Command Palette
Search for a command to run...
手术人工智能比较研究:数据集、基础模型与医疗通用人工智能的障碍
手术人工智能比较研究:数据集、基础模型与医疗通用人工智能的障碍
摘要
近年来,人工智能(AI)模型在多项生物医学任务基准测试中已达到甚至超越人类专家的水平,但在手术图像分析基准测试方面仍显滞后。由于手术操作需要整合多种异构任务——包括多模态数据融合、人机交互以及物理效应模拟——若其性能得以提升,通用型 AI 模型有望成为极具吸引力的手术协作工具。一方面,扩大模型架构规模与训练数据量的经典方法颇具吸引力,尤其是考虑到每年可生成数百万小时的手术视频数据。另一方面,为 AI 训练准备手术数据需要更高水平的专业医学知识,而基于此类数据的模型训练则依赖昂贵的计算资源。这些权衡使得现代 AI 能否以及在多大程度上辅助临床手术实践,前景尚不明朗。本文通过一项案例研究探讨上述问题,聚焦于利用 2026 年可用的最先进 AI 方法开展手术器械检测。研究结果表明,即便采用参数量达数十亿的模型并进行充分训练,当前的视觉 - 语言模型(Vision Language Models)在神经外科手术中看似简单的器械检测任务上仍表现不足。此外,我们的扩展实验显示,单纯增加模型规模与训练时长仅带来相关性能指标的边际改善。因此,实验结果提示,现有模型在手术应用场景中仍面临显著障碍。值得注意的是,部分障碍无法仅通过增加计算资源“扩展消除”,且在不同模型架构中普遍存在,这引发了对“数据与标注可用性是否为唯一限制因素”的深层质疑。本文进一步剖析了制约当前性能的主要成因,并提出潜在的解决路径。
一句话总结
芝加哥布斯商学院与手术数据科学集体(Surgical Data Science Collective)的研究人员证明,单纯扩大视觉语言模型(VLM)的规模无法解决手术器械检测问题。研究揭示,尽管投入了巨大的计算资源,但在神经外科和腹腔镜手术中,像 YOLOv12-m 这样的专用架构在性能上显著优于拥有数十亿参数的系统。
主要贡献
- 该论文在 SDSC-EEA 神经外科数据集上评估了 19 个开源权重的视觉语言模型的零样本手术器械检测能力。结果显示,尽管模型规模增大,但仅有一个模型的表现略微超过了多数类基线。
- 针对微调后的 Gemma 3 27B 模型,引入了一种专用的分类头来替代现成的 JSON 生成方法,实现了 51.08% 的精确匹配准确率,优于基线及标准微调方法。
- 实验表明,一个仅含 2600 万参数的专用 YOLOv12-m 模型达到了 54.73% 的精确匹配准确率,超越了所有测试的视觉语言模型,同时参数量减少了 1000 倍,并能有效地泛化到 CholecT50 腹腔镜数据集。
引言
手术人工智能旨在创建能够整合多模态数据和物理效应的协作工具,以辅助复杂的手术操作,然而当前系统在手术图像分析基准测试中仍难以匹敌人类表现。尽管主流的“缩放假设”认为增加模型规模和训练数据将解决这些问题,但先前的工作面临着数据标注成本高昂、需要专业知识以及单纯增加算力无法克服特定领域分布偏移等显著挑战。作者通过手术器械检测的案例研究证明,即使是拥有数十亿参数的视觉语言模型,在零样本设置下也无法超越简单的基线,且随着规模扩大收益递减。最终证明,像 YOLOv12-m 这样参数量少得多的专用小型模型,其表现优于大型基础模型。
