Command Palette
Search for a command to run...
翻译复原:面向基准测试与数据集自动化翻译的高效流水线
翻译复原:面向基准测试与数据集自动化翻译的高效流水线
Hanna Yukhymenko Anton Alexandrov Martin Vechev
摘要
当前,多语言大型语言模型(LLM)评估的可靠性正受到翻译后基准测试质量不一致的严重影响。现有资源普遍存在语义漂移(semantic drift)和上下文丢失等问题,可能导致性能指标产生误导。针对这一挑战,本文提出一个完全自动化的框架,旨在实现数据集与基准测试的可扩展、高质量翻译。我们证明,通过引入测试时计算资源的动态扩展策略——特别是通用自提升(Universal Self-Improvement, USI)方法以及我们提出的多轮排序方法T-RANK,相较于传统流水线,能够显著提升翻译输出的质量。该框架在本地化过程中有效保留了原始任务结构与语言细微差异,确保了基准测试的语义完整性与语言准确性。我们已将该方法应用于将多个主流基准测试与数据集翻译为八种东欧及南欧语言(乌克兰语、保加利亚语、斯洛伐克语、罗马尼亚语、立陶宛语、爱沙尼亚语、土耳其语、希腊语)。通过基于参考文本的评估指标以及“大语言模型作为裁判”(LLM-as-a-judge)的评估方式,实验结果表明,我们的翻译成果显著优于现有资源,从而实现了更精准的下游模型评估。为推动多语言人工智能的稳健发展与可复现研究,我们已公开发布该翻译框架及优化后的基准测试数据集。
一句话总结
来自 INSAIT 和苏黎世联邦理工学院的 Hanna Yukhymenko、Anton Alexandrov 和 Martin Vechev 提出了 T-RANK,这是一种在自动化框架内的多轮排序方法,能够在将基准测试翻译为八种欧洲语言时保留语言细微差别,优于先前工具,从而实现更可靠的多语言大语言模型评估。
主要贡献
- 作者识别并分析了现有多语言基准测试中的关键缺陷,表明将问题与答案分别翻译会导致语义漂移和语境丢失,尤其在形态复杂的东欧和南欧语言中。
