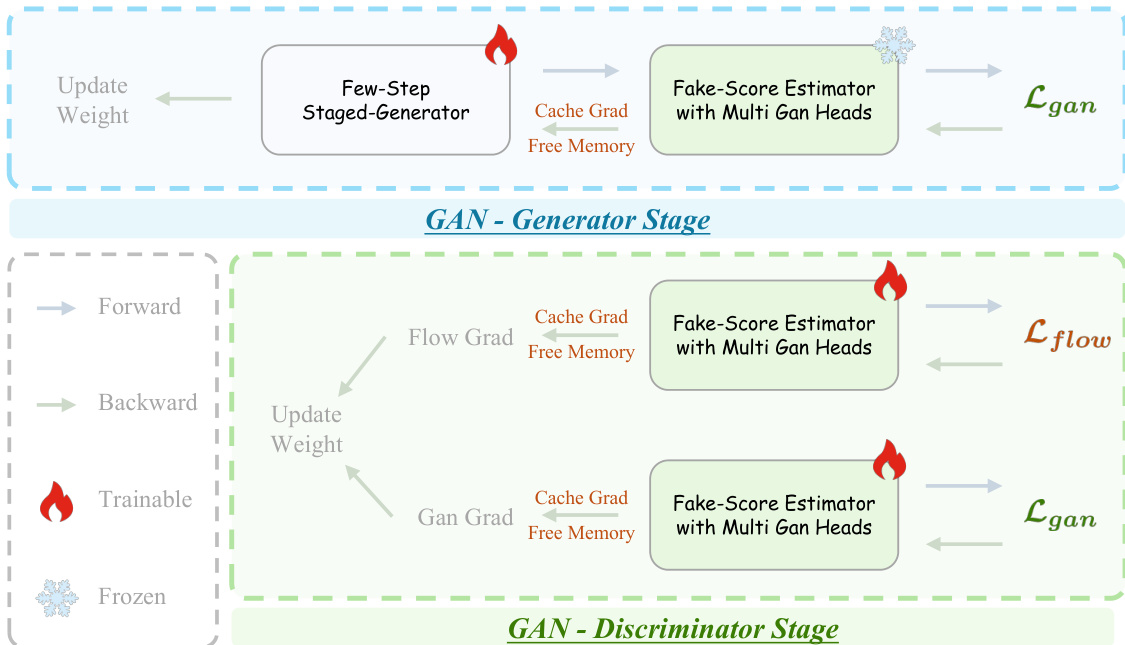
训练过程利用对抗性分层蒸馏(Adversarial Hierarchical Distillation),将多步教师模型蒸馏为少步学生生成器。该流程如蒸馏框架图所示。系统采用带有 EMA 更新的少步生成器(Few-Step Generator)以及两个分数估计器:真实分数估计器和具有多头的虚假分数估计器。生成器利用源自真实分数与虚假分数之差的分布匹配损失(LDMD),结合流匹配损失(LFlow)和 GAN 损失(LGan)进行优化。为了解决训练大模型时的显存限制,作者在 GAN 阶段实施了特定的优化策略。训练阶段在显存优化图中有详细说明,该图突出了缓存梯度(Cache Grad)的使用。通过缓存判别器相对于输入的梯度,系统将反向传播与前向传播解耦,允许提前释放中间激活值。这种方法大幅降低了峰值显存占用,使得在有限硬件上训练 140 亿参数模型成为可能。
实验
- Helios 无需依赖常见的抗漂移策略或标准加速技术即可生成高质量、连贯的分钟级视频,在单块 GPU 上实现了实时推理速度。
- 对比实验表明,Helios 在视觉保真度、文本对齐度和自然度方面优于现有的蒸馏模型和基础模型,同时保持了卓越的运动平滑度并避免了时间抖动。
- 长视频评估证实,Helios 显著减少了内容漂移,并在数百帧内保持了场景一致性,在吞吐量和一致性方面均超越了基线方法。
- 用户研究验证,无论是短片段还是长片段,用户始终更倾向于选择 Helios 而非以往的实时视频生成模型。
- 消融研究表明,引导注意力(Guidance Attention)、首帧锚点(First Frame Anchor)和帧感知破坏(Frame-Aware Corrupt)等关键组件对于防止语义累积、保持颜色一致性和减轻长序列中的误差传播至关重要。
- 多期限记忆分块(Multi-Term Memory Patchification)和金字塔统一预测校正器(Pyramid Unified Predictor Corrector)等架构选择实现了可扩展的显存使用,并在不牺牲视频质量的情况下使吞吐量翻倍。
- 包括由粗到细学习(Coarse-to-Fine Learning)和对抗性后训练(Adversarial Post-Training)在内的训练策略对于稳定收敛以及超越纯蒸馏限制以增强感知真实感至关重要。