Command Palette
Search for a command to run...
二次梯度:一种通过综合 Hessian 矩阵与梯度来桥接梯度下降法与牛顿类方法的统一框架
二次梯度:一种通过综合 Hessian 矩阵与梯度来桥接梯度下降法与牛顿类方法的统一框架
John Chiang
摘要
加速二阶优化(尤其是牛顿类方法)的收敛仍是算法研究中的关键挑战。本文在既有Quadratic Gradient (QG) 工作的基础上,进一步拓展其理论边界,并严格验证了该方法在一般凸数值优化问题中的适用性。我们提出了一种新型 QG 变体,其设计突破了传统固定 Hessian 牛顿框架的约束。尽管该变体不再满足固定 Hessian 牛顿方法的经典收敛条件,但实验结果表明,其在收敛速率上有时优于原始方法。该变体虽放宽了部分经典收敛约束,但仍保持正定 Hessian 代理矩阵,并在收敛速率方面展现出与原始方法相当、甚至在某些情形下更优的实证性能。此外,我们证明了原始 QG 及其新提出的变体均能有效应用于非凸优化场景。本研究的核心动机之一在于传统标量学习率的局限性。我们论证表明,采用对角矩阵能够以异质速率更有效地加速各梯度分量。我们的研究确立了 Quadratic Gradient 作为现代优化中一种通用且强力的框架。进一步地,我们引入 Hutchinson 估计器,通过 Hessian-向量乘积高效估计 Hessian 对角线元素。尤为重要的是,我们证明了所提出的 QG 变体在深度学习架构中表现卓越,为标准自适应优化器提供了一种鲁棒的二阶替代方案。
一句话总结
John Chiang 提出了一种新颖的二次梯度(Quadratic Gradient)变体,该变体用对角矩阵方法取代了固定的 Hessian 牛顿框架,以加速深度学习中的收敛。通过集成 Hutchinson 估计器以高效近似 Hessian 对角线,该方法在非凸优化景观中优于传统的标量学习率。
主要贡献
- 本文介绍了一种新颖的二次梯度变体,它通过维护一个正定 Hessian 代理,脱离了固定的 Hessian 牛顿框架,从而能够有效地应用于传统方法往往失效的非凸优化景观。
- 该工作集成了 Hutchinson 估计器,通过 Hessian-向量积高效地近似 Hessian 对角线,将二阶信息的计算复杂度从 O(n2) 降低到 O(n),从而实现了深度学习架构的可扩展性。