- 作者引入了一种完全自动化的翻译框架,结合了测试时扩展方法——特别是我们新颖的 T-RANK 排序方法和通用自我改进(Universal Self-Improvement)——以保留任务结构和语言细微差别,在八种目标语言中优于传统流水线。
- 作者发布了经过参考指标和“大语言模型作为评判者”评估验证的高质量翻译基准测试,涵盖乌克兰语、保加利亚语、斯洛伐克语、罗马尼亚语、立陶宛语、爱沙尼亚语、土耳其语和希腊语,从而实现更可靠且可复现的多语言大语言模型评估。
引言
作者利用大语言模型解决现有翻译多语言基准测试质量差的问题,这些问题通常由于依赖过时工具或简单方法而导致语义漂移和结构错位。先前的工作未能在翻译过程中保持任务完整性——尤其对于语法复杂的东欧和南欧语言——且缺乏可扩展、可配置的流水线。他们的主要贡献是一个完全自动化的框架,整合了先进的测试时扩展技术,包括通用自我改进和新颖的 T-RANK 方法,以生成高保真翻译并保留基准结构。他们发布了关键基准测试的八种目标语言版本,从而实现更准确、可复现的多语言模型评估。
数据集
-
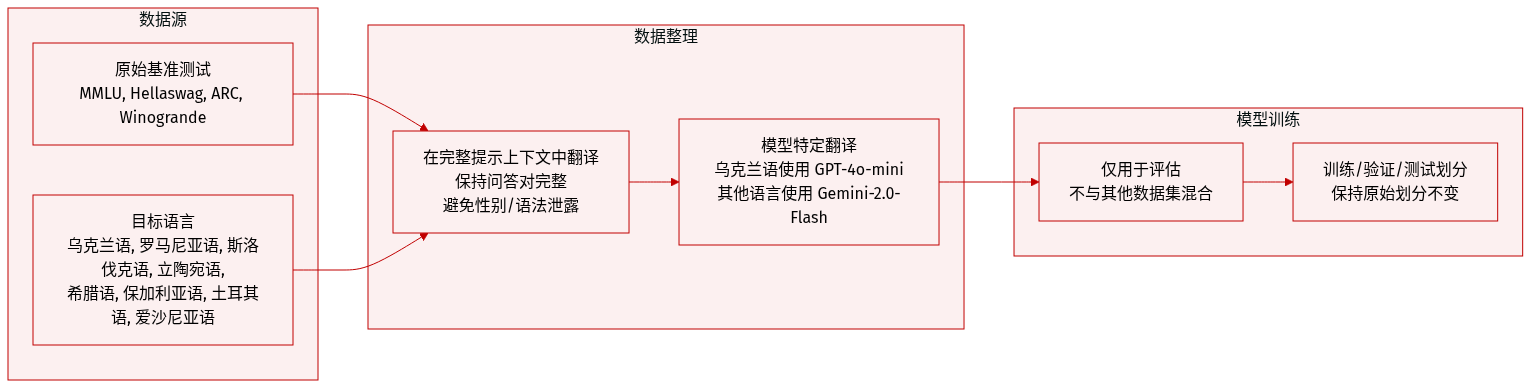
作者使用自定义翻译框架,将主要英语基准测试——MMLU、Hellaswag、ARC 和 Winogrande——适配为八种东欧和南欧语言:乌克兰语、罗马尼亚语、斯洛伐克语、立陶宛语、希腊语、保加利亚语、土耳其语和爱沙尼亚语,选择这些语言是因为它们语法复杂且属于中等资源语言。
-
对于乌克兰语,所有基准测试均使用 GPT-4o-mini-2024-07-18 进行翻译;对于其他目标语言,使用 Gemini-2.0-Flash。翻译在完整提示上下文中执行,以保持语义连贯性,并避免因性别化或语境依赖语法导致答案泄露。
-
数据集包含原始基准测试的完整训练、验证和测试划分,除标准基准划分外未进行任何过滤。翻译质量与先前工作(如 MuBench 和 Global-MMLU)进行对比评估,后者依赖上下文感知性较低的方法或部分人工审查。
-
未提及裁剪或元数据构建。重点在于提示级别的翻译保真度,确保问题与答案选项一起翻译,以保持任务完整性并避免无意的语言偏见。
-
作者未将该数据集与其他数据混合用于训练;它仅用于评估。翻译模型和方法详见附录 A.2,质量指标和比较详见附录 A.3。
方法
