Command Palette
Search for a command to run...
PixelSmile:迈向细粒度面部表情编辑
PixelSmile:迈向细粒度面部表情编辑
Jiabin Hua Hengyuan Xu Aojie Li Wei Cheng Gang Yu Xingjun Ma Yu-Gang Jiang
摘要
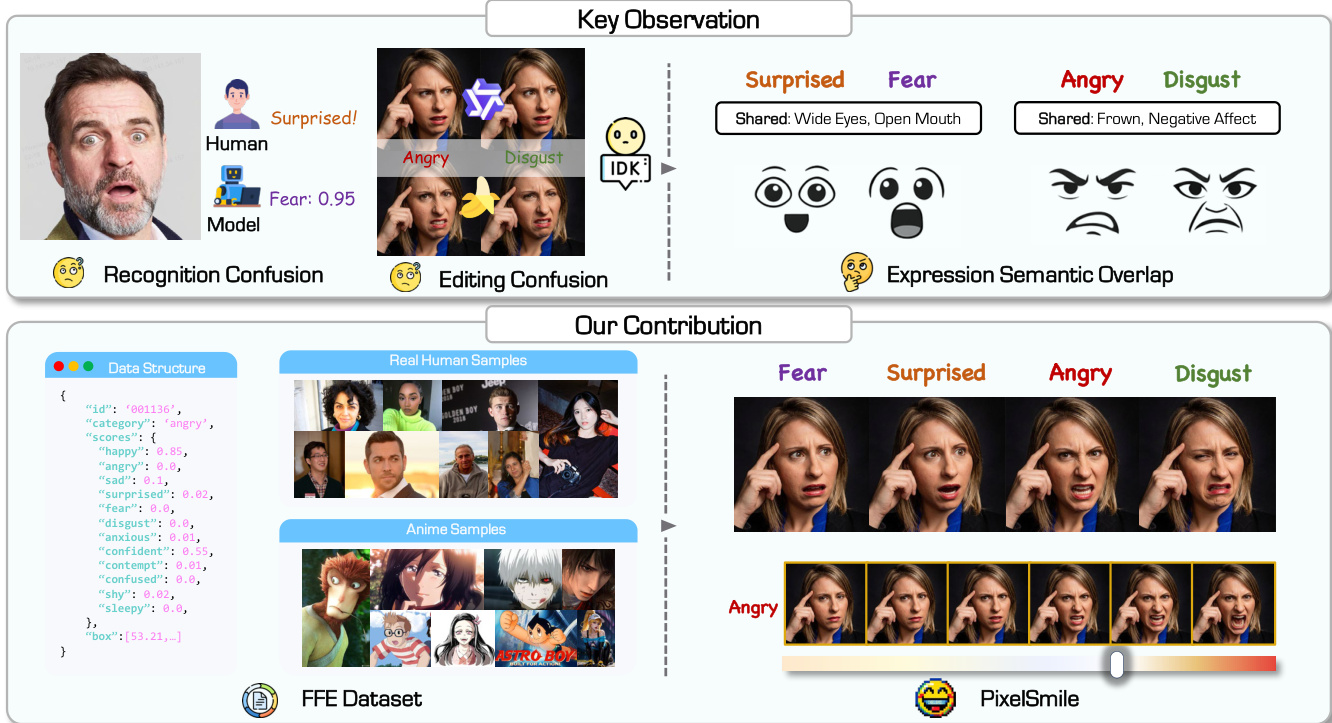
细粒度面部表情编辑长期以来受限于内在的语义重叠问题。为此,我们构建了具有连续情感标注的 Flex Facial Expression(FFE)数据集,并建立了 FFE-Bench 评测基准,用于评估结构混淆度、编辑准确性、线性可控性以及表情编辑与身份保持之间的权衡。我们提出了 PixelSmile,这是一种基于 Diffusion 的框架,通过完全对称的联合训练实现表情语义的解耦。PixelSmile 将强度监督与对比学习相结合,生成更强且更具区分度的表情,并通过文本潜在空间插值实现精确且稳定的线性表情控制。大量实验表明,PixelSmile 在语义解耦与身份保持方面均表现出优越性能,验证了其在连续、可控且细粒度表情编辑任务中的有效性,同时天然支持平滑的表情融合。
一句话总结
复旦大学与 StepFun 的研究人员提出了 PixelSmile,这是一个扩散框架,通过采用对称联合训练和对比学习,解决了面部编辑中的语义重叠问题。该方法能够在真实世界和动漫领域中稳健地保持身份特征,同时实现对表情强度的精确、连续控制以及无缝融合。
主要贡献
- 本文介绍了 Flex Facial Expression (FFE) 数据集,该数据集包含连续的 12 维情感标注,并建立了 FFE-Bench 基准,用于评估结构混淆、编辑精度、线性可控性以及表情编辑与身份保持之间的权衡。
- 提出了一种名为 PixelSmile 的新型扩散框架,该框架采用完全对称的联合训练和对比学习,以解耦重叠的表情语义,生成更强、更具区分度的面部表情。
- 实验表明,所提出的方法通过文本潜在插值实现了精确且稳定的线性表情控制,同时保持了稳健的身份特征,并支持真实世界与动漫领域间的平滑表情融合。
引言
