Command Palette
Search for a command to run...
ShotStream:面向交互式叙事的流式多镜头视频生成
ShotStream:面向交互式叙事的流式多镜头视频生成
Yawen Luo Xiaoyu Shi Junhao Zhuang Yutian Chen Quande Liu Xintao Wang Pengfei Wan Tianfan Xue
摘要
多镜头视频生成对于长篇叙事至关重要,然而现有的双向架构在交互性与延迟方面存在显著局限。为此,我们提出了 ShotStream——一种新颖的因果多镜头架构,旨在实现交互式叙事与高效的实时帧生成。通过将任务重构为“基于历史上下文生成下一镜头”,ShotStream 允许用户通过流式提示(streaming prompts)动态地指导正在进行的叙事。具体而言,我们首先将文本到视频模型微调为双向下一镜头生成器,随后利用分布匹配蒸馏(Distribution Matching Distillation)将其蒸馏为因果学生模型。针对自回归生成中固有的镜头间一致性与误差累积挑战,我们引入了两项关键创新。首先,设计了一种双缓存记忆机制以维持视觉连贯性:全局上下文缓存保留条件帧以确保镜头间一致性,而局部上下文缓存则存储当前镜头内的生成帧以保障镜头内一致性;同时,引入 RoPE 不连续指示器(RoPE discontinuity indicator)以明确区分这两个缓存,从而消除歧义。其次,为缓解误差累积问题,我们提出了一种两阶段蒸馏策略。该策略首先基于真实历史镜头进行镜头内自强制(intra-shot self-forcing),随后逐步扩展至利用自生成历史进行镜头间自强制(inter-shot self-forcing),从而有效弥合了训练与测试之间的差距。大量实验表明,ShotStream 能够生成连贯的多镜头视频,且延迟低于一秒,在单张 GPU 上可实现 16 FPS 的生成速度。其生成质量媲美甚至超越了速度较慢的双向模型,为实时交互式叙事铺平了道路。训练与推理代码以及模型已发布在我们的...(注:原文末尾未完整,通常此处为项目主页链接)
