Command Palette
Search for a command to run...
MSA:面向高效端到端记忆模型扩展至 1 亿 tokens 的稀疏记忆注意力机制
MSA:面向高效端到端记忆模型扩展至 1 亿 tokens 的稀疏记忆注意力机制
摘要
长期记忆是人类智能的基石。使人工智能能够处理跨越整个生命周期的信息,一直是该领域长期追求的目标。受限于全注意力架构,大语言模型(LLM)的有效上下文长度通常被限制在 100 万 tokens 以内。现有方法,如混合线性注意力机制、固定大小的记忆状态(例如 RNN),以及外部存储方案(如 RAG 或 Agent 系统),试图突破这一限制。然而,随着上下文长度的增加,这些方法往往面临精度急剧下降、延迟迅速攀升、无法动态修改记忆内容或缺乏端到端优化等问题。这些瓶颈阻碍了大规模语料摘要、数字孪生(Digital Twins)以及长历史 Agent 推理等复杂场景的应用,同时限制了记忆容量并拖慢了推理速度。本文提出 Memory Sparse Attention(MSA),这是一个端到端可训练、高效且具备大规模扩展性的记忆模型框架。通过可扩展稀疏注意力机制和文档级 RoPE 等核心创新,MSA 在训练和推理过程中均实现了线性复杂度,同时保持了卓越的稳定性;在上下文长度从 16K 扩展至 1 亿 tokens 的过程中,性能退化低于 9%。此外,结合 KV 缓存压缩与 Memory Parallel 技术,MSA 能够在 2 张 A800 GPU 上实现 1 亿 tokens 的推理。我们还提出了 Memory Interleaving 方法,以支持跨分散记忆片段的多跳复杂推理。在长上下文基准测试中,MSA 的表现显著超越了前沿 LLM、最先进 RAG 系统以及领先的记忆 Agent。这些结果表明,通过将记忆容量与推理能力解耦,MSA 为赋予通用模型内在的、跨越整个生命周期的记忆能力,提供了一个可扩展的基础。
一句话总结
盛大集团与北京大学的研究人员提出了记忆稀疏注意力(Memory Sparse Attention, MSA),这是一个端到端框架,利用可扩展的稀疏注意力和文档级 RoPE 实现线性复杂度。该方法能够在有限的 GPU 上实现稳定的 1 亿 token 推理,在长语料摘要和多跳推理任务中优于 RAG 系统。
主要贡献
- 本文介绍了记忆稀疏注意力(MSA),这是一个端到端可训练的框架,结合了可扩展的稀疏注意力架构与文档级 RoPE,在训练和推理中实现线性复杂度,同时在从 16K 扩展到 1 亿 token 时保持精度稳定,性能下降小于 9%。
- 提出了一种记忆交错(Memory Inter-leaving)机制,以促进跨分散记忆段的复杂多跳推理,解决了从海量上下文的非连续部分检索和利用信息的挑战。
- 实验表明,MSA 在长上下文基准测试中显著优于前沿语言模型、最先进的 RAG 系统和领先的记忆代理,同时通过 KV 缓存压缩和记忆并行(Memory Parallel)技术,在 2 张 A800 GPU 上实现了 1 亿 token 的推理。
