Command Palette
Search for a command to run...
面向边缘智能的早期退出预测编码神经网络
面向边缘智能的早期退出预测编码神经网络
Alaa Zniber Mounir Ghogho Ouassim Karrakchou Mehdi Zakroum
摘要
物联网(Internet of Things)正深刻变革多个领域,传感器日益被嵌入可穿戴设备、智能建筑及互联设备中。尽管深度学习能够从物联网数据中提炼出高价值洞察,但传统模型的计算需求过高,难以在资源受限的边缘设备上部署。此外,隐私保护需求与实时处理要求使得本地计算相较于云端方案更具必要性。受大脑高能效特性的启发,我们提出了一种带有早退机制(early exiting)的浅层双向预测编码网络,该网络在达到预设性能阈值时动态终止计算,从而在保持高精度的同时显著降低内存占用与计算开销。我们利用 CIFAR-10 数据集验证了该方法的有效性。实验结果表明,我们的模型以显著更少的参数和更低的计算复杂度,实现了与深度网络相当的性能,充分彰显了生物启发式架构在高效边缘 AI 应用中的巨大潜力。
一句话总结
拉巴特国际大学、穆罕默德六世理工大学和利兹大学的研究人员提出了 EE-PCN,这是一种带有早期退出机制的浅层双向预测编码网络。该网络通过动态停止计算,以最小的内存和浮点运算量(FLOPs)实现深度网络的精度,适用于极端边缘 AI 场景。
主要贡献
- 本文提出了一种新的双向网络预测编码循环规则推导方法,有效实现了反馈和前馈更新机制。
- 设计了一种浅层预测编码网络,在显著降低内存占用的同时,实现了与深层模型相当的精度,适用于极端边缘设备的部署。
- 该方法结合了动态早期退出机制和跨循环的知识蒸馏,自适应地调整运算次数,从而提高了推理效率和早期退出的性能。
引言
物联网在健康监测和智慧城市等领域的发展,要求在资源受限的边缘设备上进行实时数据处理,然而传统的深度学习模型计算量过大且内存占用过高,难以适应这些环境。虽然预测编码网络(PCN)提供了受生物学启发的效率,但先前的实现通常使参数量翻倍,且缺乏自适应机制,导致其在简单输入上执行不必要的计算。为了解决这些挑战,作者提出了一种浅层双向 PCN,集成了早期退出机制,一旦达到性能阈值即可动态停止推理。该方法利用跨循环的知识蒸馏来保持高精度,同时大幅减少内存占用和计算开销,使其非常适合极端边缘部署。
数据集
- 作者使用了 CIFAR-10 数据集,该数据集包含 60,000 张 32x32 的 RGB 图像,均匀分布在 10 个类别中,用于模拟低分辨率物联网应用(如监控和智能农业)。
- 数据集被划分为 50,000 张图像的训练集和 10,000 张图像的测试集。
- 对训练集应用了随机平移和水平翻转的数据增强技术。
- 训练数据被处理成 128 张图像的批次用于模型学习。
方法
作者提出了一种带有早期退出能力的预测编码网络(PCN)模型,以优化推理效率。该架构由一个作为特征提取器的共享主干网络以及多个下游任务分类器组成。主干网络被设计为卷积层和反卷积层的双向层次结构。
如下图所示:
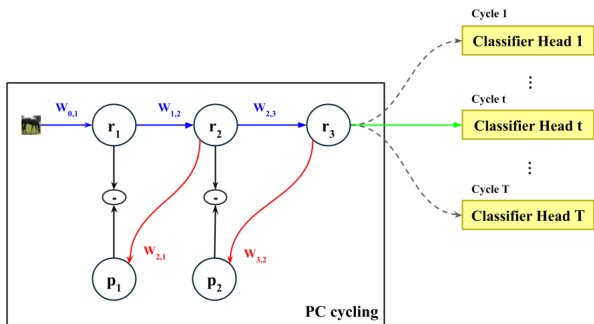
在该框架中,蓝色箭头表示前向卷积传递,红色箭头表示用于减少局部误差的反馈反卷积。在推理过程中,模型在主干网络上执行可变数量的循环 t≤T,以迭代地最小化所有层的局部预测误差。一旦循环过程结束,最后一层的特征向量将被传递给对应于当前循环计数 t 的分类器(由绿色箭头指示)。然后将分类置信度与预定义的用户阈值进行比较。如果置信度超过阈值,推理终止并返回响应。否则,将启动另一个循环,随后进行另一次分类和阈值比较。
