Command Palette
Search for a command to run...
PackForcing:短视频训练足以支持长视频采样与长上下文推理
PackForcing:短视频训练足以支持长视频采样与长上下文推理
Xiaofeng Mao Shaohao Rui Kaining Ying Bo Zheng Chuanhao Li Mingmin Chi Kaipeng Zhang
摘要
自回归视频扩散模型虽已取得显著进展,但在生成长视频时仍受限于不可处理的线性 KV 缓存增长、时间重复现象以及误差累积等问题。为应对这些挑战,我们提出了 PackForcing——一个统一的框架,通过一种新颖的三部分 KV 缓存策略高效管理生成历史。具体而言,我们将历史上下文划分为三类:(1) Sink tokens,用于以全分辨率保留早期锚定帧,以维持全局语义;(2) Mid tokens,通过融合渐进式 3D 卷积与低分辨率 VAE 重编码的双分支网络,实现巨大的时空压缩(token 数量减少 32 倍);(3) Recent tokens,保持全分辨率以确保局部时间连贯性。为了在严格限制内存占用的同时不牺牲生成质量,我们引入了针对 Mid tokens 的动态 top-k上下文选择机制,并辅以连续的 Temporal RoPE 调整,该机制能以极小的开销无缝重对齐因丢弃 tokens 而产生的位置间隙。凭借这种分层上下文压缩原理,PackForcing 能够在单张 H200 GPU 上生成时长 2 分钟、分辨率为 832x480、帧率为 16 FPS 的连贯视频。其 KV 缓存被限制在仅 4 GB,并实现了显著的 24 倍时间外推能力(从 5 秒扩展至 120 秒),既支持零样本推理,也仅需在 5 秒短视频片段上训练即可有效运行。在 VBench 上的大量实验结果表明,该方法在时间一致性(26.07)和动态程度(56.25)方面均达到了最先进水平,证明短视频监督足以支持高质量长视频合成。项目地址:https://github.com/ShandaAI/PackForcing
一句话总结
来自 Alaya Studio、复旦大学和上海创新研究院的研究人员提出了 PackForcing,这是一个通过将历史 KV 缓存压缩为三个分区来实现长视频生成的框架。该方法在单张 GPU 上实现了从短视频片段 24 倍的时间外推,同时保持了最先进的连贯性。
主要贡献
- 本文介绍了 PackForcing,这是一个统一的框架,将生成历史划分为 Sink(汇点)、压缩和近期 Token,从而将每层的注意力限制在约 27,872 个 Token 以内,无论视频长度如何。
- 一种融合渐进式 3D 卷积与低分辨率 VAE 重编码的混合压缩层,实现了中间历史 128 倍的空间时间压缩,将有效内存容量提高了 27 倍以上。
- 该方法采用动态 top-k 上下文选择机制,结合增量式 Temporal RoPE 调整,无需重新计算整个缓存即可无缝修正因丢弃 Token 而产生的位置间隙。
引言
自回归视频扩散模型能够实现长视频生成,但面临关键瓶颈:线性增长的 Key-Value 缓存导致显存溢出错误,而迭代预测则引发严重的语义漂移。先前的解决方案要么截断历史以节省显存,从而破坏长程连贯性;要么保留完整上下文,导致单张 GPU 无法处理分钟级视频。作者提出了 PackForcing,这是一个统一的框架,将生成历史划分为 Sink、压缩和近期 Token,在保持全局语义的同时限制显存占用。通过采用双分支网络进行大规模时空压缩,并结合动态 top-k 选择机制与增量 RoPE 调整,该方法仅使用 5 秒的训练片段,便在单张 H200 GPU 上实现了稳定的 2 分钟视频合成。