引言
长期记忆对于数字孪生和复杂代理推理等 AI 应用至关重要,然而当前的语言模型通常受限于全注意力架构的计算约束,被限制在 100 万 token 以内。先前的方法如 RAG 系统存在精度损失且缺乏端到端可训练性,而潜在状态方法(如线性注意力或 KV 缓存压缩)要么在扩展时迅速退化,要么成本高昂。为了克服这些障碍,作者引入了记忆稀疏注意力(MSA),这是一个端到端可训练的框架,结合了稀疏注意力与文档级 RoPE,以实现线性复杂度并在 1 亿 token 范围内保持高精度。该方法在标准硬件上实现了高效推理,同时支持记忆交错等高级机制,以在巨大的上下文窗口中进行稳健的多跳推理。
数据集
- 作者构建了一个多样化的预训练语料库,包含 1589.5 亿 token 和 1790 万个查询,以平衡强大的检索能力与广泛的一般知识。
- 数据集涵盖多个领域,从科学文献到一般社区问答。
- 为确保分布平衡,KALM 套件之外任何超过 50 万查询的数据集均被下采样至最多 50 万查询。
- KALM 指令数据完整保留,未进行下采样。
- 完整语料库作为模型预训练的基础,旨在同时实现专业的检索性能和通用的语言理解能力。
方法
作者提出了 MSA(记忆稀疏注意力),这是一个统一的、端到端可训练的潜在记忆框架,专为海量记忆问答设计。MSA 的核心原则是将记忆稀疏检索和答案生成的过程无缝集成到单个联合优化的架构中,超越了传统解耦的“检索后阅读”流程的局限性,同时保留了处理长上下文记忆的能力。
稀疏注意力机制
为了在潜在状态层面高效处理海量记忆,MSA 用基于文档的检索稀疏注意力机制取代了标准的密集自注意力。请参阅下图了解 MSA 层的内部结构。
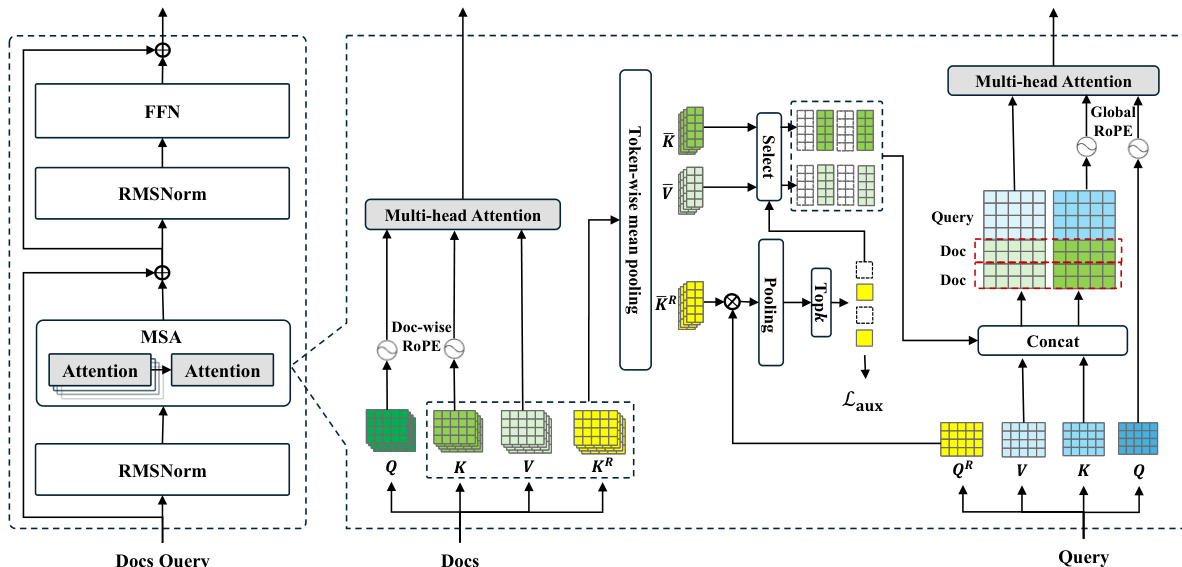
形式上,设记忆库由一组文档 D={d1,d2,…,dN} 组成。对于每个文档 di,模型通过骨干网络的投影权重生成标准的键 Ki,h 和值 Vi,h 矩阵。同时,一个路由键投影器(Router K Projector)生成专用的路由键矩阵 Ki,hR:
Ki,h=HiWKh,Vi,h=HiWVh,Ki,hR=HiWKRh.为了显著减少内存占用和检索复杂度,作者将每个文档分割成多个固定长度的块,并执行块级平均池化(记为 ϕ(⋅)),将这些状态压缩为潜在表示。由此得到压缩矩阵 Kˉi,h、Vˉi,h 和 Kˉi,hR。
在推理过程中,给定具有隐藏状态 Hq 的用户查询,模型通过路由查询投影器(Router Q Projector)计算标准状态 Qq,h,Kq,h,Vq,h 和特定的路由查询 Qq,hR。第 i 个文档的第 j 个块的相关性得分 Sij 计算为查询路由向量与记忆压缩路由键之间的余弦相似度,并在注意力头之间进行聚合。为了识别最相关的记忆段,对查询 token 级别的相关性得分应用最大池化:
Sij=tokent,headhmax(mean(cos((Qq,hR)t,Kˉij,hR))).基于这些得分,系统选择 Top-k 文档的索引。最后,通过将选定文档的压缩键和值矩阵拼接在查询的本地缓存之前来进行生成。随后,模型执行自回归生成,其中来自活动 token 的查询 Qq 关注这个聚合的、感知稀疏性的上下文:
Kctx=[{Kˉi}i∈I;Kq],Vctx=[{Vˉi}i∈I;Vq],Output=Attention(Qa,Kctx,Vctx).作者选择性地实施 MSA 路由策略,仅将其应用于模型后半部分的层。实证分析表明,初始层中的隐藏状态无法捕捉有效检索所需的高级语义抽象,使得路由机制在这些深度上效率低下。
位置编码
为了确保在不同记忆规模下的稳健泛化,MSA 为每个文档使用独立的 RoPE。标准的全局位置编码会在拼接序列上分配单调递增的位置 ID,导致随着文档数量增加,位置索引发生剧烈偏移。通过为每个文档分配独立的位置 ID(从 0 开始),MSA 将位置语义与记忆中的文档总数解耦。因此,模型可以有效地外推,即使仅在较小子集上训练,也能在海量记忆上下文中保持高检索和推理精度。
作为这种并行策略的补充,作者对活动上下文(包括用户查询和随后的自回归生成)使用全局 RoPE。这些 token 的位置 ID 会根据检索到的文档数量进行偏移。具体而言,查询的位置索引从 k 开始(对应于 Top-k 检索到的压缩 KV)。这种策略性偏移确保模型将活动上下文视为检索到的背景信息的逻辑延续。
训练过程
为了使模型具备强大的检索能力,作者在去重语料库上进行了持续预训练。这一阶段的主要目标是训练模型执行生成式检索,即模型自回归地生成相关文档的唯一文档 ID。
为了明确指导内部稀疏注意力机制,超越标准生成损失 LLLM 提供的监督,引入了辅助损失 Laux 来监督逐层路由过程。在每个 MSA 层中,路由投影器负责选择 Top-k 个最相关的文档。辅助损失定义为监督对比目标:
Laux=−∣P∣1i=1∑∣P∣logexp(si+/τ)+∑i=1∣N∣exp(si,i−/τ)exp(si+/τ),其中 τ 是温度参数。该目标明确强制在潜在路由空间中分离相关和不相关的文档块。
为了确保稳定性,采用了两阶段优化计划。在初始预热阶段,重点是将内部路由投影器对齐,损失函数为 L=0.1LLLM+Laux。预热完成后,系统过渡到主要预训练阶段,此时损失权重调整为 L=LLLM+0.1Laux。在持续预训练之后,针对问答任务实施了两个阶段的课程学习策略进行 SFT,将记忆上下文长度从 8k 扩展到 64k token,以提高数据质量和长度外推能力。
推理流程
推理流程旨在通过以下三个不同的阶段高效处理大规模记忆库,如下图所示。
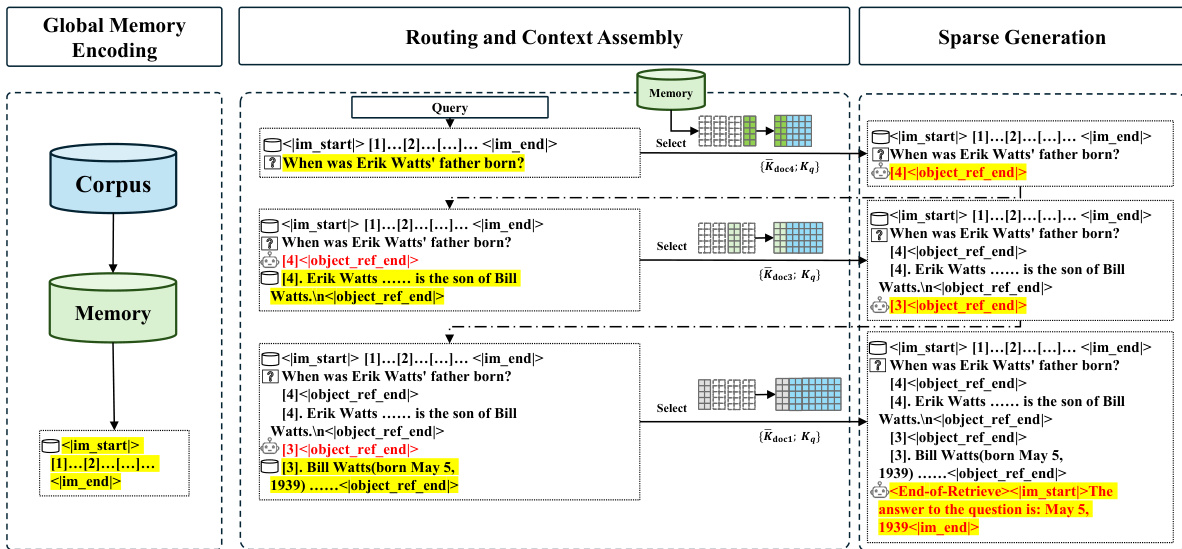