一句话总结
来自香港中文大学、快手科技和 CPII 的研究人员推出了 ShotStream,这是一种因果多镜头视频生成模型,能够实现实时交互式叙事。通过采用双缓存内存和两阶段蒸馏技术,该模型在单张 GPU 上实现了 16 FPS 的生成速度,同时保持了叙事的一致性,超越了以往双向架构的延迟限制。
主要贡献
- 本文介绍了 ShotStream,这是一种因果多镜头架构,将视频合成重新定义为“下一镜头生成”任务,从而支持交互式叙事和通过流式提示进行即时帧生成。
- 设计了一种双缓存内存机制,通过将全局历史上下文与局部当前镜头帧分离来维持视觉连贯性,并利用 RoPE 不连续指示器明确区分这两个缓存。
- 提出了一种两阶段渐进式蒸馏策略,通过从基于真实历史数据的镜头内自强制开始,逐步过渡到基于自生成数据的镜头间自强制,从而弥合了训练与测试之间的差距;实验表明,该策略在保持与双向模型相当质量的同时实现了 16 FPS 的生成速度。
引言
当前的文本到视频模型在单镜头合成方面表现出色,但难以支持交互式叙事所需的长篇多镜头叙事。以往依赖双向架构的方法面临重大障碍,包括由于计算量呈二次方增长而导致的过高延迟,以及缺乏交互性(用户调整单个镜头时被迫重新生成整个序列)。为了解决这些挑战,作者提出了 ShotStream,这是一种因果多镜头架构,将视频合成重新定义为自回归的下一镜头生成任务。该设计通过接受流式提示并利用新颖的双缓存内存机制(配合 RoPE 不连续指示器)来维持镜头间的视觉一致性并防止误差累积,从而实现了 16 FPS 的实时即时合成。
数据集
- 数据集构成与来源:作者使用了一个内部策划的包含 32 万个多镜头视频的数据集,每个视频包含 2 到 5 个镜头,最多 250 帧。
- 标注结构:每个样本都包含分层提示,包括描述叙事弧线、角色和视觉风格的全局标题,以及详细描述每个片段具体动作和内容的镜头级标题。
- 训练数据使用:
- 完整数据集支持双向教师模型训练和初始的因果适应阶段。
- 从教师模型中采样了特定的 5000 个 ODE 解对子集,以使学生在因果注意力架构上与其对齐。
