Command Palette
Search for a command to run...
MMR-Life:为多模态多图像推理拼合真实场景
MMR-Life:为多模态多图像推理拼合真实场景
Jiachun Li Shaoping Huang Zhuoran Jin Chenlong Zhang Pengfei Cao Yubo Chen Kang Liu Jun Zhao
摘要
近年来,多模态大语言模型(MLLMs)在推理能力方面的进展,使其能够应对更为复杂的任务,如科学分析与数学推理。然而,尽管前景广阔,MLLMs在真实生活场景中不同情境下的推理能力仍缺乏系统性探索,且尚未建立标准化的评估基准。为填补这一空白,我们提出 MMR-Life——一个全面的基准测试集,旨在评估 MLLMs 在真实场景下处理多图像、多模态推理任务的多样化能力。MMR-Life 包含 2,646 道多项选择题,基于 19,108 张主要来源于现实世界情境的图像,全面覆盖七类推理类型:溯因推理(abductive)、类比推理(analogical)、因果推理(causal)、演绎推理(deductive)、归纳推理(inductive)、空间推理(spatial)与时间推理(temporal)。与现有推理基准不同,MMR-Life 不依赖特定领域的专业知识,而是要求模型在多张图像之间整合信息,并综合运用多种推理能力。对 37 个先进模型的评估结果显示,MMR-Life 提出了显著挑战:即使顶尖模型如 GPT-5,准确率也仅达到 58%,且在不同推理类型间表现出显著的性能差异。此外,我们进一步分析了现有 MLLMs 的推理范式,深入探讨了推理长度、推理方法及推理类型等因素对其性能的影响。综上所述,MMR-Life 为下一代多模态推理系统的研究提供了全面的评估、分析与优化基础,推动该领域向更真实、更复杂的应用场景发展。
