Command Palette
Search for a command to run...
TAPS:面向推测采样的任务感知提议分布
TAPS:面向推测采样的任务感知提议分布
Mohamad Zbib Mohamad Bazzi Ammar Mohanna Hasan Abed Al Kader Hammoud Bernard Ghanem
摘要
推测解码(Speculative decoding)通过让轻量级草稿模型(draft model)预提案未来 token,并由更大的目标模型并行验证,从而加速自回归生成。然而在实际应用中,草稿模型通常是在广泛的通用语料上训练的,因此推测解码的质量在多大程度上依赖于草稿模型的训练分布尚不明确。本文针对这一问题展开研究,使用在 MathInstruct、ShareGPT 及其混合数据变体上训练的轻量级 HASS 和 EAGLE-2 草稿模型,在 MT-Bench、GSM8K、MATH-500 和 SVAMP 等基准上进行了评估。以接受长度(acceptance length)为衡量指标,面向特定任务的训练带来了显著的专业化效果:在 MathInstruct 上训练的草稿模型在推理类基准上表现最佳,而在 ShareGPT 上训练的草稿模型则在 MT-Bench 上表现最优。混合数据训练提升了鲁棒性,但更大规模的混合数据并未在不同解码温度下全面占优。此外,本文还研究了在推理阶段如何组合专业化草稿模型。简单的检查点平均(checkpoint averaging)方法表现不佳,而基于置信度(confidence)的路由策略优于单一领域草稿模型,合并树验证(merged-tree verification)则对两种骨干模型均实现了整体最高的接受长度。最后,研究发现置信度是比熵(entropy)更有用的路由信号:被拒绝的 token 往往具有更高的熵,但置信度能产生更清晰的基准级路由决策。上述结果表明,推测解码的质量不仅取决于草稿模型的架构,还取决于草稿训练数据与下游任务负载之间的匹配程度;同时,在推理阶段组合专业化草稿模型的效果优于在权重空间进行融合。
一句话总结
KAUST 与美国贝鲁特大学的研究人员提出了 TAPS,证明了针对特定任务训练 HASS 和 EAGLE-2 草稿模型,能显著提升在匹配工作负载下的推测解码接受率。他们的研究揭示,在推理阶段通过基于置信度的路由或合并树验证来组合专用模型,其表现优于简单的权重平均,从而优化了数学和对话等不同领域的 LLM 吞吐量。
主要贡献
- 本文引入了实证分析,表明针对特定任务训练的草稿模型能产生明显的专业化效果:在 MathInstruct 上训练的草稿模型在推理基准测试中表现优异,而在 ShareGPT 上训练的草稿模型在 MT-Bench 上表现最佳。
- 本工作证明,在推理阶段通过基于置信度的路由和合并树验证来组合专用草稿模型,其表现显著优于简单的权重空间平均,在 HASS 和 EAGLE-2 两种骨干网络上均实现了最高的接受长度。
- 结果表明,在做出基准级别的决策时,置信度是比熵更有效的路由信号,因为被拒绝的 token 表现出更高的熵,而置信度能为选择最佳草稿模型提供更清晰的区分度。