阶段 1:全局记忆编码(离线)。 此阶段是对整个文档语料库的一次性离线预计算。对于每个文档,模型执行前向传播以生成标准的 K 和 V 矩阵,同时专用的路由 K 投影器生成路由键矩阵 KR。所有三个矩阵都被分割成块并通过平均池化进行压缩。生成的紧凑表示被缓存在记忆库中。
阶段 2:路由与上下文组装(在线)。 此阶段在收到用户问题时启动。模型计算问题的隐藏状态,并通过路由 Q 投影器将其投影以获得路由查询 QqR。该查询与缓存的全局路由键 KˉR 进行匹配,以计算相关性得分并识别 Top-k 文档。关键在于,仅加载这些选定文档的紧凑键和值矩阵,并将其与问题的本地 Kq 和 Vq 拼接,形成最终的稀疏上下文。
阶段 3:稀疏生成(在线)。 在最后阶段,模型在组装好的稀疏上下文上执行自回归操作。标准注意力机制计算活动 token 的查询 Qq 与拼接的 KV 对之间的交互,逐 token 生成最终答案。
为了处理需要多跳推理的复杂查询,MSA 集成了自适应记忆交错机制。这本质上是以迭代方式执行路由、上下文组装和稀疏生成。推理过程在生成式检索和上下文扩展之间交替,其中检索到的文档被视为下一次迭代的查询的一部分。此循环自适应地重复,直到模型确定累积的文档已足够,此时它过渡到生成最终答案。
效率与扩展
MSA 在训练和推理模式下均实现了相对于记忆大小 L 的线性复杂度。为了在标准单节点上实现极端长度的记忆推理,作者实现了一个专门的推理引擎,称为记忆并行(Memory Parallel)。该引擎支持在有限的 GPU 资源下对高达 1 亿 token 的海量记忆上下文进行推理。
采用分层记忆存储策略以解决容量限制。路由键(KˉR)分布在多个 GPU 的显存中,以确保低延迟检索,而记忆库的主体,即内容 KV(Kˉ, Vˉ),则存储在主机 DRAM(CPU 内存)中。在通过 GPU 评分识别出 Top-k 相关块后,仅异步将相应的内容 KV 从主机获取到 GPU。此外,还使用了记忆并行检索策略,其中查询隐藏状态被广播到所有 GPU,每个 GPU 独立计算与其本地路由键分片之间的相似度得分,然后通过全局归约识别 Top-k 索引。
实验
- MSA 在九个多样化的 QA 基准测试和 RULER“大海捞针”任务上进行了评估,以验证其与同骨干 RAG 系统、最佳 RAG 配置以及长上下文记忆架构相比的有效性。
- 该模型表现出对标准 RAG 基线的一致优越性,并在与使用显著更大生成器的系统相比时实现了具有竞争力或顶尖的性能,证明其架构设计有效地隔离并增强了检索和推理能力。
- 从 32K 到 1M token 的上下文扩展实验证实,MSA 保持了卓越的稳定性和高检索精度,避免了未修改骨干网络和其他长上下文模型中观察到的灾难性退化。
- 消融研究验证了双阶段课程学习策略、用于多跳推理的记忆交错机制、用于路由精度的持续预训练以及原始文档文本的集成都是系统整体性能的关键组成部分。
- 对高达 1 亿 token 的上下文退化分析显示,MSA 在最小性能损失的情况下保持了高生成质量,成功地将推理能力与海量记忆容量解耦。