Command Palette
Search for a command to run...
LightMover:具备颜色与强度控制的生成式光照运动
LightMover:具备颜色与强度控制的生成式光照运动
Gengze Zhou Tianyu Wang Soo Ye Kim Zhixin Shu Xin Yu Yannick Hold-Geoffroy Sumit Chaturvedi Qi Wu Zhe Lin Scott Cohen
摘要
本文提出 LightMover,这是一个面向单张图像的受控光照操作框架。该框架利用视频扩散先验(video diffusion priors),在不重新渲染场景的前提下,生成物理上合理的光照变化。我们将光照编辑建模为视觉 token 空间中的序列到序列预测问题:给定一张图像和光照控制 token,模型能够协同调整光源的位置、颜色与强度,并同步生成相应的反射、阴影及光照衰减效果,且仅需单视角输入即可实现。这种对空间(移动)与外观(颜色、强度)控制的统一处理,显著提升了操作精度与光照理解能力。此外,我们引入了一种自适应 token 剪枝机制,在保留空间信息丰富 token 的同时,对非空间属性进行紧凑编码,在保持编辑保真度的前提下将控制序列长度缩短了 41%。为训练该框架,我们构建了一个可扩展的渲染管线,能够在保持场景内容与原始图像一致的前提下,生成大量涵盖不同光源位置、颜色与强度的图像对。LightMover 实现了对光源位置、颜色与强度的精确独立控制,并在多项任务中取得了高 PSNR 值以及强语义一致性(基于 DINO、CLIP 评估)。
一句话总结
阿德莱德大学、Adobe Research 等机构的研究人员提出了 LightMover,这是一个利用视频扩散先验的框架,旨在实现单张图像中符合物理规律的光照操控。通过将编辑任务构建为带有自适应令牌剪枝的序列到序列预测问题,该框架无需重新渲染场景即可实现对位置、颜色和强度的精确控制。
主要贡献
- 本文提出了 LightMover,这是一个统一的基于扩散的框架,将光照编辑构建为序列到序列预测问题,从而实现对光照位置、颜色和强度的精确独立控制,同时生成符合物理规律的反射和阴影。
- 提出了一种自适应令牌剪枝机制,能够紧凑地编码颜色和强度等非空间属性,同时保留细粒度的空间令牌,在不过度影响编辑保真度的情况下,将控制序列长度减少了 41%。
- 开发了一个可扩展的基于物理的渲染管线,用于生成具有多样化光照条件的大规模训练数据,支持多任务训练策略,在光照操控任务的光信噪比(PSNR)和语义一致性方面达到了最先进水平。
引言