一句话总结
来自中国科学院大学和中科院的研究人员推出了 MMR-Life,这是一个包含 2,646 道题、涵盖七种推理类型的现实世界多模态基准,用于评估包括 GPT-5 在内的 37 个模型;该基准揭示了多图像推理中的关键缺陷,并为超越领域特定任务的下一代多模态大语言模型(MLLM)发展指明方向。
主要贡献
- 研究团队推出了 MMR-Life,这是首个全面评估现实场景中多图像多模态推理能力的基准,包含基于 19,108 张真实世界图像的 2,646 道题,涵盖七种推理类型——溯因、类比、因果、演绎、归纳、空间和时间推理——无需领域专业知识。
- 对包括 GPT-5 和 Gemini-2.5-Pro 在内的 37 个最先进 MLLM 的评估显示,性能差距显著,最佳模型准确率仅约 58%,且在不同推理类型间表现差异巨大,尤其在因果、空间和时间推理上表现较差。
- 通过 MMR-Life 的深入分析,作者揭示了 MLLM 推理范式的若干关键洞察,例如延长思考长度对多数推理类型帮助有限、推理行为呈现聚类特征,为改进下一代多模态系统提供了可行方向。
引言
作者利用多模态大语言模型(MLLM)日益增强的能力应对复杂推理任务,但指出当前大多数基准要么聚焦专家级知识,要么依赖合成谜题——两者均与现实世界视觉推理脱节,后者通常涉及多张图像和常识逻辑。先前工作也大多忽略多图像输入或仅限于狭窄推理类型,未能捕捉日常场景的多样性。其主要贡献是 MMR-Life,一个包含 2,646 道题、涵盖七种推理类型(溯因、类比、因果、演绎、归纳、空间、时间)的新基准,所有题目均基于真实生活图像集。对 37 个最先进模型的评估显示,即使像 GPT-5 这样的顶尖模型也表现不佳,准确率仅 58%,且在因果、空间和时间推理上存在显著弱点,凸显当前 MLLM 能力的关键缺口。