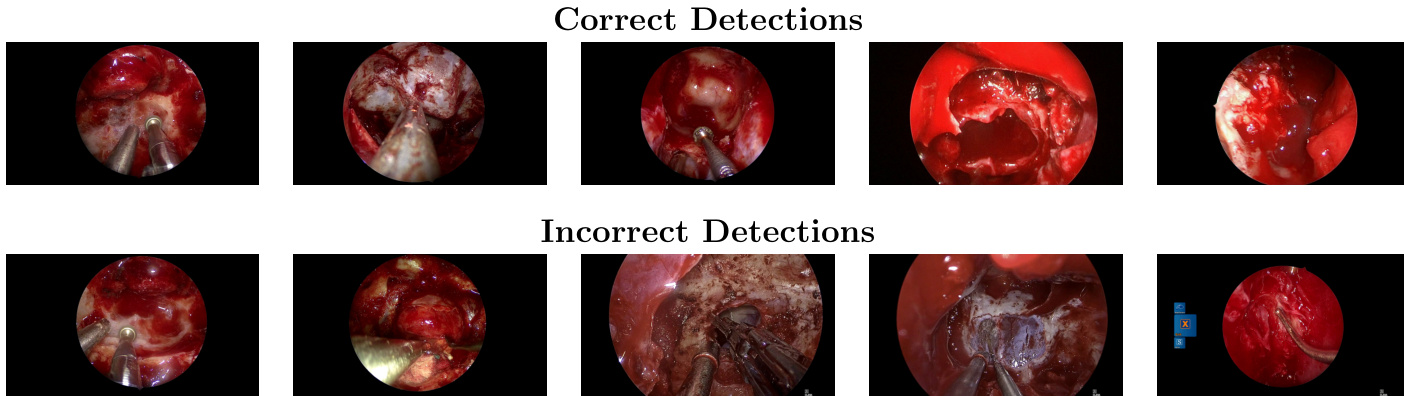
数据集
-
数据集构成与来源:作者利用了 SDSC-EEA 数据集,该数据集包含从 66 例独特的经鼻内镜入路(EEA)神经外科手术中提取的 67,634 个标注帧。这些视频记录由来自美国、法国和西班牙 7 个机构的 10 位外科医生捐赠,在筛选过程中未应用任何排除标准。
-
各子集的关键细节:
- 标注质量:31 种不同手术器械类别的 ground truth 标签由三名非临床标注员生成,并由高级标注员和 SDSC 成员进行复核,少于 10% 的帧需要修正。
- 格式与分布:标注以 YOLO 格式提供,包含边界框。数据集显示出显著的类别不平衡,Suction(吸引器)出现在 63.3% 的帧中,而 Cotton Patty(棉片)和 Grasper(抓钳)等其他工具出现频率较低。
- 划分策略:为防止数据泄露,数据按手术过程而非单个帧进行划分。这导致训练集包含来自 53 个手术过程的 47,618 帧,验证集包含来自 13 个手术过程的 20,016 帧。
-
在模型中的使用:
- 微调:训练集用于视觉语言模型(VLM)的 LoRA 微调。
- 零样本评估:作者使用特定的提示模板评估零样本 VLM 性能,该模板列出了所有 31 个有效工具名称,并要求模型以严格的 JSON 格式返回检测到的工具。
- 外部验证:该方法包括在外部 CholecT50 数据集上进行验证,以评估泛化能力。
-
处理与元数据细节:
- 防止数据泄露:手术级别的划分确保了同一手术的帧不会同时出现在训练集和验证集中,导致各划分间的工具分布不均(例如,Sonopet 菠萝头仅出现在训练集中)。
- 标注协议:标注员在标注前收到了工具描述和代表性图像以确保一致性,最终数据集包含多标签 ground truth,指示每帧中器械的存在与否。
实验
- 对 19 个开源权重视觉语言模型进行的零样本评估(跨越两年的开发周期)显示,即使是最大的模型也无法超越手术器械检测的简单多数类基线,这表明通用的多模态基准性能无法迁移到专业的手术感知任务中。
- 使用 LoRA 适配器进行微调提高了相对于零样本基线的性能,其中专用的分类头优于自回归 JSON 生成,但训练准确率与验证准确率之间持续存在的差距揭示了其对未见过的手术过程泛化能力有限。
- 将 LoRA 适配器的秩(rank)扩大近三个数量级,使训练准确率饱和至接近 99%,而验证准确率仍低于 40%,这表明性能瓶颈是由分布偏移引起的,而非模型容量不足。
- 一个专用的 2600 万参数目标检测模型(YOLOv12-m)在主要数据集上的表现优于所有微调后的视觉语言模型,同时参数量减少了 1000 多倍,这表明特定任务的数据和架构比模型规模更为关键。
- 在独立的腹腔镜数据集(CholecT50)上的复现实验证实,零样本性能仍然较差,微调对于获得高准确率是必要的,且更小的专用模型继续优于大型基础模型,包括专有的前沿系统。
- 总体发现表明,手术人工智能的进展目前受限于大规模、标准化的领域特定数据的可用性,而非人工智能架构的规模,这指向了结合通用模型与专用感知模块的混合系统方向。