面部表情编辑对于从数字替身到内容创作等应用中的逼真肖像操纵至关重要,然而当前的基于扩散的模型在细粒度控制方面仍面临挑战。先前的方法依赖于离散的单热标签,将连续的人类情感强行归类为僵硬的类别,导致语义纠缠,使得恐惧和惊讶等相似表情变得难以区分,并在编辑过程中引发身份漂移。作者通过引入具有连续情感标注的 Flex Facial Expression (FFE) 数据集,并提出 PixelSmile 扩散框架来解决这些局限性。该框架利用对称联合训练和文本潜在插值,解耦重叠的情感,从而实现精确且线性可控的编辑。
数据集
-
数据集构成与来源:作者通过四阶段流程构建了 FFE 数据集,以支持真实世界和动漫领域的细粒度面部表情编辑。最终收集包含 60,000 张图像,两个领域各占 30,000 张。真实世界子集源自 Human Images Dataset 和 Matting Human Dataset 等公开肖像数据集,而动漫子集则从涵盖 629 个人物的 207 部作品中精选而成。
-
各子集的关键细节:
- 真实领域:包含约 6,000 个基础身份,涵盖多样化的人口统计特征和场景构图,包括特写和全身镜头。
- 动漫领域:包含来自 CG、2D、Q 版和漫画等多种风格的风格化肖像,年龄分布较扁平,但性别和年龄标签的模糊性较高。
- 表情多样性:两个子集均利用结构化的提示库来生成 12 种目标表情(6 种基本情绪和 6 种扩展情绪),并将其分解为面部属性以确保解剖学一致性。
-
数据使用与训练策略:
- 生成:作者使用 Nano Banana Pro 图像编辑模型,为每个基础身份合成具有不同强度的多种目标表情。
- 训练框架:采用完全对称的联合训练方法,模型采样源图像和一对混淆表情以构建三元组。
- 损失组件:训练目标结合了用于强度对齐的流匹配(Flow-Matching)损失、用于表情分离的对比损失以及身份保持损失。
- 消融研究:为了对比,作者还处理了 MEAD 数据集,通过采样正面视图帧并将离散强度级别映射为连续值。
-
处理与标注细节:
- 连续标注:不使用单热标签,每张图像由 Gemini 3 Pro 视觉语言模型预测一个 12 维连续分数向量,以捕捉表情间的语义重叠。
- 质量控制:流程包括自动人脸检测、针对身份清晰度的手动验证以及一致性检查,以剔除模糊或低置信度的样本。
