Command Palette
Search for a command to run...
RealRestorer:面向基于大规模图像编辑模型的通用真实世界图像复原
RealRestorer:面向基于大规模图像编辑模型的通用真实世界图像复原
摘要
真实场景下的图像复原对于自动驾驶、目标检测等下游任务至关重要。然而,现有复原模型往往受限于训练数据的规模与分布,导致其在真实场景中的泛化能力不足。近期,大规模图像编辑模型在复原任务中展现出强大的泛化能力,尤其是像 Nano Banana Pro 这样的闭源模型,能够在复原图像的同时保持内容一致性。尽管如此,利用此类大型通用模型实现同等性能需要耗费大量的数据与计算资源。针对这一问题,我们构建了一个覆盖九种常见真实世界退化类型的大规模数据集,并训练了一个最先进的开源模型,以缩小其与闭源方案之间的性能差距。此外,我们提出了 RealIR-Bench,该基准包含 464 张真实世界退化图像,并设计了专注于退化去除与一致性保持的定制化评估指标。大量实验表明,我们的模型在开源方法中位居首位,达到了当前最先进(SOTA)的性能水平。
一句话总结
StepFun 与南方科技大学的研究人员提出了 RealRestorer,这是一个基于新的大规模数据集训练的开源模型,旨在恢复多样化的真实世界图像退化。该方法缩小了与闭源替代方案的性能差距,并引入了 RealIR-Bench,用于在自动驾驶和目标检测等场景中进行严格评估。
主要贡献
- 本文介绍了 RealRestorer,这是一个开源图像恢复模型,基于大型图像编辑架构微调而成,能够处理九种常见的真实世界退化类型,同时达到与闭源系统相当的最先进性能。
- 开发了一套全面的数据生成流程,用于合成具有多样性和代表性退化的高质量训练数据,有效缩小了合成分布与真实世界条件之间的差距。
- 提出了 RealIR-Bench 作为新基准,包含 464 张真实世界退化图像,并设计了定制评估指标,以在真实场景中评估退化去除效果和一致性保持能力。
引言
真实世界图像恢复对于自动驾驶和目标检测等关键下游应用至关重要,但现有模型由于依赖有限的合成训练数据,难以捕捉真实世界退化的复杂性,导致泛化能力不足。虽然大规模闭源图像编辑模型表现出卓越性能,但其高昂的计算成本和缺乏透明度阻碍了可复现性及更广泛的研究采用。为解决这些挑战,作者利用全面的数据合成流程训练了 RealRestorer,这是一个开源模型,通过微调大型图像编辑架构,在九种退化类型上实现了最先进结果。此外,作者还推出了 RealIR-Bench,这是一个包含真实退化图像和定制指标的新基准,旨在不依赖干净参考图像的情况下,更好地评估恢复质量和内容一致性。
数据集
-