在单张图像中设计逼真的光照对于虚拟陈列等应用至关重要,但现有方法难以提供精确控制。逆渲染管线计算成本高昂,且从单视角来看是病态问题;而当前的基于扩散的编辑器缺乏明确的空间光照移动能力,或无法正确传播阴影和反射。作者引入了 LightMover,这是一个视频扩散框架,将光照操控视为序列到序列任务,以实现对位置、颜色和强度的参数化控制。他们利用一种新颖的自适应令牌剪枝策略,在不增加序列长度的情况下高效编码非空间属性,并利用可扩展的基于物理的渲染管线,在因果光照效应上训练模型。
数据集
-
数据集构成与来源:作者结合了通过基于 Blender 的管线生成的合成数据集与使用移动设备捕获的真实世界数据集。合成部分依赖于 25 个由艺术家设计的室内环境和来自 Objectverse-XL 的 100 个光源资产,而真实部分则由 106 个使用同步触发设备拍摄的室内场景组成。
-
每个子集的关键细节:
- 合成数据:通过改变灯具位置、HDRI 贴图以及环境光与直射光的比例,生成了约 32,000 对数据。每个场景的光源沿平滑轨迹动画化,由十个虚拟相机捕获,形成多视图运动对。
- 真实数据:包含 106 个场景的 360 张高分辨率照片,每个场景提供 3 到 4 种光照变化。该子集还包括背景参考图像,其中光源被物理移除,以支持光照插入和移除任务。
-
模型使用与训练策略:合成数据为学习光照移动、颜色和强度方面的视觉真实感和物理一致性提供了可扩展的监督信号。在训练期间,模型对光照强度、色相和环境色调应用额外的后处理扰动,以创建实际上无界的变异。真实数据通过提供光照移动的基准真值并支持光照操控任务的特定目标来补充这一点。
-
处理与元数据构建:渲染管线将每一帧分解为两个物理解耦的组件:环境基础图像和直接光照贡献。这些组件使用蒙特卡洛路径追踪独立渲染,并在线性 RGB 空间中进行合成。对于真实数据集,作者通过捕获唯一变量为光源位置的对来确保物理一致性,而背景图像则作为移除和插入目标的元数据。
方法
作者提出了 LightMover,这是一个重新利用预训练视频扩散 Transformer 来处理光照操控作为序列到序列预测问题的框架。该模型将各种输入条件视为按顺序排列的伪视频帧,这些帧由 VAE 编码为潜在令牌,并由扩散 Transformer 联合处理。如框架图所示,输入序列由六个不同的组件组成:参考图像(Iref)、包含裁剪目标对象的对象帧(Iobj)、编码源和目标边界框的运动图(Imove)、可选的颜色控制(Icolor)、可选的强度控制(Iintensity)以及带噪声的输出帧(Xt)。运动图具体利用 RGB 通道,用红色表示源区域,用绿色和蓝色通道表示目标区域。强度控制以摄影档(stops)量化,其中光照增益 Gillum 计算为 Gillum=2SEV,其中 SEV 代表曝光调整。