- 元数据构建:使用基于 Qwen3-VL-235B-A22B 的提示来提取结构化语义属性,同时不保留任何个人元数据以确保隐私和伦理合规。
方法
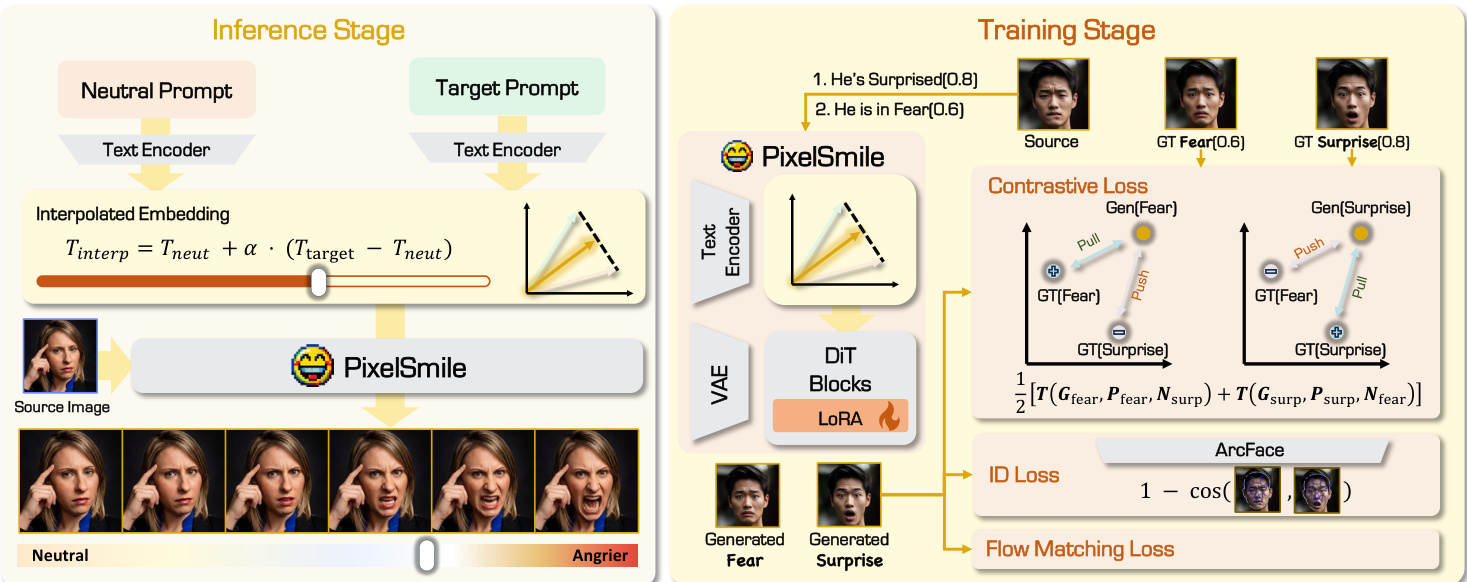
作者提出了 PixelSmile,这是一个专为解决内在语义重叠而设计的细粒度面部表情编辑扩散框架。如下图所示,该方法利用具有连续情感标注的 Flex Facial Expression (FFE) 数据集,建立了针对结构混淆和编辑精度的基准。
核心架构基于预训练的多模态扩散 Transformer (MMDiT) 并进行了 LoRA 适配。为了实现连续强度控制,作者引入了文本潜在插值机制。给定中性提示 Pneu 和目标表情提示 Ptgt,冻结的文本编码器将它们映射为嵌入 eneu 和 etgt。残差方向 Δe=etgt−eneu 捕捉了从中性到目标表情的语义偏移。随后构建连续条件嵌入 econd(α)=eneu+α⋅Δe,其中 α∈[0,1] 决定表情强度。
请参阅框架图以了解完整的训练和推理流程。训练阶段采用完全对称联合训练框架来解耦表情语义。模型在对称双分支方案下进行微调,其中一对混淆表情被联合优化。整体目标结合了分数监督的流匹配损失(显式地将插值系数与视觉变换耦合)以及对称对比损失。对比损失将生成的样本拉向其目标表情,同时在特征空间中将其推离混淆的对应样本。此外,还应用了基于 ArcFace 的身份保持损失,以在强强度外推期间稳定生物特征。
实验
- 建立了 FFE-Bench 基准,用于评估面部表情编辑在结构混淆、表情强度与身份保持之间的权衡、控制线性度以及编辑精度方面的表现。
- 与通用编辑模型的对比表明,所提出的方法实现了更优的表情编辑精度,显著减少了相似表情间的语义混淆,同时保持了自然的身份保真度。
- 针对线性控制模型的评估显示,该方法能够在广泛的强度范围内实现平滑、单调的表情过渡,有效避免了现有基线中出现的身份崩溃或不稳定响应。
- 消融研究证实,身份损失对于防止面部属性漂移至关重要,而对比损失对于解耦语义重叠的表情至关重要,对称训练框架提供了最稳定的优化效果。
- 用户研究和定性分析验证,该方法在编辑连续性和身份一致性之间提供了最佳平衡,同时支持通过线性插值生成合理的复合表情。