- 因果蒸馏的第一阶段使用数据集中的真实历史镜头进行镜头内自强制。
- 第二阶段使用数据集的 5 镜头子集,训练模型基于其自身生成的多镜头序列进行镜头间自强制。
- 处理与缓存策略:在镜头间训练期间,模型生成 5 秒序列,其中全局上下文缓存在镜头边界处随生成内容更新,而局部缓存则重置。
- 硬件环境:所有涉及该数据集的实验均在由 32 张 NVIDIA H800 GPU 组成的集群上进行。
方法
作者提出了 ShotStream,这是一种专为交互式叙事设计的因果多镜头架构。该方法分为两个主要阶段:双向下一镜头教师模型的训练,以及随后蒸馏为高效的因果学生生成器。
双向下一镜头教师模型
该过程首先将预训练的文本到视频模型微调为双向下一镜头生成器。其目标是根据历史上下文生成后续镜头。为了在有限的条件预算下管理历史镜头的高视觉冗余,该模型利用通过动态采样策略提取的稀疏条件上下文帧。
请参阅下方的框架图以了解该教师模型的架构。
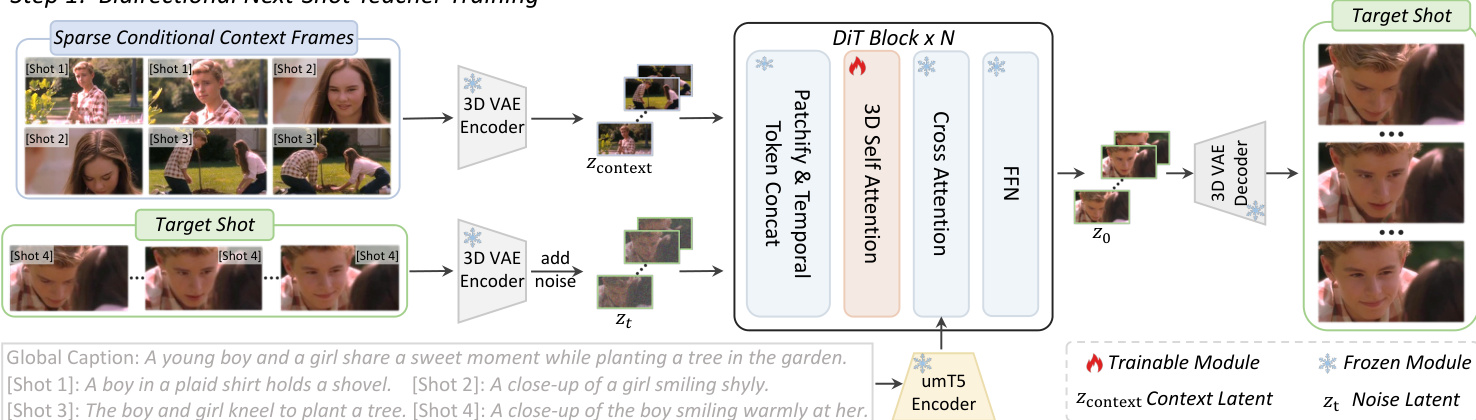
如图所示,稀疏条件上下文帧 Vcontext 和目标镜头通过 3D VAE 编码器处理以获得潜在表示。上下文潜在表示定义为:
zcontext=ε(Vcontext)其中 ε 代表 3D VAE 编码器。条件潜在表示 zcontext 和带噪声的目标潜在表示 zt 均被分块化为 token。这些 token 随后沿帧维度进行拼接,形成 DiT 块的输入:
xinput=FrameConcat(xcontext,xt)这种时间维度的拼接使得 DiT 原生的 3D 自注意力层能够在不引入新参数的情况下对条件 token 和噪声 token 之间的交互进行建模。此外,为了保持视觉信息与文本描述之间的绑定,模型通过交叉注意力机制,将每个条件上下文帧的特定标题与全局标题一起注入。
因果架构与两阶段蒸馏
为了实现低延迟生成,多步双向教师模型被蒸馏为一个高效的 4 步因果生成器。这一转变带来了关于镜头间一致性和误差累积的挑战,这些问题通过双缓存内存机制和两阶段蒸馏策略得到解决。
双缓存内存机制