作者利用一个模块化、大语言模型驱动的翻译框架,旨在适应不同数据集和基准格式,采用不同的提示策略和数据处理方式以保持结构完整性——在基准测试中尤其关键,因为问题与答案的关系必须保持连贯。该框架支持四种可配置的翻译方法,每种方法均针对成本、质量和语言细微差别之间的不同权衡进行了优化。
第一种方法“自检”(Self-Check, SC)采用零样本翻译,随后可选地进行自我评估阶段。在此阶段,一个独立的大语言模型实例(无先前上下文访问权限)根据原文评估翻译结果并修正检测到的差异。该方法对高资源语言经济实用,但因模型过度修正倾向而可能引入幻觉错误。可启用少样本变体以引导模型规避特定语言的翻译陷阱。
“N选优采样”(Best-of-N sampling, BoN)基于测试时计算扩展原则,在较高温度(0.7)下生成 N 个多样化翻译,并提示大语言模型根据预定义标准对每个翻译进行 1–10 分评分。选择得分最高的候选翻译。虽然该方法语言无关且成本效率高,但受限于大语言模型在数值评分和位置偏差方面的局限性,常倾向于选择靠前的候选翻译,即使错误明显。
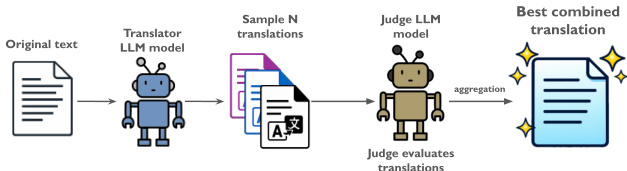
“通用自我改进”(Universal Self-Improvement, USI)基于自洽性和融合范式,认识到共识并不保证最优。如图所示,该方法采样 N 个翻译,然后指示一个评判大语言模型根据指定评估标准从所有候选翻译中提取最佳特征,合成一个更优版本。该融合步骤每条记录仅执行一次,仅需 N+1 次模型调用,并能有效解决语言特定的细微差别。工作流强调选择性聚合而非盲目合并,以减少错误传播。
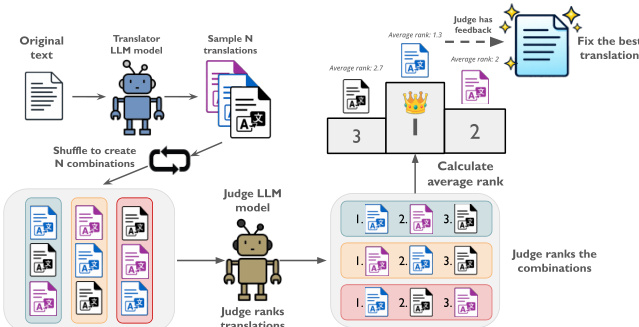
“翻译排序”(Translation Ranking, T-RANK)通过引入多轮位置洗牌机制改进先前基于排序的方法,以缓解大语言模型评估偏差。如图所示,采样 N 个翻译后,在 N 轮中每次以不同顺序呈现,确保每个候选翻译在每轮中占据每个位置恰好一次。评判大语言模型根据质量、领域一致性和对原始意图的保真度对每轮候选翻译进行排序。平均排名决定最佳候选翻译,然后可选地在最终修正阶段将所有候选翻译再次呈现给评判者进行优化。该方法需要 2N+1 次模型调用,显著减少位置偏差,并通过比较推理实现更深入的错误检测。
