Command Palette
Search for a command to run...
视而不见,心却不忘:面向动态视频世界模型的混合记忆机制
视而不见,心却不忘:面向动态视频世界模型的混合记忆机制
Kaijin Chen Dingkang Liang Xin Zhou Yikang Ding Xiaoqiang Liu Pengfei Wan Xiang Bai
摘要
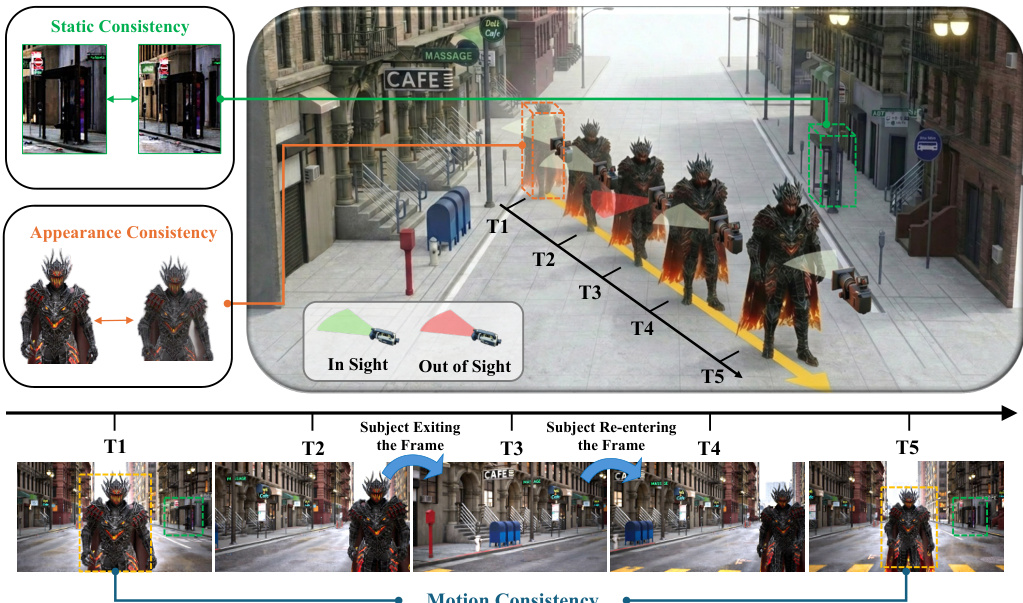
视频世界模型在模拟物理世界方面展现出巨大潜力,然而现有的记忆机制主要将环境视为静态画布。当动态主体暂时移出视野随后再次出现时,现有方法往往难以应对,导致主体出现冻结、扭曲或消失等现象。为解决这一问题,我们提出了“混合记忆”(Hybrid Memory)这一新范式,要求模型同时充当静态背景的精确档案管理员和动态主体的 vigilant 追踪器,以确保在主体不可见期间的运动连续性。为推动该方向的研究,我们构建了 HM-World,这是首个专为混合记忆设计的大规模视频数据集。该数据集包含 59,000 个高保真视频片段,其中相机轨迹与主体轨迹相互解耦,涵盖 17 种多样化场景、49 个不同主体,并精心设计了主体进出视野的事件,以严格评估混合一致性。此外,我们提出了 HyDRA,一种专用记忆架构,该架构将记忆压缩为 tokens,并采用由时空相关性驱动的检索机制。通过选择性关注相关运动线索,HyDRA 能够有效保持隐藏主体的身份特征与运动状态。在 HM-World 上的大量实验表明,我们的方法在动态主体一致性及整体生成质量方面均显著优于当前最先进(state-of-the-art)的方法。
一句话总结
华中科技大学与 Kling 团队的研究人员提出了“混合记忆”(Hybrid Memory),这是一种视频世界模型的新范式,能够在跟踪动态主体的同时保持静态背景。其 HyDRA 架构利用时空检索机制,在主体移出视野的间隔期间保持运动一致性,并在新的 HM-World 数据集上得到了验证。
主要贡献
- 本文介绍了“混合记忆”,这是一种新颖的范式,要求模型在主体移出视野的间隔期间,同时保持静态背景的空间一致性和动态主体的运动连续性。
- 这项工作提出了 HM-World,这是首个专为混合记忆研究设计的大规模视频数据集,包含 59K 个高保真片段,具有解耦的相机和主体轨迹,用于严格评估时空连贯性。
- 提出了一种名为 HyDRA 的专用记忆架构,该架构将记忆压缩为令牌(tokens),并采用时空相关性驱动的检索机制,有效重新发现隐藏的主体并保持其身份和运动。
