Command Palette
Search for a command to run...
面向扩散 Transformer 中丰富多样性的上下文空间即时排斥机制
面向扩散 Transformer 中丰富多样性的上下文空间即时排斥机制
Omer Dahary Benaya Koren Daniel Garibi Daniel Cohen-Or
摘要
现代文本到图像(Text-to-Image, T2I)扩散模型已在语义对齐方面取得显著进展,然而它们往往存在多样性严重不足的问题,即针对任意给定提示(prompt),模型倾向于收敛于有限的几种视觉解。这种“典型性偏差”给需要广泛生成结果的创意应用带来了挑战。我们指出,当前提升多样性的方法面临一个根本性的权衡:修改模型输入需要昂贵的优化过程以融入生成路径的反馈;而直接作用于空间已固定的中间潜变量(latents),则容易破坏正在形成的视觉结构,导致伪影(artifacts)。本文提出一种在上下文空间(Contextual Space)中施加排斥力(repulsion)的新框架,旨在为扩散 Transformer(Diffusion Transformers)实现丰富的多样性。通过在多模态注意力通道中进行干预,我们在 Transformer 的前向传播过程中实时施加排斥力,在文本条件与涌现的图像结构相互增强的模块之间注入干预信号。这使得我们能够在视觉结构已获信息支持但构图尚未固定之前,有效引导生成轨迹。实验结果表明,在上下文空间中施加排斥力能够在不牺牲视觉保真度或语义一致性的前提下,显著提升生成结果的多样性。此外,该方法具有独特的效率优势:计算开销极小,且在现代“Turbo”模型及蒸馏模型中依然有效——而在这些模型中,传统的基于轨迹的干预方法通常难以奏效。
一句话总结
特拉维夫大学和 Snap Research 的研究人员提出了“上下文空间排斥”(Contextual Space repulsion)框架,该框架通过在多模态注意力通道中进行干预,向扩散 Transformer(Diffusion Transformers)注入即时多样性。这项技术通过在视觉定型之前引导生成意图,克服了 Flux-dev 等模型中的典型性偏差,以最小的计算开销实现了丰富的多样性。
主要贡献
- 本文提出了一种上下文空间排斥框架,该框架在扩散 Transformer 的多模态注意力通道中实施即时干预,旨在结构信息出现之后、但构图固定之前引导生成意图。
- 该方法在 Transformer 块之间引入排斥力,其中文本条件信息融合了涌现的图像结构,使模型能够在探索多样化路径的同时,将样本保持在已学习的数据流形内,从而避免视觉伪影。
- 在多个 DiT 架构上对 COCO 基准的实验表明,该方法在保持视觉保真度和语义一致性的同时,显著提升了多样性,即使在传统的干预方法失效的高效"Turbo"和蒸馏模型中也是如此。
引言
现代文生图扩散模型在语义对齐方面表现出色,但往往受困于典型性偏差,收敛于狭窄的视觉解决方案集合,限制了其在创意应用中的效用。此前恢复多样性的尝试面临一个关键权衡:上游方法通过修改输入来引入结构反馈,需要昂贵的优化成本;而下游对图像潜在变量(latents)的干预则往往会破坏已形成的视觉结构并引入伪影。作者利用扩散 Transformer 中的上下文空间,在前向传播过程中应用即时排斥,干预那些文本条件已融合涌现图像结构的多模态注意力通道。这种方法在模型获得结构信息之后、但构图固定之前重新引导指导轨迹,以最小的计算开销实现了丰富的多样性,同时保持了视觉保真度和语义一致性。
方法
作者利用多模态扩散 Transformer(DiTs)的固有结构,提出了一种用于生成多样性的新颖干预策略。与依赖静态文本嵌入的 U-Net 架构不同,DiTs 促进了文本特征 fT 和图像特征 fI 在多模态注意力(MM-Attention)块之间的双向交换。如框架图所示,标准处理流程涉及双流块,其中文本提示 p(i) 和噪声潜在变量 zt(i) 被处理以生成下一个状态 zt−1(i)。
现有方法的核心难点在于排斥力的时机和位置。上游方法作用于未获信息的噪声,而下游方法则作用于刚性的潜在流形。作者识别出由 MM-Attention 之后增强的文本令牌 f^T(l) 构成的“上下文空间”,认为这是进行多样性干预的有效环境,因为它既具有结构信息又具备概念上的灵活性。
为了实现这一目标,作者采用了一种粒子指导框架,将一批样本视为相互作用的粒子。然而,与先前将指导应用于图像潜在变量 zt 的工作不同(如下图中所示,排斥力应用于输出潜在变量),所提出的方法直接将排斥力应用于上下文空间令牌 f^T。
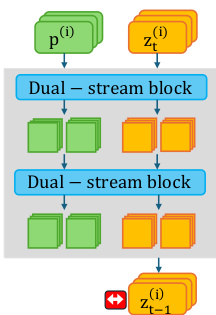
通过在该空间中强制批次样本之间的距离,模型的高层规划在承诺特定视觉模式之前即被引导。如下图中所示,干预应用于 Transformer 块内部,由上下文流上的红色箭头指示,从而允许在不通过模型层进行反向传播的情况下操纵生成意图。
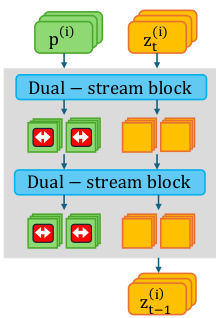
每个迭代后样本 i 的上下文令牌更新状态由下式给出:
f^T,i(l)′=f^T,i(l)+Mη∇f^T,i(l)Ldiv({f^T,j(l)}j=1B)其中 η 是总体排斥尺度,Ldiv 是定义在批次上的多样性损失。为了在整个轨迹中保持多样性,这种排斥力被应用于所有 Transformer MM 块,具体限制在指导信号最强的前几个时间步。
对于多样性目标,作者利用了 Vendi Score,它提供了一种原则性的方法来测量批次中不同样本的有效数量。这是通过分析由扁平化上下文向量构建的相似性矩阵的特征值来计算的。上下文空间编码了批次间共享的全局语义意图,使得基于批次级相似性的多样性目标更为合适。如下图中所示,这种方法允许在保持上下文空间语义对齐的同时进行多样化的插值和 extrapolation,防止了标准指导通常引起的语义崩溃。

实验
- 在上下文空间与 VAE 潜在空间中的插值和 extrapolation 实验表明,上下文空间能够实现平滑的语义转换并保持高视觉保真度,而潜在空间则由于空间不对齐而遭受结构模糊和伪影的困扰。
- 对 Flux-dev、SD3.5-Turbo 和 SD3.5-Large 架构的定性评估显示,所提出的方法生成了多样化的构图和风格,既没有下游潜在变量干预中常见的视觉伪影,也没有某些上游基线中出现的语义漂移。
- 定量分析揭示了语义多样性与图像质量之间更优越的权衡,该方法在实现更高的人类偏好和提示对齐分数的同时,比基于优化的方法产生的计算开销显著更低。
- 消融研究证实,在上下文空间进行干预比在图像令牌空间中更有效,因为它允许变化的全局构图,而不会导致导致局部纹理伪影的空间刚性。
- 在图像编辑模型上的集成测试验证了该方法不仅适用于文生图生成,还能产生多样且连贯的编辑,同时保持原始图像的完整性。