数据集

作者使用 MMR-Life,一个专为评估 MLLM 在现实推理任务中表现而设计的新型多模态基准。以下是数据集的结构和使用方式:
-
组成与来源:
MMR-Life 包含 2,646 道基于 19,108 张真实世界图像的多项选择题,覆盖 7 种推理类型(溯因、类比、因果、演绎、归纳、空间、时间)和 21 项任务。图像来源包括:- 公开数据集(如 Kaggle),提供高分辨率、上下文相关的图像
- 网页截图(如 eBird 的鸟类分布图)
- 公开视频帧,经提取和筛选以确保清晰度
- 现有涉及多图像或视频推理的基准
所有图像均为自然照片——不包含符号图或人工图形。
-
关键子集细节:
- 每道题至少需要两张图像。
- 题目通过自动化规则(针对显式视觉线索)或人工标注(针对隐式推理)生成。
- 每题五个选项:一个正确,四个错误。错误选项通过启发式采样(图像选择类)或大语言模型(GPT-5-mini、GPT-4o、Qwen2.5-VL-32B)生成并经人工优化。
- 最初生成 3.2K 个问答对;经质量控制筛选后保留 2,646 道题。
- 筛选步骤:
- 难度:移除被 3 个小型 MLLM(Qwen2.5-VL-7B、Gemma3-4B、InternVL3.5-8B)正确回答的题目。
- 格式:人工修订使错误选项在长度和结构上与正确选项对齐。
- 质量:合著者审核并移除模糊、多答案或需领域专业知识的题目。
-
训练/实验用途:
- 数据集仅用于评估,不用于训练。
- 未使用混合比例或训练划分;所有模型均在完整基准上测试。
- 论文未提及裁剪或缩放;图像按原样使用,提取时优先保证质量和清晰度。