引言
LLM 中的自回归生成面临显著的推理瓶颈,推测解码通过利用轻量级草稿模型提出 token,供更大的目标模型并行验证来解决这一问题。虽然 prior 工作主要集中在改进草稿架构或验证过程,但大多数草稿模型是在广泛的通用语料库上训练的,导致训练数据分布对接受质量的影响尚未得到充分探索。作者利用 MathInstruct 和 ShareGPT 等数据集进行特定任务训练,证明了专用草稿模型在匹配的基准测试上显著优于通用模型。他们进一步表明,在推理阶段通过基于置信度的路由和合并树验证来组合这些专家模型,其结果优于简单的权重平均或混合数据训练。
方法
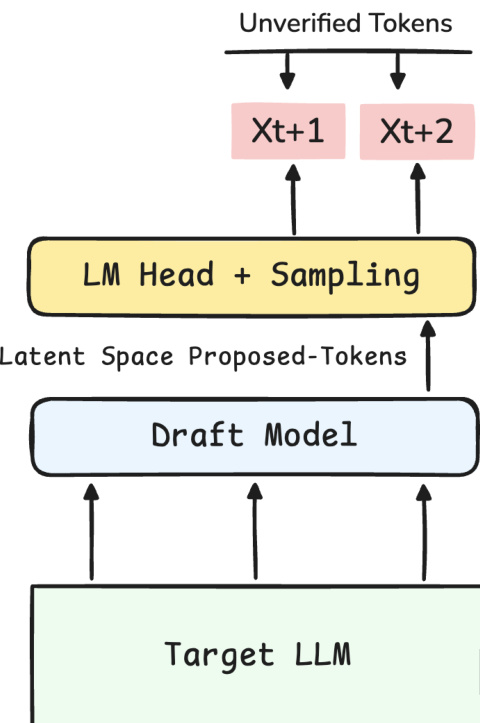
作者利用了一个推测解码框架,其中轻量级草稿模型提出未来 token,供更大的目标 LLM 进行验证。如框架图所示,该过程始于目标 LLM 向草稿模型提供上下文。草稿模型在潜在空间中运行以提出 token,随后这些 token 经过 LM Head 和采样层,生成未验证的 token,如 Xt+1 和 Xt+2。
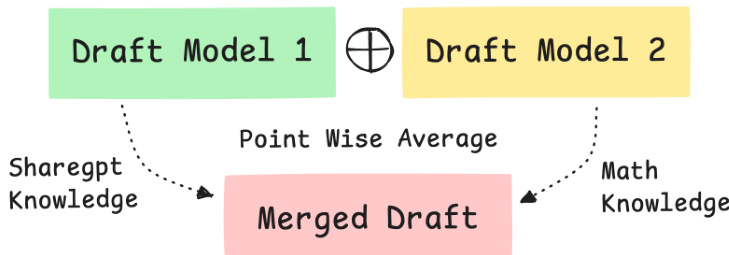
为了提高这些草稿的质量,作者探索了专用模型的组合策略。一种基线方法是检查点平均。如下图所示,来自不同草稿模型(例如一个在 ShareGPT 数据上训练,另一个在数学数据上训练)的参数通过逐点平均进行组合,创建一个单一的合并草稿模型。
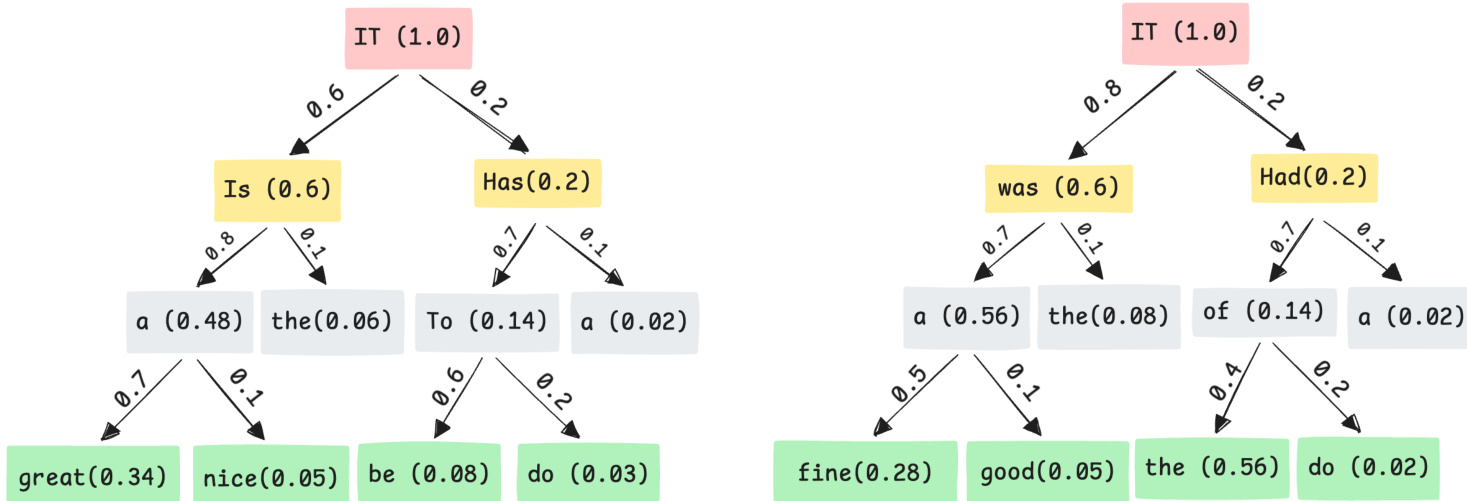
或者,作者研究了推理时的组合策略,这些策略保持独立的专用检查点。在这种设置下,专用模型生成具有相关置信度分数的不同候选续写,如树状图所示,不同专家对应不同的分支。
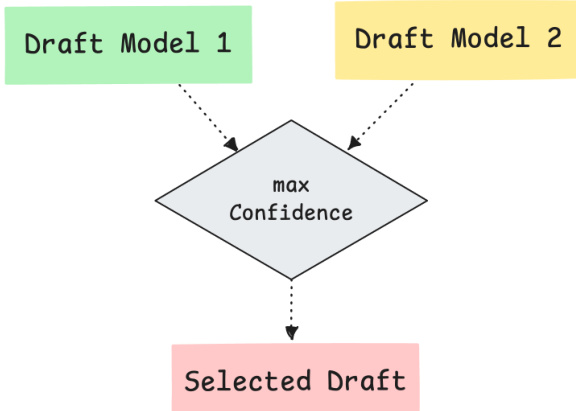
对于推理时的选择,作者提出了置信度路由。该方法从不同的检查点生成独立的草稿树,并在验证前选择具有更高平均节点置信度的树,如路由图所示,其中选择了最大置信度路径。
一种更全面的策略是合并树验证。该方法不是选择单棵树,而是将多棵草稿树打包在一个共享根节点下。这使得验证器能够在一次并行传递中评估所有专家的候选项。扁平化的合并树输入通过树注意力掩码和基于深度的位置 ID 保留了祖先关系,使验证器能够处理两个专用子树而无需跨子树注意力。
实验
- 单域训练验证了当草稿模型的训练分布与目标工作负载匹配时,其接受长度显著提高,其中数学模型在推理任务上表现优异,而对话模型在对话基准测试上表现最佳。
- 混合数据训练表明,组合不同领域可以提高跨域鲁棒性,尽管最佳混合比例取决于解码温度,且不能保证统一的泛化能力。
- 推理时的组合策略,特别是基于置信度的路由和合并树验证,显著优于权重空间平均,证明了在运行时保持专用模型独立并将其组合比合并参数更有效。
- 对置信度、熵和推测深度的分析表明,置信度是专家间路由的更优信号,而更深的推测步骤越来越倾向于任务匹配的专家,而非广覆盖模型。
- 总体结论表明,推测解码中的提案质量是架构和训练分布的函数,因此需要任务感知的草稿生成和动态组合,而非静态的、平均化的检查点。