Command Palette
Search for a command to run...
TOOLACE:在 LLM 函数调用中胜出
TOOLACE:在 LLM 函数调用中胜出
摘要
函数调用(Function Calling)显著拓展了大语言模型(LLM)的应用边界,而高质量且多样化的训练数据对于释放这一能力至关重要。然而,收集与标注真实的函数调用数据极具挑战性,现有流程生成的合成数据往往在覆盖范围和准确性上存在不足。本文提出 ToolACE,这是一种自动化的智能体(Agent)流水线,旨在生成准确、复杂且多样化的工具学习数据,专门针对 LLM 的能力进行优化。ToolACE 利用一种新颖的自我进化合成过程,构建了包含 26,507 个多样化 API 的综合 API 池。在复杂度评估器(Complexity Evaluator)的引导下,通过多智能体之间的交互进一步生成对话数据。为确保数据准确性,我们实施了一套结合基于规则与基于模型检查的双重验证系统。实验表明,即使仅使用 8B 参数的模型,在基于我们合成数据进行训练后,也能取得最先进(SOTA)的性能,其表现可与最新的 GPT-4 模型相媲美。我们的模型及部分数据集已公开,访问地址为:https://huggingface.co/Team-ACE。
一句话总结
作者提出了 ToolACE,这是一个自动化的 Agent 流程,它利用新颖的自进化合成过程,通过复杂度评估器引导的多 Agent 交互以及双层验证系统,从 26,507 个多样化的 API 生成准确、复杂且多样化的工具学习数据,使仅拥有 80 亿参数的模型即可实现与最新 GPT-4 模型相当的最先进函数调用性能,且模型和数据子集均已公开。
核心贡献
- 这项工作介绍了 ToolACE,一个自动化 Agent 流程,旨在通过新颖的自进化合成过程生成准确且多样化的工具学习数据。该系统策划了一个包含 26,507 个多样化工具的综合 API 池,并利用多 Agent 交互创建复杂对话。
- 开发了一种自引导复杂化策略,在大语言模型复杂度评估器的指导下,生成具有适当复杂度级别的函数调用对话。数据质量通过双层验证系统维持,该系统集成了基于规则和基于模型的检查器以确保可执行性。
- 在 BFCL 和 APIBank 基准测试上的实验结果表明,使用此合成数据训练的模型实现了最先进的性能。即使使用此方法训练的 80 亿参数模型也优于现有的开源 LLM,并与最新的 GPT-4 模型竞争。
引言