-
处理与元数据:
- 所有标注遵循严格指南:仅限英文、无需领域专业知识、无歧义、与推理类型定义一致。
- 元数据包括推理类型、来源和每题图像数量。
- 伦理合规:无版权、私人或有害内容;无众包;所有标注者均为自愿参与。
- 可复现性:完整数据源、标注提示和 210 道题子集在附录和补充材料中提供。
方法
作者采用结构化提示框架引导多模态推理模型处理涉及多张图像的复杂任务。该框架旨在强制统一输出格式,同时鼓励逐步推理,这对于生成可靠的干扰项和验证正确答案至关重要。每个提示模板均针对特定输出结构定制,确保模型响应符合任务预期的语义和句法约束。
例如,在生成推理任务的干扰项时,作者采用一系列逐步约束输出格式的提示。其中一个提示要求模型输出“x-x-x-x…”格式的图像索引序列,其中每个“x”对应输入图像集中的特定图像。这种结构化输出便于下游评估并与真实序列比较。

另一种提示变体限制输出为方向性响应,要求模型从预定义的八个常见方向中选择。这种约束在导航或空间推理任务中尤为有用,因为方向精度至关重要。

在需要顺序动作规划的任务中,作者引入编号动作格式,要求每一步以整数开头,并从有限动作集合(如“左转”、“右转”或“向前直行直到 xxx”)中选择。这确保生成的序列在语义上有效且可执行。

对于多项选择题作答,作者采用链式思维(CoT)风格提示,明确指示模型从固定选项(A/B/C/D/E)中选择。该格式不仅标准化输出,还鼓励模型在最终选择前阐明其推理过程。

在所有提示变体中,作者始终包含指令“让我们逐步思考后再作答”,作为激活模型推理能力的元指令。这一设计选择反映了通过结构化输出约束和明确推理提示来搭建复杂推理的刻意努力。
实验