- 实验结果表明,所提出的二次梯度变体在收敛速度上达到或优于原始方法和标准自适应优化器,验证了其作为一般凸和非凸问题鲁棒二阶替代方案的实用性。
引言
现代数值优化难以平衡一阶方法(如 SGD)的可扩展性与二阶方法(如牛顿法)的快速收敛性,因为前者在病态曲率下表现不佳,而后者则面临高昂的计算成本以及对 Hessian 不定性的敏感性。此前关于二次梯度(QG)的研究在逻辑回归等特定任务中显示出潜力,但通常依赖于固定的 Hessian 近似,这限制了其通用性和理论收敛保证。作者利用一种新颖的 QG 变体,将曲率信息综合为对角矩阵以取代标量学习率,从而实现了逐维加速,同时无需满足传统固定 Hessian 牛顿方法的严格约束。通过集成 Hutchinson 估计器以高效近似 Hessian 对角线,他们建立了一个统一的框架,可扩展至一般的凸和非凸景观,为深度学习中的标准自适应优化器提供了一种鲁棒的二阶替代方案。
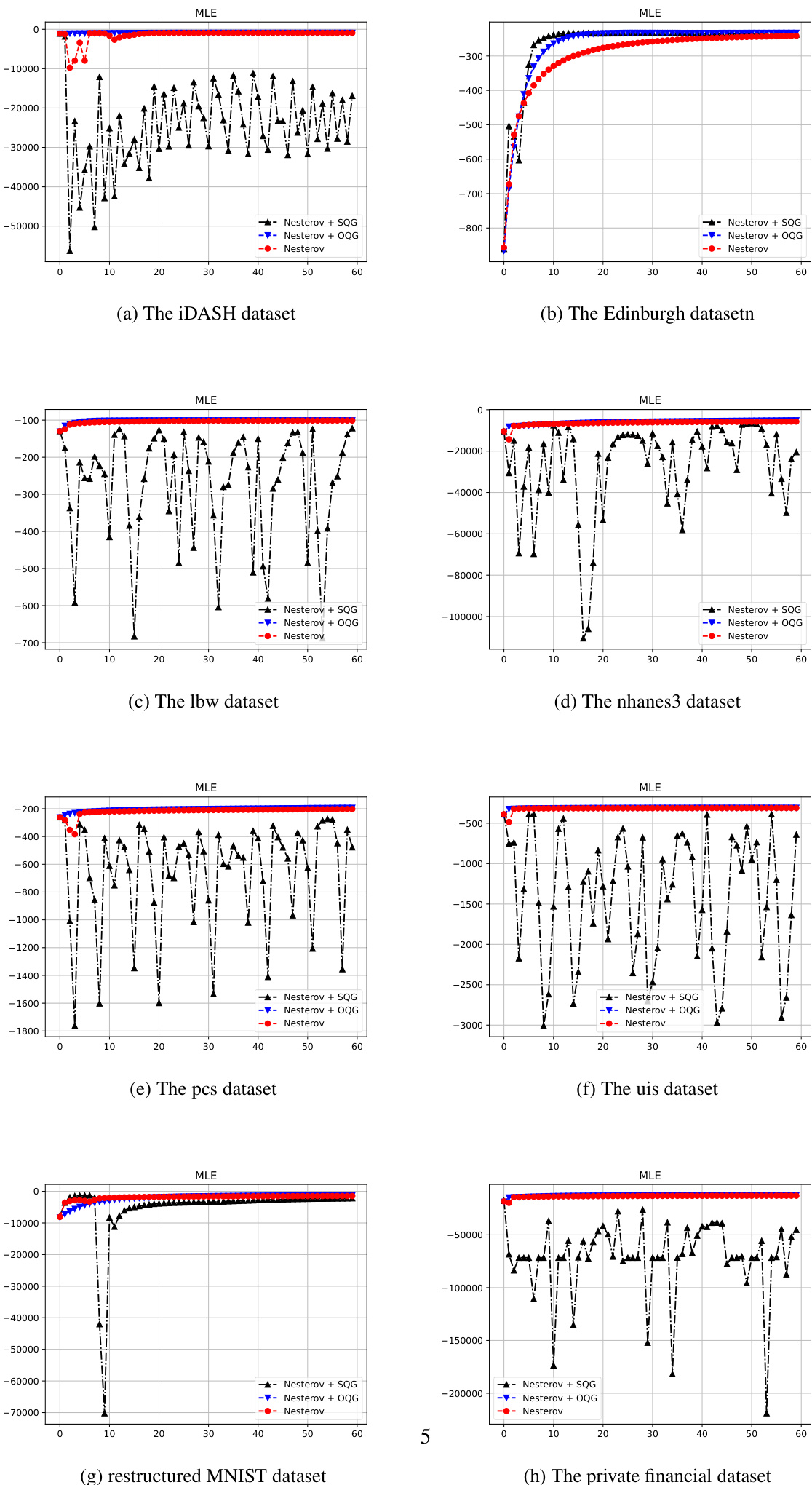
数据集
提供的文本仅在“大规模数据集”部分列出了"mnist"和"credi"这两个标题,未提供任何描述性内容。因此,无法基于此输入起草涵盖组成、来源、过滤规则、训练划分或处理策略的数据集描述。源材料中也没有关于数据集大小、元数据构建或模型使用的更多细节。
实验
- 在多个数据集上的逻辑回归实验验证了简化二次梯度(SQG)框架保持了与原始方法相当的高计算效率和收敛速度,同时提供了更精简的架构,尽管它需要为 NAG 采用保守的学习率衰减以确保稳定性。
- 在 ResNet-18 上的深度学习测试表明,新的 QG 变体比 Adam 收敛更快,并且在非凸区域比 AdaHessian 表现出更优越的稳定性,其计算开销与二阶方法相当。
- 在凸和非凸函数上的基准评估证实了该算法能够处理维度扩展并有效导航病态山谷。
- 鞍点分析显示,QG 变体通过利用谱信息沿最小曲率方向分配大的自适应步长,克服了一阶方法典型的停滞现象,使优化器能够高效地逃离鞍点。
- 总体而言,该框架通过集成 Hessian 近似来加速收敛并稳健地管理高维空间中的复杂拓扑特征,成功桥接了一阶和二阶优化。