为了维持视觉连贯性,作者引入了一种双缓存内存机制。全局缓存存储稀疏条件帧以确保镜头间的一致性,而局部缓存保留最近生成的帧以保证镜头内的一致性。为了防止在查询两个缓存时出现时间歧义,采用了不连续的 RoPE 策略。这通过在每个镜头边界引入离散的时间跳跃,显式地解耦了全局和局部上下文,其公式化为 Θt=ϕt+kθ,其中 θ 代表镜头边界的相位偏移。
两阶段蒸馏策略
蒸馏过程采用分布匹配蒸馏(DMD)来最小化学生分布与教师分布之间的反向 KL 散度。为了减轻自回归生成中固有的误差累积,训练分为两个阶段进行。
第一阶段是镜头内自强制,如下图所示。
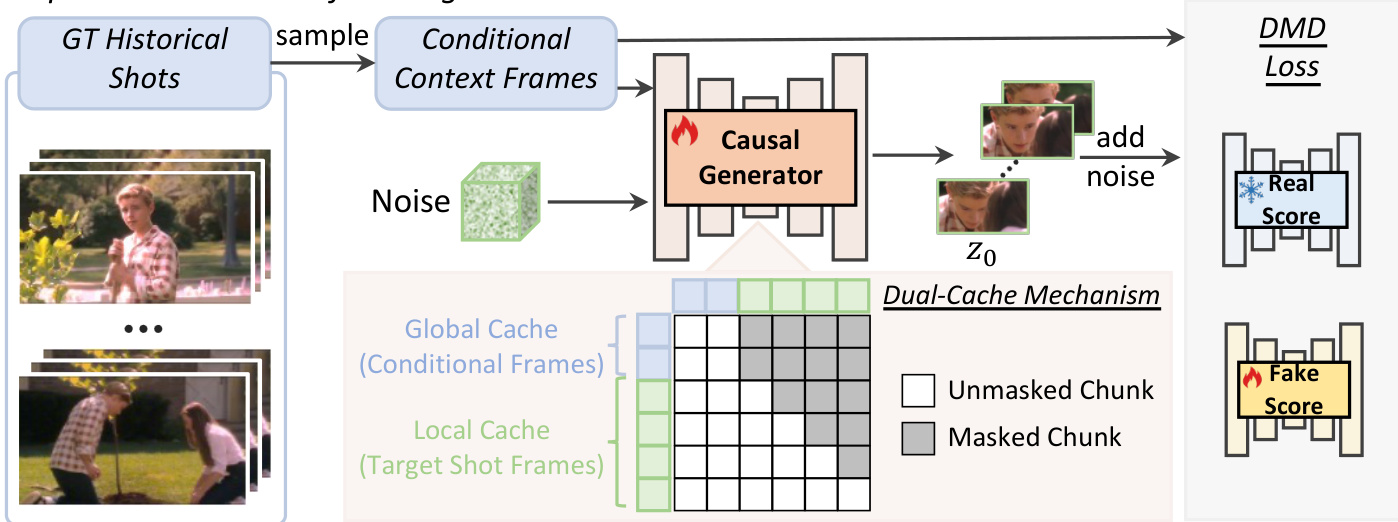
在此阶段,模型以真实历史镜头为条件,而因果生成器则逐块生成目标镜头。局部缓存利用当前目标镜头中先前自生成的块,而非真实数据,从而建立基础的下一镜头生成能力。
第二阶段是镜头间自强制,通过以模型自身不完美的历史镜头为条件,弥合了剩余的训练 - 测试差距。这一迭代过程如下图所示。
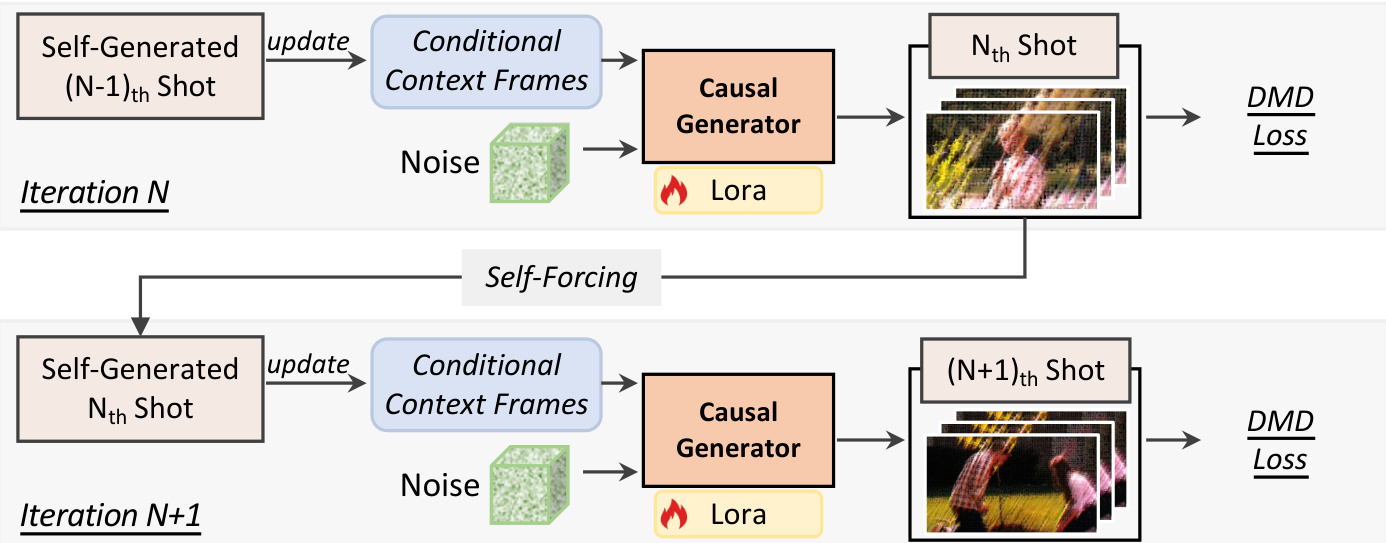
如图所示,因果模型从头开始生成初始镜头。在随后的迭代中,生成器完全基于先前自生成的镜头合成下一个镜头。在每次迭代中,模型继续采用镜头内自强制来逐块生成每个新镜头。这种自回归展开使训练与推理保持一致,有效缓解了误差累积,并提升了长视野多镜头生成的整体视觉质量。
实验
- 多镜头视频生成实验验证了所提出的方法在视觉一致性、镜头转换控制和提示对齐方面优于基线模型,同时实现了显著更高的推理吞吐量。
- 定性比较表明,与现有的双向和自回归模型相比,该方法在遵循复杂叙事提示和镜头间连贯性方面表现更优。
- 用户研究证实,参与者始终更偏好生成的视频,因其具有更好的视觉一致性、提示遵循能力和整体质量。
- 消融研究证实,动态上下文帧采样、为条件帧注入特定标题以及时间 token 拼接对于双向教师模型至关重要。
- 进一步的消融实验确认,通过 RoPE 偏移分离全局和局部缓存,以及采用两阶段蒸馏策略,对于维持因果学生模型的长期视觉风格一致性和弥合训练 - 测试差距是必不可少的。