为大语言模型配备函数调用能力对于在复杂现实场景(如工作流自动化和财务报告)中部署 AI Agent 至关重要。然而,进展受到标注真实数据稀缺和现有合成数据集覆盖范围差的限制。作者提出了 ToolACE,这是一个自动化流程,通过自进化合成过程和多 Agent 对话生成来创建准确且多样化的工具学习数据。他们的系统包括一个双层验证框架以确保质量,使较小的模型能够匹配大型专有系统的性能。
数据集
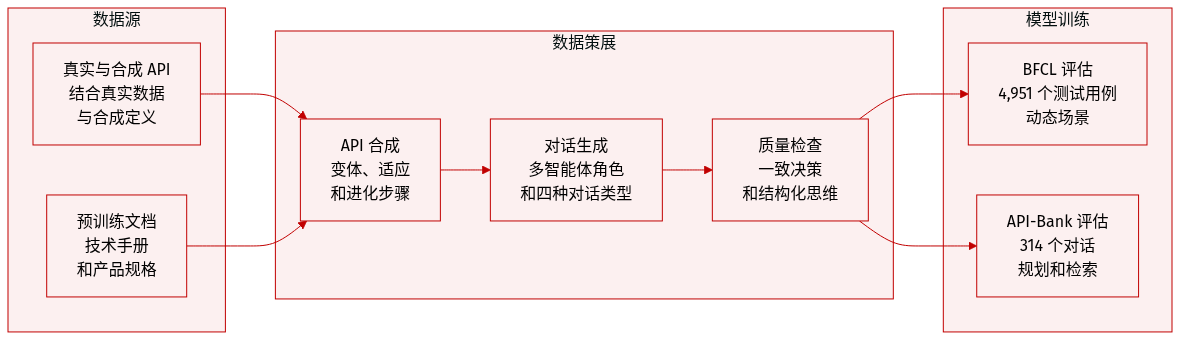
- 数据集组成和来源: 作者构建了一个综合 API 池,结合了真实 API 数据和合成定义。他们从技术手册、产品规格和教程等预训练数据源中提取领域信息。
- 合成方法: 工具自进化合成模块通过三个步骤创建多样化的 API。分类构建从原始文档构建分层上下文树。适应采样子树以确保 API 之间的功能不同。进化利用示例缓冲区和参数变异等多样性指标迭代改进定义。
- 对话生成: 多 Agent 框架模拟用户、助手和工具角色以生成功能调用对话。系统生成了四种对话类型,包括单次调用、并行调用、依赖调用和非工具使用交互。
- 质量保证: 为了维持数据质量,作者多次生成每个助手动作,仅保留决策一致的回答。结构化思维过程指导助手做出准确的工具调用决策。
- 评估基准: 模型使用伯克利函数调用基准进行评估,该基准包含 4,951 个动态场景测试用例。他们还利用 API-Bank 的 314 个工具使用对话来评估规划和检索能力。
- 数据结构: 生成的 API 文档支持复杂的嵌套类型,包括列表的列表或字典的列表。
方法
作者利用名为 ToolACE 的模块化、Agent 框架来生成高质量、多样化且复杂的函数调用数据,这些数据针对给定大语言模型 (LLM) 的能力进行了定制。整体架构如框架图所示,包含三个核心组件:工具自进化合成 (TSS)、自引导对话生成 (SDG) 和双层验证 (DLV)。这些组件以协调的方式工作,递归地合成 API,生成具有自适应复杂度的上下文相关对话,并通过自动化和人工介入验证确保数据准确性。
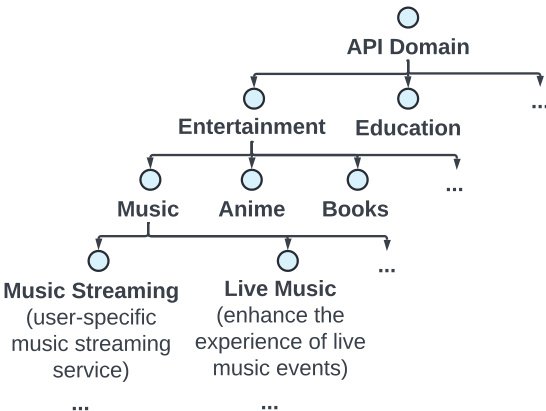
第一个模块,工具自进化合成 (TSS),负责生成丰富且多样化的 API 集。它通过递归进化分层 API 上下文树来运行,该树基于预训练数据构建,并围绕 API 领域结构化。如下图所示,该树将 API 组织为广泛的类别,如娱乐和教育,进一步分支到具体的子领域,如音乐和书籍。合成过程使用自进化和更新机制,基于现有示例和上下文信息迭代生成新 API,确保工具功能的广泛且具有代表性的覆盖。
第二个模块,自引导对话生成 (SDG),合成对目标 LLM 复杂度适当的函数调用对话。该模块旨在解决模型能力与生成数据难度之间的不匹配。它由一个多 Agent 系统组成,其中用户 Agent、助手 Agent 和工具 Agent 交互以创建对话。关键创新在于使用待调整的 LLM,记为 M,作为复杂度评估器。评估器通过计算损失 HM(x,y) 来测量数据样本 (x,y) 的难度,定义为给定输入 x 的目标序列 y 的负对数似然:
HmathcalM(x,y)=−frac1nysumi=1nylogp(ti∣x,t1,ldots,ti−1),,其中 x 是输入查询,y=[t1,ldots,tny] 是响应,p 是模型的 token 预测概率。较高的损失表示较高的复杂度。如图所示,该损失与候选 API 的数量、使用的 API 数量以及用户查询与 API 描述之间的不相似性呈正相关。评估器使用小型先验数据集为模型建立合适的复杂度范围,其中正确生成数据的损失作为下界,持续困难数据的损失作为上界。此信息随后用作多 Agent 生成器的指导,以生成最佳难度的数据。
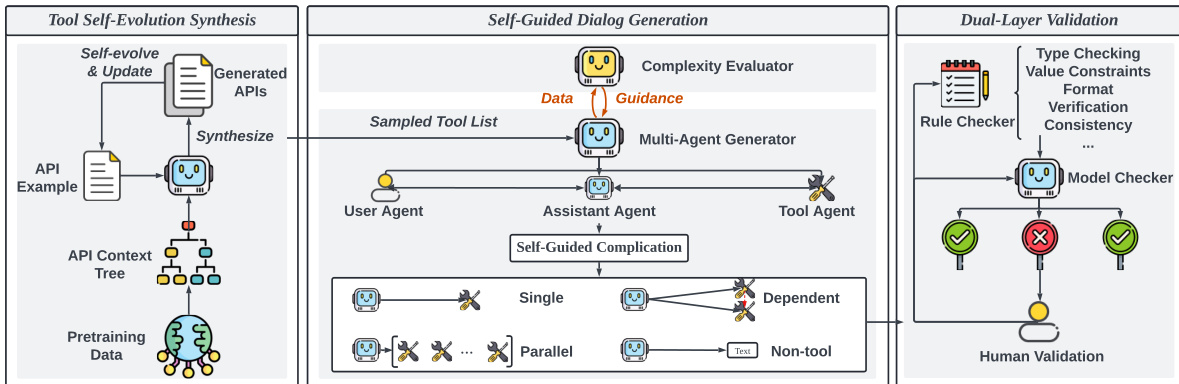
在生成对话数据后,双层验证 (DLV) 模块确保合成数据的准确性和可靠性。该系统在两层上运行。第一层是规则验证层,它采用规则检查器来强制执行与 API 定义的严格语法和结构合规性。它验证四个关键方面:API 定义清晰度、函数调用可执行性(使用正则表达式检查 API 名称、必需参数和参数格式)、对话正确性和数据样本一致性。第二层是模型验证层,它使用 LLM 驱动的专家 Agent 来评估内容质量。该层将验证任务分解为专注于幻觉检测、一致性验证和工具响应检查的子查询。每个子任务由专用 Agent 处理,结果在汇总后由人类专家监督以进行最终验证。这种双层方法确保训练数据在语法上正确且在语义上有意义。
实验
该研究通过在合成数据上微调 LLaMA3.1-8B-Instruct 和其他骨干模型来验证 ToolACE 方法,在 BFCL 和 API-Bank 基准测试上与最先进的基于 API 和开源模型进行比较性能。消融研究表明,双层验证、中等数据复杂度和高 API 多样性对于最大化函数调用准确性和减轻幻觉至关重要。结果表明,ToolACE 显著增强了各种模型大小和骨干模型的函数调用能力,且未损害一般能力,优于替代训练数据集和上下文学习方法。
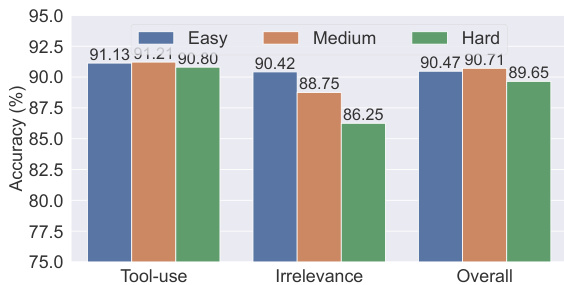
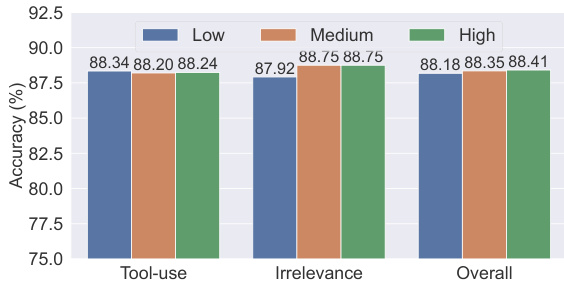
该图表比较了不同复杂度级别下工具使用、不相关性和整体性能的模型准确率。结果显示,中等复杂度数据在工具使用和整体类别中产生最高准确率,而简单复杂度在不相关性检测中表现最佳,表明模型训练的数据复杂度存在最佳平衡。中等复杂度数据在工具使用和整体性能中达到最高准确率。简单复杂度数据在不相关性检测中表现最佳。准确率在不同复杂度级别之间变化显著,中等复杂度对大多数任务最优。