为标准化评估,作者为评判大语言模型提供结构化提示,如图所示。这些提示要求模型根据检查表分析两个翻译,阐明比较推理,并输出 JSON 格式的裁决结果,明确哪个翻译更优或是否相等。这种结构化输出确保可复现性,并支持跨多次评估自动聚合质量信号。

每种方法均可通过提示和参数进行配置,允许用户根据特定语言对、领域约束或预算限制定制框架。作者强调,尽管 BoN 和 USI 相较基线翻译有所提升,但 T-RANK 的竞争性排序机制在检测细微、语境敏感的翻译错误方面表现更优。
实验
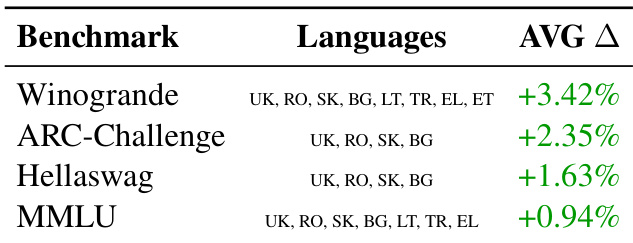
- USI 和 T-RANK 在 FLORES 和 WMT24++ 基准测试上优于基线方法,COMET 评分表明翻译质量优异,但两者无一致优劣。
- T-RANK 在翻译复杂、基于问题的基准测试时表现突出,这些测试中保持语境和避免答案泄露至关重要,而 USI 在较短、较简单的文本上表现更佳。
- 使用 Gemini-2.5-Flash 的“大语言模型作为评判者”评估证实,这两种方法在乌克兰语、罗马尼亚语和立陶宛语上的翻译质量优于现有基准测试。
- 中型模型(Gemma 3、Qwen 3、Llama 3.1)在翻译基准测试上获得更高分数,验证了评估可靠性的提升——尤其在 Winogrande 上,语境完整性至关重要。
- 无参考的 COMET 评估进一步支持质量提升,尤其在 MMLU 和 FLORES 中较长、较复杂的文本上。
- 现有基准测试中的翻译错误——如性别相关的答案泄露或语义断裂——被所提出的方法系统性修正。
- 性能因模型而异:Gemini-2.0-Flash 在 T-RANK 上表现更强,表明方法适用性取决于模型架构和任务复杂性。
- 人工翻译基准测试(如保加利亚语 Winogrande)在某些情况下仍优于自动化翻译,表明特定语言-基准组合仍需人工监督。
- 该框架在准确性、效率和可扩展性之间取得平衡,但存在局限性,包括依赖闭源模型、缺乏自适应难度处理,以及排序中的潜在位置偏差。