数据集构成与来源 作者通过结合两个主要来源构建了涵盖九种图像恢复任务的全面数据集:合成退化数据和真实世界退化数据。合成部分利用从互联网收集的干净图像,而真实世界部分则从网络平台以及 Pexels 和 Pinterest 等高质量开源网站获取自然退化的图像。
-
各子集的关键细节
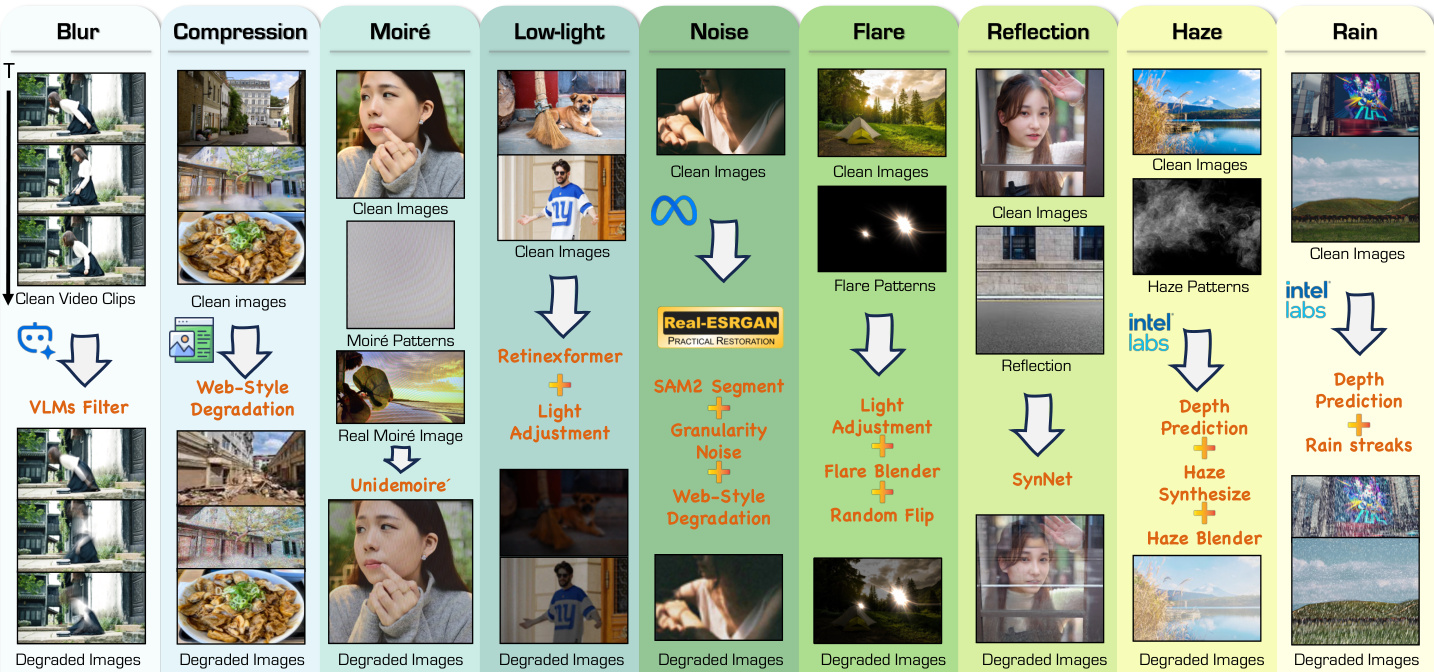
- 合成退化数据:该子集通过对干净图像应用特定退化模型来生成配对数据。作者利用 SAM-2 和 MiDaS 等开源模型提取语义掩码和深度线索,以实现逼真的合成。
- 模糊:通过视频片段的时间平均以及高斯模糊等网络风格操作合成。
- 压缩伪影:使用 JPEG 压缩和重缩放模拟网络效果。
- 摩尔纹:通过将 3,000 个生成的多尺度图案融合到干净图像中创建。
- 低光照:通过亮度衰减、伽马校正以及在 LOL 和 LSRW 数据集上训练的专用模型实现。
- 噪声:采用网络风格退化,添加颗粒状和分段感知噪声。
- 眩光:涉及将收集的 3,000 多个眩光图案与随机翻转进行混合。
- 反射:遵循 SynNet 流程,将人像图像作为透射层,多样化场景作为反射层进行组合。
- 雾霾:使用大气散射模型生成,并辅以近 200 个收集的雾霾图案增强。
- 雨:结合飞溅和透视畸变等物理效应,以及 200 个真实雨图案和来自 FoundIR 数据集的 7 万个样本。
- 真实世界退化数据:该子集将真实退化图像与由高性能恢复模型生成的干净参考图像配对。它涵盖了六种退化类型(模糊、雨、低光照、雾霾、反射和眩光),这些类型与合成图案相比存在显著差距。
- 合成退化数据:该子集通过对干净图像应用特定退化模型来生成配对数据。作者利用 SAM-2 和 MiDaS 等开源模型提取语义掩码和深度线索,以实现逼真的合成。
-
数据使用与处理 作者采用严格的过滤流程以确保数据质量和对齐。
- 过滤:视觉 - 语言模型(VLMs)和质量评估模型用于移除带水印或低质量的图像。CLIP 根据语义线索过滤真实世界数据,而 Qwen3-VL-8B-Instruct 验证退化严重程度。
- 对齐检查:团队使用低级指标和基于骨架偏移的方法来检测退化图像与干净图像对之间的内容偏移和对齐错误。
- 人工策展:部分过滤后的配对由三位专家进行人工审查,以确认退化类型和严重程度的对齐。
- 训练混合:最终训练集结合了合成和真实世界配对,并针对每种退化类型提供了具体统计数据以平衡数据集。
-
基准与评估 作者推出了 RealIR-Bench,这是一个包含 464 张非参考退化图像(直接源自互联网)的测试集。该基准涵盖所有九种恢复任务,并包含复杂的混合退化。评估使用固定的增强指令以最小化指令变化,重点关注恢复能力和场景一致性。质量评估使用 LPIPS、RS 和 FS 等指标,并结合人工评分以评估增强能力和整体视觉质量。