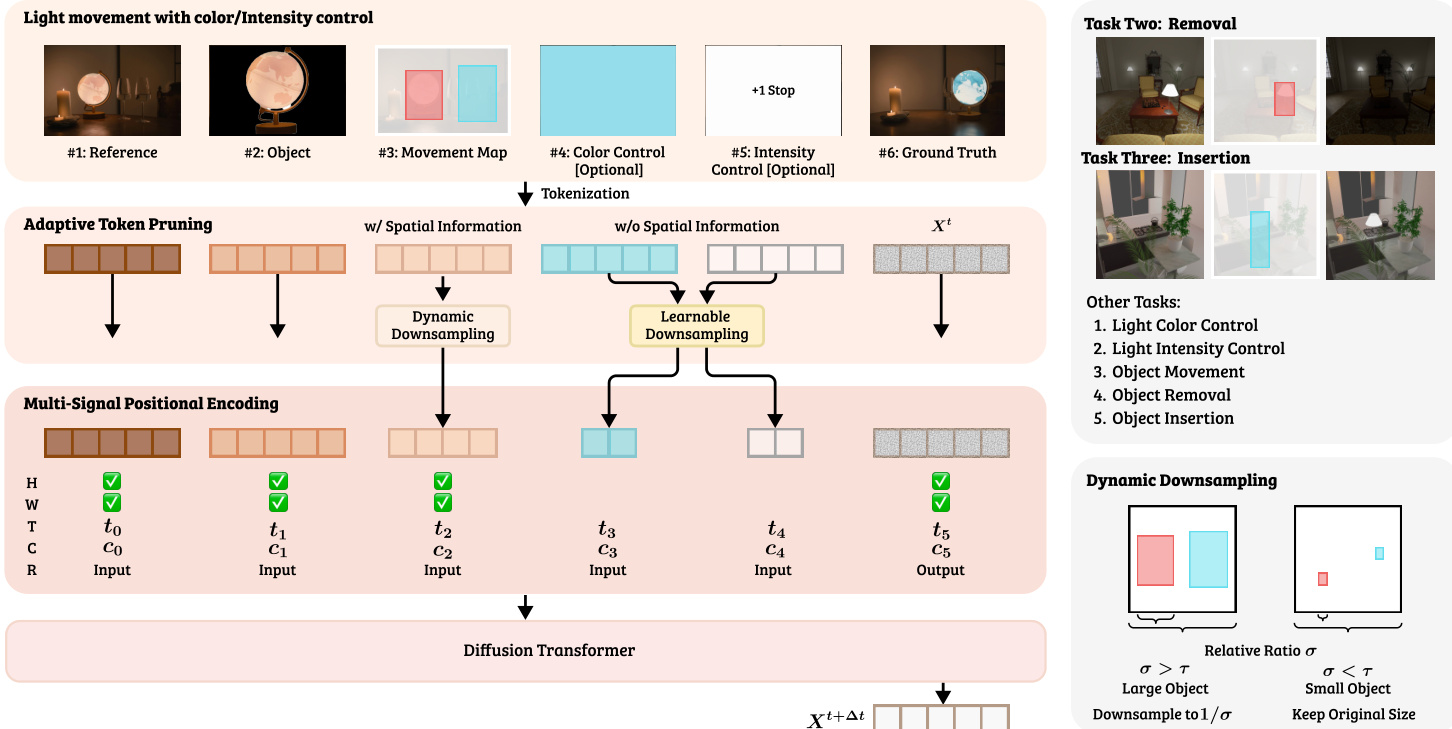
为了确保 Transformer 正确解释这些多样化的输入,作者引入了多信号位置编码(MSPE)机制。该机制通过集成四个正交子空间来扩展标准的旋转位置嵌入:用于块坐标的空间编码(W,H)、用于序列顺序的时间编码(T)、用于区分模态的条件类型编码(C),以及用于分离输入与输出的帧角色编码(R)。这些组件经过投影和组合,以实现对空间对齐和条件相互依赖性的联合推理。
为了提高计算效率同时保持生成保真度,作者采用了自适应令牌剪枝机制。该模块根据每个条件的空间属性动态调整潜在令牌的数量。对于具有明确空间信息的控制信号(如运动图),如果对象较大,则采用空间感知剪枝策略,根据边界框面积比例对令牌进行下采样。对于颜色和强度等非空间控制帧,则使用可学习的下采样,其中保留的令牌数量与扩散模型联合优化。这种方法在不降低生成质量的情况下,将平均控制序列长度减少了 41%。
在训练方面,作者构建了一个可扩展的渲染管线,用于生成大规模合成数据,这些数据结合了真实捕获的数据和光照参数的系统性变化。如下图所示,该管线在保持场景内容一致的同时,生成了具有不同光照位置、颜色和强度的图像对。重新光照过程被参数化建模,根据公式 Irelit=αIamb+GillumIlight⊙ct 组合环境和光照分量。模型使用流匹配目标进行训练,其中带噪声的输入通过线性插值生成,模型预测瞬时速度以最小化损失 L=Et,X0,X1[∥v(St,t;θ)[6]−Vt∥2]。

实验
- LightMover 在真实世界和合成基准上进行了评估,以验证其在保持物理合理性的同时执行精确光照移动、插入和移除的能力。
- 与基于大语言模型(LLM)的文本到图像模型和对象移动基线的比较表明,LightMover 实现了更优越的定位精度,并能更好地处理复杂的全球光照效应,如阴影、反射和特定材质的着色。
- 该模型显示出对涉及同时移动、颜色和强度变化的联合控制任务的强大泛化能力,在单属性和多属性场景中均优于基线。
- 消融研究证实,与多样化的合成任务共同训练以及使用物理解耦的渲染增强,对于解耦光源和学习全局光照组合至关重要。
- 关于令牌剪枝策略的实验表明,基于帧的条件化结合自适应下采样对于平衡效率与复杂多属性光照控制所需的精度至关重要。
- 定性分析证实,该模型能够准确重现真实阴影几何、高光反射和反射一致性,而不会引入视觉伪影。