引言
视频世界模型对于自动驾驶和具身智能等应用至关重要,但当前的记忆机制将环境视为静态画布,一旦动态主体移出视野就会失效。现有方法往往导致隐藏的角色在重新出现时消失、冻结或扭曲,因为它们缺乏在遮挡期间跟踪独立运动逻辑的能力。作者引入了“混合记忆”,这是一种新范式,要求模型同时归档静态背景并预测动态主体的不可见轨迹。为此,他们发布了 HM-World,这是首个包含解耦相机和主体运动的大规模数据集,并提出了 HyDRA,这是一种利用时空相关性驱动检索来保持隐藏实体身份和运动连续性的专用架构。
数据集
-
数据集构成与来源:作者介绍了 HM-World,这是一个大规模合成数据集,旨在解决缺乏包含进出事件的自然视频的稀缺问题。该数据集完全在 Unreal Engine 5 中生成,通过程序化组合四个核心维度:17 个多样化的 3D 场景、49 个不同的主体(人类和动物)、10 条预定义的主体轨迹以及 28 条设计的相机轨迹。
-
每个子集的关键细节:最终集合包含 59,225 个高保真视频片段。每个片段包含 1 到 3 个沿随机路径移动的主体,同时相机执行 deliberate 的往返运动,迫使主体离开并重新进入画面。该数据集的独特之处在于其包含了特定的画面内和画面外动态,而现有数据集要么缺乏动态主体,要么始终保持主体可见,要么使用静态相机。
-
在模型中的用途:该数据集作为视频世界模型中混合记忆的专用测试平台和训练资源。它使模型能够通过同时锚定静态背景和跟踪消失并重新出现的动态主体来学习时空解耦,这种能力对于在视野外外推期间保持视觉身份和一致的运动状态至关重要。
-
处理与元数据构建:渲染管线会过滤掉任何未能产生进出事件的片段。每个保留的样本都经过全面标注,包括渲染视频、由 MiniCPM-V 生成的描述性标题、精确的相机位姿、所有主体的逐帧 3D 位置,以及标记每个主体进出画面的确切时间戳。
方法
作者解决了生成一致视频序列的挑战,其中动态主体频繁地离开并重新进入相机的视野。如概念图所示,当主体被遮挡或视线之外时,在时间步(T1 到 T5)之间保持静态、外观和运动的一致性至关重要。为了实现高保真的未来帧预测,模型必须在保持静态背景的同时,主动寻找移动的主体以维持其外观和运动的一致性。
整体框架建立在完整序列视频扩散模型之上。请参阅框架图以了解完整的流水线结构。该架构包含用于时空压缩的因果 3D VAE 和用于生成的扩散 Transformer(DiT)。模型遵循流匹配(Flow Matching),其中扩散时间步通过 MLP 编码以调节 DiT 块。在训练期间,模型学习预测时间步 t∈[0,1] 处的真实速度 vt=z0−z1,最小化损失函数:
Lθ=Ez0,z1,t∣∣u(zt,t;θ)−vt∣∣2为了实现精确的空间控制,相机轨迹被作为显式条件注入。相机位姿序列被展平并通过相机编码器编码,然后逐元素添加到输入 DiT 块的潜在特征中。
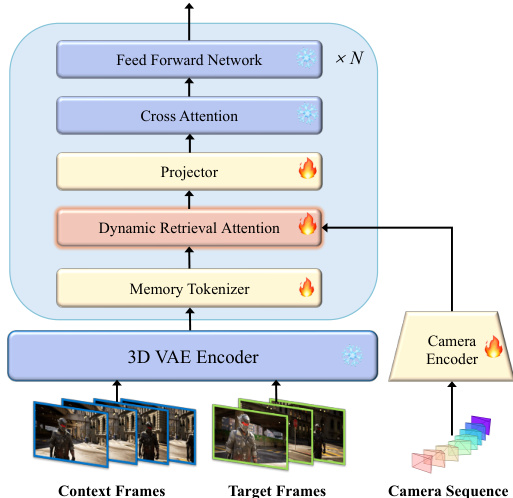
为了在不向模型注入无关噪声的情况下高效处理动态主体,作者引入了 HyDRA(混合动态检索注意力)。该模块替换了标准的自注意力层,由两个关键组件组成:记忆令牌化(Memory Tokenization)和动态检索注意力。
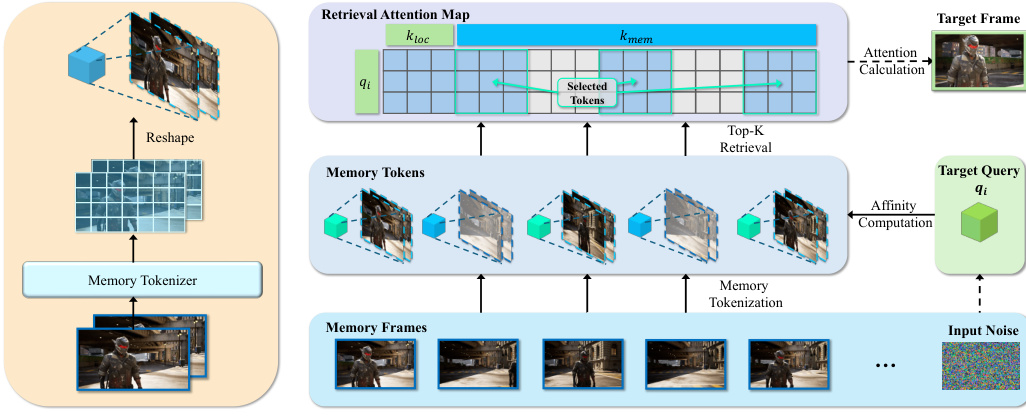
首先,记忆令牌化器处理编码后的记忆潜在变量 Zmem。不使用原始潜在变量,而是基于 3D 卷积的令牌化器扩展了时空感受野以捕获长时程运动信息,从而生成紧凑的记忆令牌 M。该变换定义为 M=Tmem(Zmem)。
其次,动态检索注意力机制计算目标查询与记忆令牌之间的时空亲和度指标。如详细模块分解所示,系统执行 Top-K 选择,基于亲和度分数 Si,j 检索最相关的记忆令牌。为了保持局部去噪稳定性,检索到的记忆特征与来自局部时间窗口的键(keys)和值(values)进行拼接。最终注意力使用标准公式计算:
Attention(qi,Ki′,Vi′)=Softmax(dqi(Ki′)T)Vi′通过迭代此过程,模型选择性地关注视线外主体的相关运动和外观线索,在确保时空一致性的同时降低计算负担。
实验
- 主要实验将提出的 HyDRA 方法与基线及最先进模型进行了比较,验证了其在复杂进出事件中保持主体身份和运动连贯性的卓越能力。
- 定性结果表明,尽管竞争方法存在主体扭曲、消失或卡顿的问题,但 HyDRA 通过有效锚定静态背景和跟踪动态主体,成功保持了混合一致性。
- 消融研究证实,记忆令牌化器内的时间交互对于捕获长期动态至关重要,移除它会导致显著的一致性失败。
- 关于令牌检索的实验表明,基于动态亲和度的选择优于静态视野过滤,因为它能自适应地检索具有丰富主体细节的关键帧,而不是依赖固定的几何重叠。
- 对检索令牌数量的分析表明,适量的令牌足以提供必要的时空上下文,而过少的数量会导致信息丢失和生成伪影。
- 开放域评估验证了该模型在未见过场景和相机运动上具有良好的泛化能力,无需特定微调即可保持强大的记忆能力。