方法
所提出的方法基于 Step1X-Edit 基础模型,该模型利用对生成任务有效的 Transformer 扩散(DiT)骨干网络。该架构集成了 QwenVL 作为文本编码器,将高级语义提取注入到 DiT 去噪路径中。在扩散网络中,采用双流设计以联合处理语义信息、噪声以及条件输入图像。参考图像和输出图像均使用 Flux-VAE 编码到潜在空间。在训练阶段,Flux-VAE 和文本编码器被冻结,仅对 DiT 组件进行微调。
训练策略分为两个不同阶段以优化恢复性能。第一阶段是迁移训练阶段,旨在利用合成配对数据将图像编辑的高级知识和先验迁移到图像恢复中。该阶段在 1024×1024 的高分辨率下运行,学习率恒定为 1e−5,全局批量大小为 16。为确保广泛的泛化能力,针对九种退化任务中的每一种采用单一且固定的提示,并在多任务学习中使用平均采样率。
第二阶段涉及监督微调,以增强在真实世界退化场景下的恢复保真度和泛化能力。该阶段强调利用余弦退火学习率调度来适应复杂且真实的退化模式。采用渐进式混合(Progressively-Mixed)训练策略,保留少量合成配对样本与真实世界数据混合,以防止过拟合并保持跨任务鲁棒性。此外,引入了网络风格退化数据增强策略,以提高对通常存在低视觉质量和压缩伪影的网络采集图像的鲁棒性。
该流程针对九种特定的退化类型:模糊、压缩伪影、摩尔纹、低光照、噪声、眩光、反射、雾霾和雨。如下图所示,这些多样化退化的数据生成过程涉及特定的处理步骤,如 VLMs 过滤、使用 Retinexformer 进行低光照调整以及使用 Real-ESRGAN 进行噪声模拟,最终生成用于训练的退化图像。
实验
- RealIR-Bench 评估验证了 RealRestorer 能有效去除多样化的真实世界退化并保持内容保真度,在包括去模糊、低光照增强和反射去除在内的九项任务中,在开源模型中排名第一,并紧随顶级闭源系统之后。
- FoundIR 基准测试确认,与其他图像编辑模型相比,该模型在独立退化任务上实现了更优越的性能,尽管生成方法在基于参考的指标上存在固有局限性,但仍展示了恢复质量与感知一致性之间的强大平衡。
- 零样本泛化实验表明,该模型通过利用学习到的先验知识,无需特定微调即可成功处理未见过的恢复场景,如除雪和老照片修复。
- 消融研究证实,结合合成和真实世界数据的两阶段训练策略至关重要,因为它能防止过拟合和伪影,同时确保鲁棒的泛化能力和结构一致性。
- 用户研究和指标相关性分析验证,所提出的非参考评估框架与人类判断高度一致,证实了该模型能够产生视觉稳定且连贯的结果。