该表列出了使用 LoRA 训练 LLM 的超参数。这些设置包括 10^-4 的学习率、余弦学习率调度器、48 的批量大小、三个轮次,以及秩为 16 且 alpha 为 32 的 LoRA 参数。训练使用余弦学习率调度器和 48 的批量大小。LoRA 采用秩为 16 且 alpha 为 32 的配置。模型训练三个轮次,学习率为 10^-4。

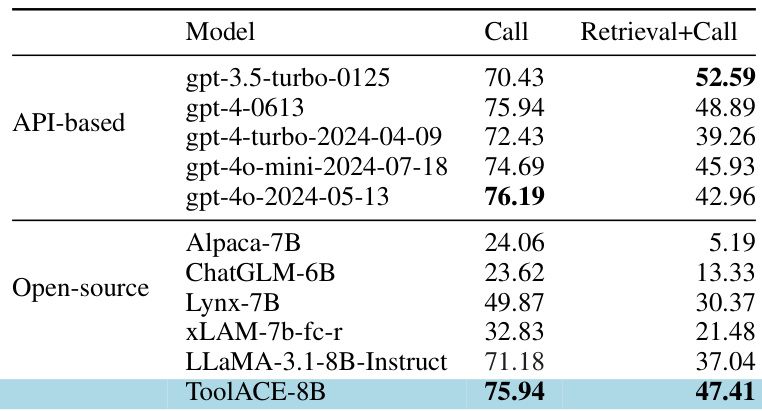
作者比较了各种模型在 BFCL 基准测试上的性能,重点关注它们进行正确函数调用和检索相关信息的能力。结果显示,ToolACE-8B 模型在调用和检索 + 调用类别中均实现了高准确率,优于大多数开源模型,并展现出与基于 API 模型竞争的性能。ToolACE-8B 在调用和检索 + 调用类别中均实现了高准确率,超过了大多数开源模型。该模型在与基于 API 模型的竞争中表现具有竞争力,特别是在调用类别中。ToolACE-8B 在两个类别中均显著优于其他开源模型,如 xLAM-7b-fc-r 和 LLaMA-3.1-8B-Instruct。
该图表显示了在不同复杂度级别数据上训练的模型性能,结果展示了工具使用、不相关性和整体准确率。在中等复杂度数据上训练的模型在所有类别中均实现了最高准确率,表明最佳复杂度增强了功能调用性能。在中等复杂度数据上训练的模型在所有类别中均实现了最高准确率。与中等复杂度相比,低和高复杂度数据的准确率较低。整体性能趋势显示,随着数据复杂度增加到中等水平,性能略有提升。
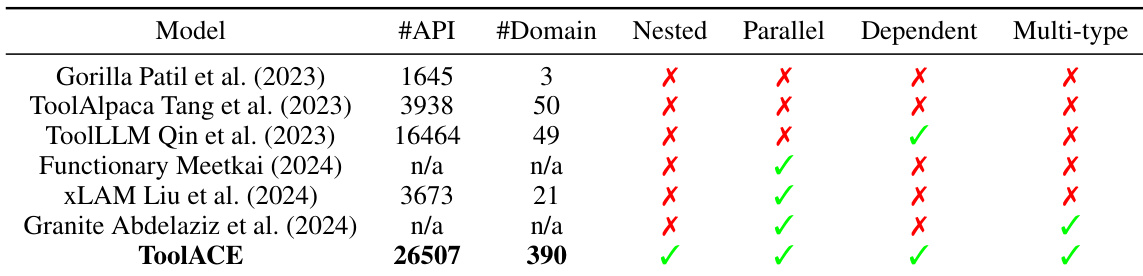
该表比较了各种数据集的 API 数量、领域多样性以及是否包含不同类型的数据,如嵌套、并行、依赖和多类型样本。ToolACE 以最高数量的 API 和领域脱颖而出,并且包含所有数据类型,表明这是一个全面且多样化的数据集。与其他数据集相比,ToolACE 拥有最高数量的 API 和领域。ToolACE 包含所有数据类型,而其他数据集缺少一种或多种类型。ToolACE 中包含多样化的数据类型表明这是一个更全面的训练数据集。
评估利用 LoRA 训练在一个具有 API 数量多和领域多样性高的综合数据集上,以评估模型在 BFCL 基准测试上的能力。结果表明,ToolACE-8B 模型在函数调用和检索任务中超越了大多数开源竞争对手,同时在与基于 API 模型的竞争中保持竞争力。此外,改变数据复杂度的实验表明,中等复杂度训练数据优化了工具使用和整体准确率,而简单复杂度更好地支持不相关性检测。