作者使用所提方法与现有翻译对比,评估中型语言模型在翻译基准测试上的表现,发现大多数模型性能一致提升,尤其在 Winogrande 上,语境保留至关重要。尽管大多数模型在作者翻译的基准测试上得分提高,Qwen3-8B-IT 在 Winogrande 上表现欠佳,表明翻译质量对评估结果的影响因模型和基准而异。这些结果支持该框架在提升多语言基准可靠性方面的有效性,尽管模型特异性行为表明翻译策略可能需要定制。
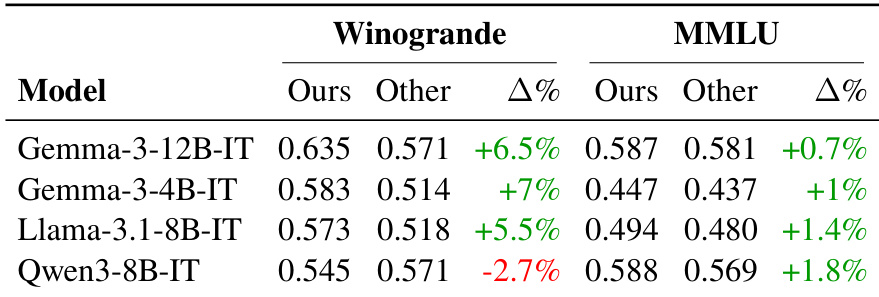
作者使用所提方法与现有翻译对比,评估中型语言模型在翻译基准测试上的表现,发现大多数基准测试和语言上的分数一致提升。值得注意的是,Winogrande 显示最大提升,归因于翻译过程中更好地保留了语境和语法完整性。结果证实,增强的翻译质量直接有助于更可靠的模型评估,尽管某些基准测试仍受益于专业人工翻译。
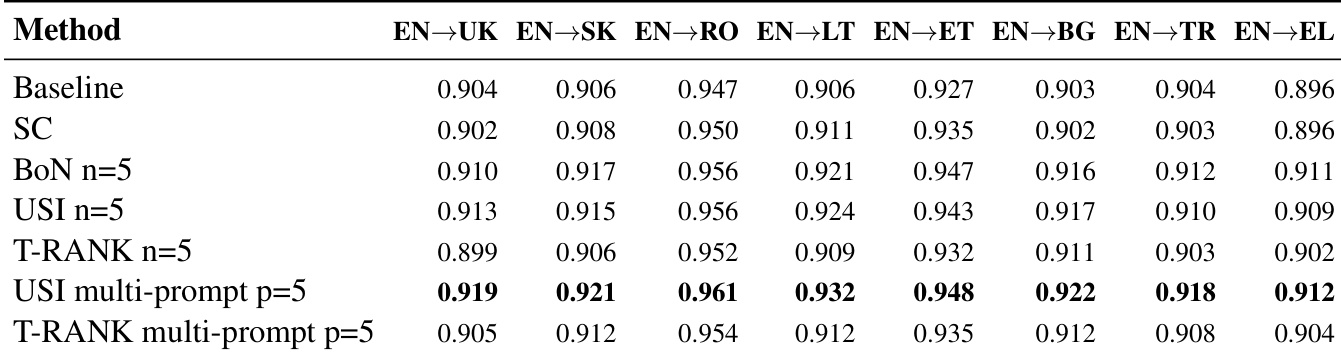
作者使用多提示和候选采样策略提升多种欧洲语言的机器翻译质量,其中 USI 多提示始终获得最高的 COMET 评分。结果表明,结合多个翻译提示比单纯增加候选样本更可靠地提升性能,尤其对罗马尼亚语和爱沙尼亚语等语言。虽然 T-RANK 多提示也表现强劲,但在此评估设置中,USI 多提示在语言对之间展现出更广泛的稳定性。
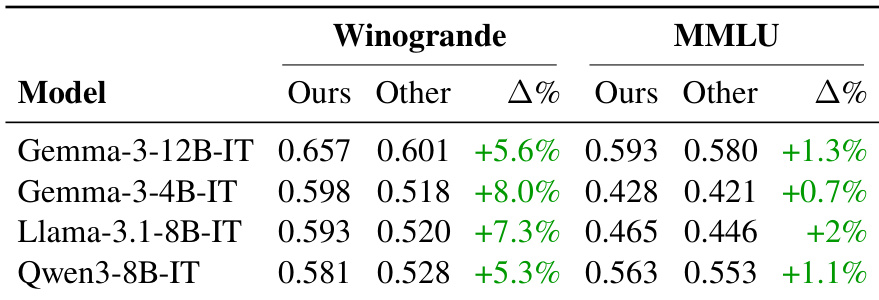
作者使用所提方法与现有翻译对比,评估中型语言模型在翻译基准测试上的表现,观察到 Winogrande 和 MMLU 上性能一致提升。结果表明,Gemma-3、Llama-3.1 和 Qwen-3 等模型在改进后的翻译上获得更高分数,表明增强的翻译质量有助于更可靠的模型评估。这些改进在 Winogrande 上尤为显著,因为保持语境和语法完整性对准确评估至关重要。
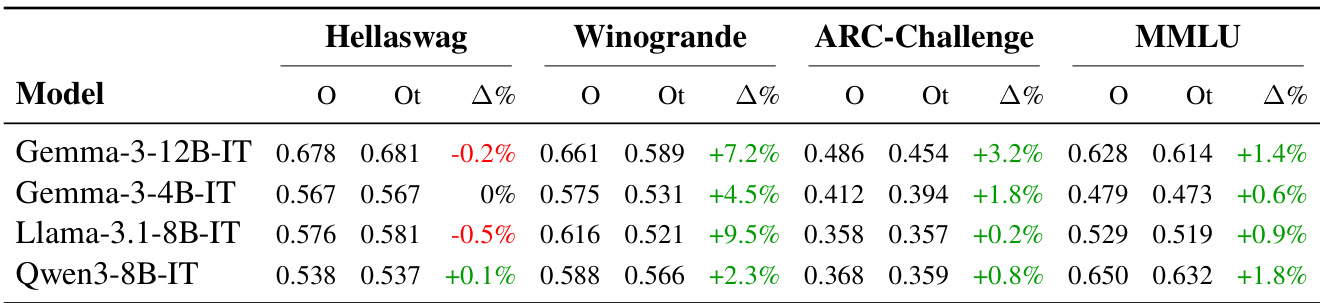
作者使用所提翻译框架评估多个基准测试上的性能,观察到使用其翻译数据集相比现有数据集时,模型评估分数一致提升。结果表明,Winogrande 上的提升最大,因为在翻译过程中保留语境和语法完整性显著增强了评估可靠性。该框架在多种语言中表现出广泛有效性,但提升幅度因基准测试和语言复杂性而异。