- MMR-Life 基准揭示了当前 MLLM 与人类表现之间的显著差距,尤其在现实推理场景中,即使像 GPT-5 这样的顶尖模型得分也比人类低 14%。
- 模型在类比和演绎推理中表现强劲,但在空间、时间和因果推理上显著挣扎,凸显其偏向模式关联而非抽象世界建模。
- “思考”模式提升闭源模型表现,但对开源模型几乎无益,表明当前开源思考框架在现实世界场景中缺乏泛化能力。
- 总体上,更长推理链与更高准确率呈对数相关,但此效益因任务而异——归纳推理常随扩展 CoT 而退化,而类比推理则改善。
- 标准推理增强方法如 BoN 和 GRPO 在更大模型上收益递减甚至性能下降,表明其泛化能力随模型规模增长受限。
- 强化学习方法在小模型上表现不如推理时技术(如 Best-of-N),引发对 RL 在推理泛化中有效性的质疑。
- 推理类型间相关性各异;类比和归纳推理高度相关,而空间推理独立,暗示其底层认知模式不同。
- 对顶尖模型的错误分析揭示主要失败在于逻辑推理(如因果倒置、时间混淆)、抽象、知识回忆和感知,指向当前 MLLM 的核心局限。
作者在 MMR-Life 基准上评估了 37 个多模态语言模型,发现即使像 GPT-5 这样的顶尖闭源模型在空间和时间推理上也显著落后于人类表现。虽然更长推理链通常与更高准确率相关,但此效益并非普遍适用,且随推理类型变化——例如归纳推理在扩展 CoT 时可能无改善甚至退化。开源思考模型相比其非思考对应模型几乎无优势,表明当前推理增强方法尚未在现实世界泛化中生效。
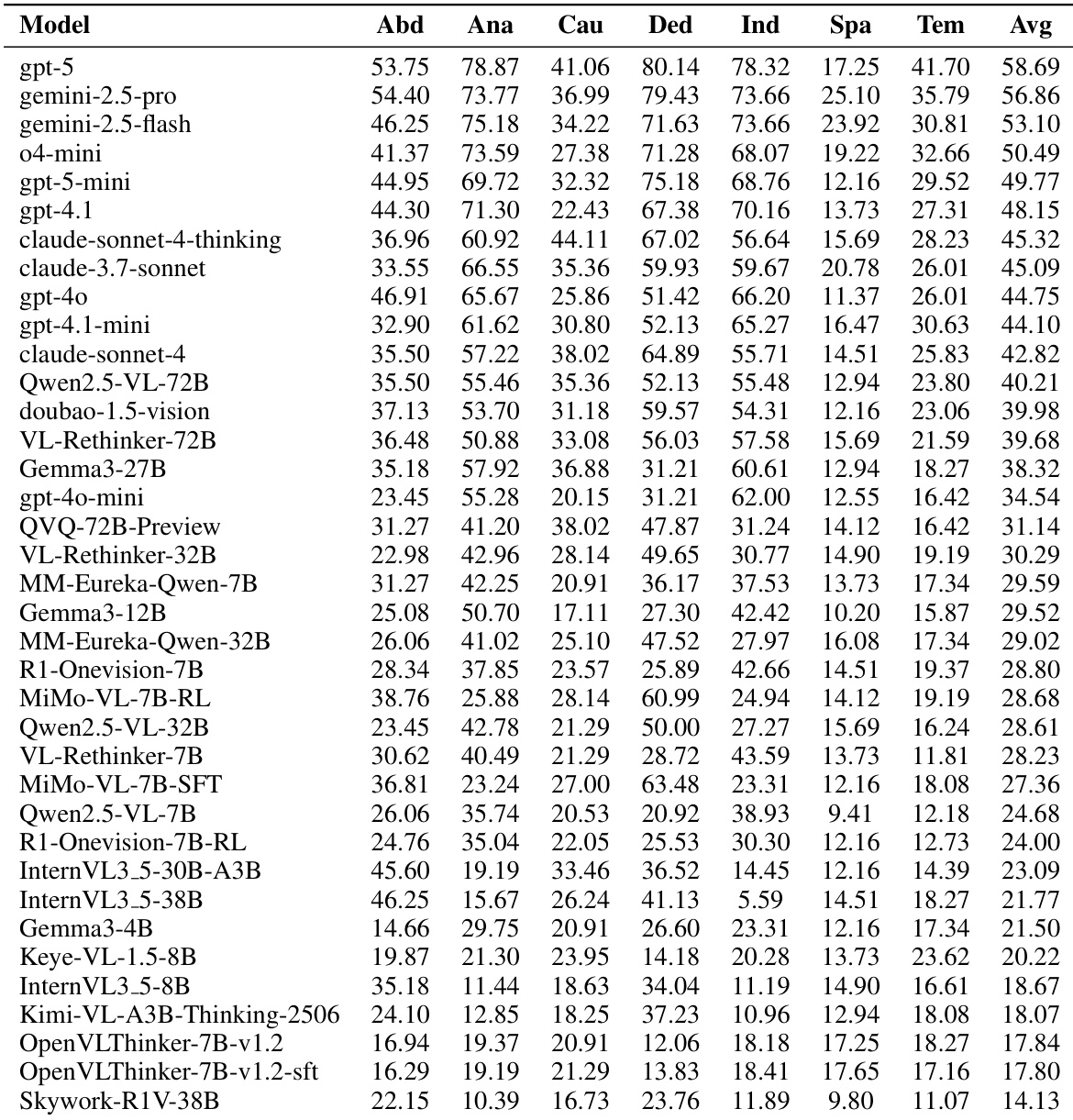
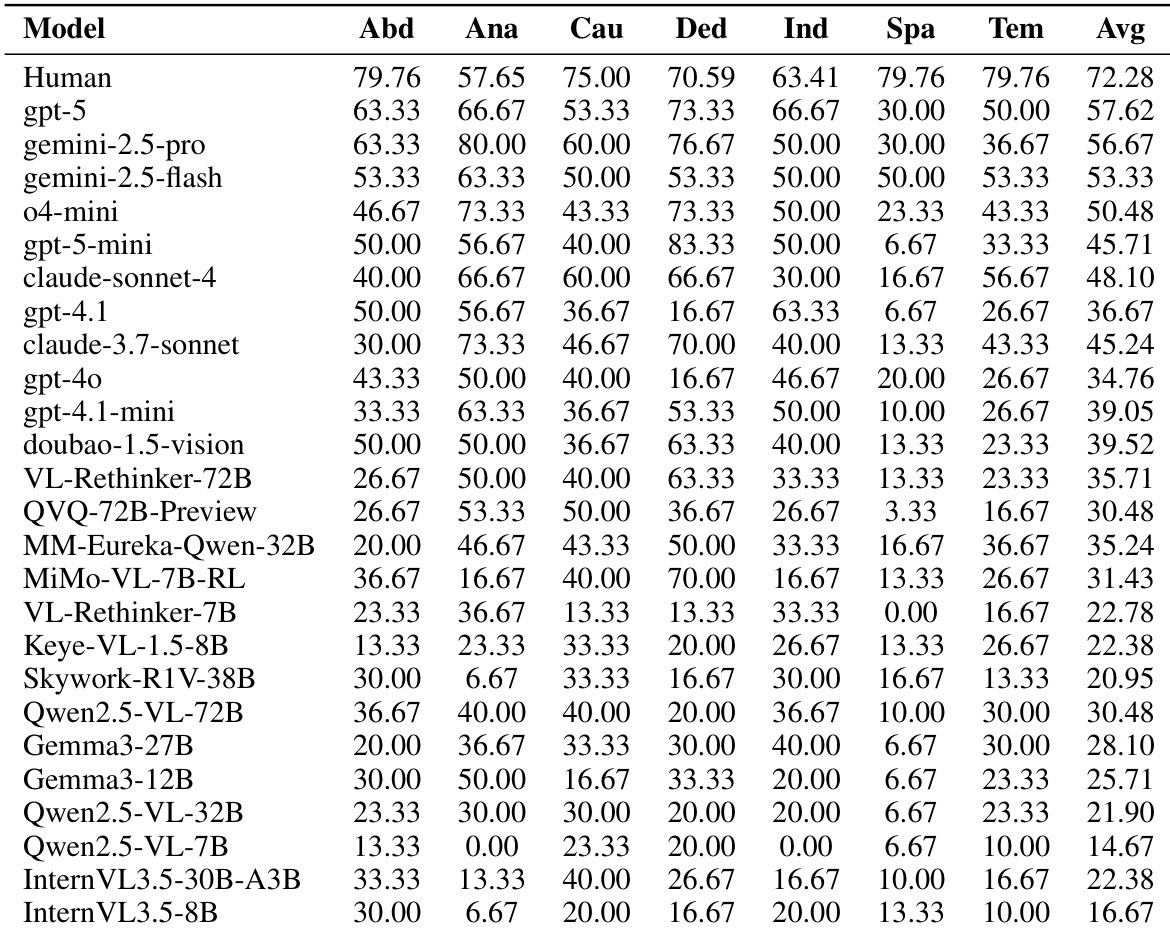