方法
作者提出了 PackForcing,这是一个旨在通过解耦生成历史为三个不同的功能分区,以解决自回归视频生成中显存瓶颈的框架。整体架构请参考框架图。系统将去噪上下文组织为 Sink Token、Mid Token 以及 Recent 和 Current Token。Sink Token 对应初始帧,保持全分辨率以作为语义锚点。Recent 和 Current Token 在全分辨率下保持高保真的局部动态。绝大多数历史数据落入 Mid Token 分区,该分区经过激进压缩,将 Token 数量减少约 32 倍。
为了实现这种压缩,作者采用了一个双分支压缩模块。如下图所示,该模块通过两条并行路径处理 Mid Token。高分辨率(HR)分支利用 4 阶段 3D CNN 保留细粒度的结构细节。低分辨率(LR)分支将潜在帧解码到像素空间,进行池化操作,并通过 VAE 重新编码以捕捉粗略语义。这些特征通过逐元素相加进行融合,生成最终的压缩 Token。
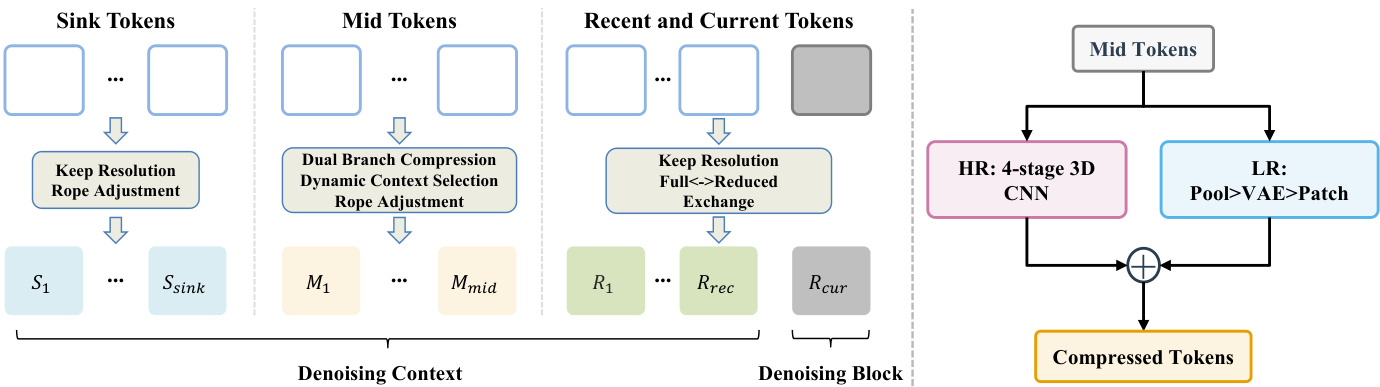
HR 分支的具体架构在后续图中详细说明。它由一系列带有 SiLU 激活函数的步长 3D 卷积级联而成。该过程始于时间压缩,随后是三个阶段的空间压缩,最终投影到模型的隐藏维度。这种设计在保留关键布局信息的同时,实现了显著的体积缩减。

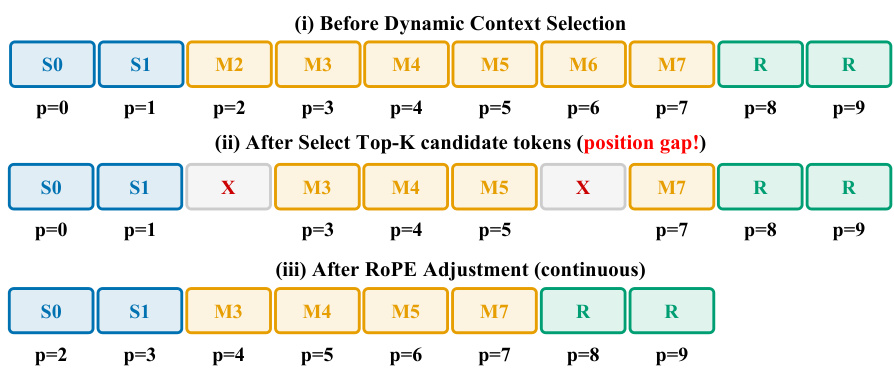
为了进一步优化显存使用,系统实施了动态上下文选择。模型并非关注所有压缩后的 Mid Token,而是评估查询 - 键(query-key)亲和力,仅路由前 K 个最具信息量的块。这种选择过程不可避免地会在 Token 序列中产生位置间隙。为了解决这一问题,作者应用了增量 RoPE 调整。请参考说明选择过程的图表,了解位置索引是如何重新对齐的。最初,选择过程会在移除 Token 的位置产生间隙。随后,RoPE 调整会移动剩余 Token 的位置嵌入,以确保索引连续,从而使 Transformer 无需完全重新计算即可保持时间连贯性。
最后,训练策略涉及对 HR 压缩层进行端到端优化。在 rollout 阶段,压缩模块直接集成到计算图中。这确保了压缩后的 Mid Token 被显式地定制,以保留下游因果注意力所需的语义和结构线索,而不是最小化通用的重建损失。这种方法使得模型能够从短训练序列泛化到长视频生成,同时保持恒定的注意力复杂度。
实验
- 在 60 秒和 120 秒视频生成上的主要实验验证,与基线方法相比,PackForcing 实现了更优越的运动合成和时间稳定性,在保持高主体和背景一致性的同时,避免了其他方法中出现的严重退化。
- 长程一致性测试证实,Sink Token 机制有效地锚定了全局语义,防止了扩展自回归生成中通常出现的累积误差和语义漂移。
- 消融实验表明,Sink Token 对于平衡动态运动与语义连贯性至关重要,而动态上下文选择通过保留高关注度的历史块,优于标准的 FIFO 淘汰机制。
- 注意力模式分析显示,信息需求分布在整个视频历史中,而不仅仅局限于近期帧,这证明了压缩中间缓冲区和全局摘要 Token 的必要性。
- 定性评估表明,所提出的架构在超过两分钟的时间内保留了精细的视觉细节和复杂的连续运动,而竞争方法则会出现颜色偏移、物体重复或运动冻结等问题。
- 效率分析证明,该压缩策略将显存使用限制在恒定水平,无论视频长度如何,从而使得在单张 GPU 上进行长视界生成成为可能,而未压缩的方法在此类场景下会失败。