该架构采用 T 个不同的分类器,而不是所有循环共享单个分类器。这一决定是由迭代过程中特征表示的演变性质驱动的。由于特征向量从一个循环到下一个循环不断细化,在五个循环模型上训练的分类器将无法准确解释同一输入下一个循环模型提取的模式。
为了推导 PC 更新规则,作者应用梯度下降法来最小化每次传递的局部误差。设 rl(t) 表示卷积层 l 和循环 t 处的特征表示。层 l=0 的表示固定为输入图像。对于 t=0,所有特征表示通过标准前馈传递初始化: rl(0)=ϕ(Wl−1,lrl−1(0)),l=1,⋯,L 其中 ϕ 是非线性激活函数,在实验中假设为 ReLU。
反馈传递更新规则控制这样一个过程:高层表示 rl+1(t) 生成对低层表示 rl(t) 的自上而下预测,记为 pl(t)。该预测由下式给出: pl(t)=ϕ[Wl+1,lrl+1(t)] 更新通过最小化局部误差 ϵl(t)=21∣∣rl(t)−pl(t)∣∣22 来实现。在中间点 t+1/2 计算的反馈更新规则表示为: rl(t+1/2)=(1−αl)rl(t)+αlϕ[Wl+1,lrl+1(t)] 根据设计,最后一层的表示在反馈传递期间保持不变。
前馈传递更新规则控制这样一个过程:低层表示生成自下而上的预测,然后用于更新高层表示。前馈预测由下式给出: pl(t+1/2)=ϕ[Wl−1,lrl−1(t+1/2)] 这导致了以下前馈更新规则: rl(t+1)=(1−βl)rl(t+1/2)+βlϕ[Wl−1,lrl−1(t+1/2)] 与仅依赖反馈卷积权重矩阵的先前公式不同,该公式整合了自上而下和自下而上的预测,从而实现了更全面的更新机制。
关于训练,分类任务被表述为一个多目标优化问题,其中 T 个损失(记为 Li)在共享权重上竞争。作者使用标量化方法解决了这一问题,通过加权平均将问题转化为单目标优化。此外,他们在中间 logits 和最终循环 logits 之间引入了 Kullback-Leibler (KL) 散度(记为 KD),以促进知识蒸馏。在该框架中,最深的网络充当教师,而前面的浅层子网络充当学生。总损失表示为: Ltot=ρ∑i=1TλiLi+(1−ρ)∑i=1T−1KD(y^i,y^T) 其中 λi 是损失函数 Li 的正权重因子,y^i 表示来自分类器 i 的 logit 向量,ρ 是平衡因子。
模型设计利用 PC 动力学开发能够在极端边缘设备上运行的浅层网络。这些模型基于类 VGG 架构,其中所有卷积均使用 3×3 内核,步长为 1,后接 ReLU 激活函数。每当通道数发生变化时,在前向方向应用最大池化,或在反馈方向应用 2×2 内核的上采样。最后,早期退出分类器被实现为简单的线性层,以确保最小的开销。
实验
- 实验验证了浅层模型中使用 PC 更新规则进行递归处理,在极端边缘设备上实现了具有竞争力的性能,优于针对边缘设计的基线模型,并以显著更少的参数量接近 VGG-11 的精度。
- 结果表明,额外的处理循环增强了模型的表达能力,使浅层架构能够更好地学习复杂模式并区分困难类别。
- 集成早期退出机制显著降低了计算负载和能耗,高置信度阈值使模型能够对大多数输入提前退出,同时保持精度。
- 所提出的模型满足了节俭型微控制器的严格内存限制,其递归性质确保了对于数据集的大部分,其浮点运算量(FLOPs)低于深度网络,从而延长了电池寿命。
- 比较证实,结合自上而下和自下而上预测的预测编码规则优于等效的前馈 CNN。