作者使用涵盖七种推理类型的 2,646 道题评估多模态语言模型,发现即使表现最佳的模型在现实推理任务上仍远逊于人类。结果表明空间和时间推理存在显著性能差距,而类比和演绎推理相对较好,凸显模型需更好学习抽象世界表征。当前开源思考模型未持续优于其非思考对应模型,表明尽管推理过程更长,但在现实世界场景中泛化能力仍有限。
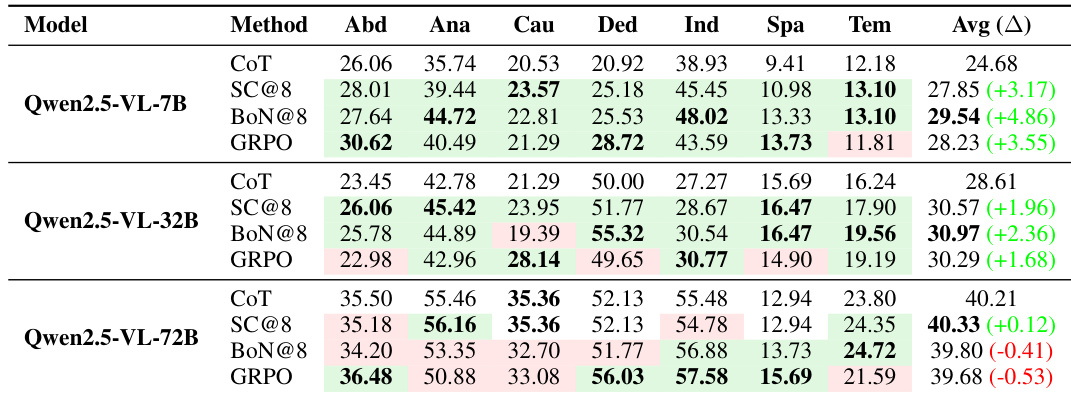
作者在不同规模的 Qwen2.5-VL 模型上评估多种推理增强方法,发现如 Self-Consistency 和 Best-of-N 等技术的性能增益随模型规模扩大而递减,更大模型在这些方法下有时表现甚至不如基础 CoT。对于 72B 模型,GRPO 和 BoN 未显示出对 CoT 的一致优势,表明高级推理方法可能难以泛化至更大架构。结果表明,仅靠模型规模无法保证推理能力提升,增强技术需谨慎匹配模型容量与任务类型。
作者在 MMR-Life 基准上评估了 37 个多模态语言模型,发现即使像 GPT-5 这样的顶尖闭源模型在空间和时间推理上也显著落后于人类表现。虽然思考模式提升闭源模型表现,但对开源模型几乎无益,且更长推理链未在所有推理类型中一致提升准确率。结果还显示,当前推理增强方法如 BoN 和 GRPO 在更大模型上收益递减甚至性能下降,凸显对更有效泛化技术的需求。
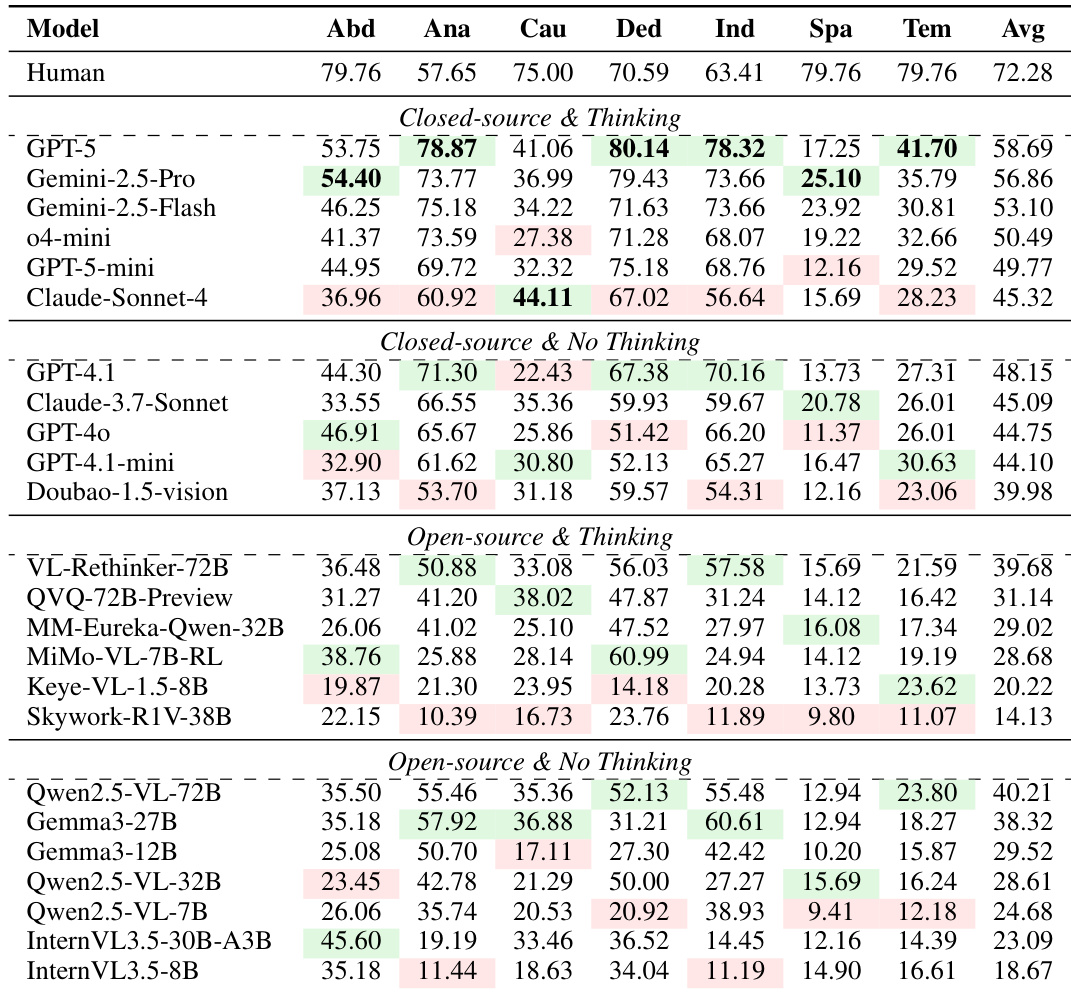
作者在 MMR-Life 基准上评估了 37 个多模态语言模型,发现即使像 GPT-5 这样的顶尖闭源模型在空间和时间推理上也显著落后于人类表现。虽然思考模式提升闭源模型表现,但对开源模型无一致益处,且更长推理链未在所有推理类型中普遍提升准确率。结果表明,当前模型尽管在类比和演绎任务中表现优异,但在抽象现实推理上仍挣扎,凸显需开发更适于日常场景泛化的训练方法。