Command Palette
Search for a command to run...
文本数据集成
文本数据集成
Md Ataur Rahman Dimitris Sacharidis Oscar Romero Sergi Nadal
摘要
数据形式多样。从表层视角来看,数据可分为结构化(例如关系型数据、键值对)和非结构化(例如文本、图像)格式。迄今为止,机器在处理遵循精确模式(schema)的结构化数据方面已表现出较强的能力。然而,数据的异质性给多样化数据的有意义存储与处理带来了显著挑战。数据集成作为数据工程流水线(pipeline)中的关键环节,通过整合分散的数据源,为终端用户提供统一的数据访问能力。目前,大多数数据集成系统主要侧重于结构化数据源的融合。然而,非结构化数据(亦称自由文本)同样蕴含大量待挖掘的知识。因此,本章首先论证文本数据集成的必要性,随后系统阐述其面临的技术挑战、研究现状以及亟待解决的开放性问题。
一句话总结
作者提出了一个综合框架,利用知识图谱和大语言模型(LLMs)将文本数据与结构化数据源进行集成,以克服异构性挑战,从而在多样化的企业场景中实现数据发现、缓解数据稀疏性以及数据增强。
主要贡献
- 本章论证了将文本数据与结构化数据源集成的必要性,以解决数据异构性问题,并利用知识图谱作为统一表示模型,捕捉语义关系和上下文信息。
- 该工作概述了这种集成方法的三大具体优势,通过具体的激励性示例展示了文本数据如何缓解数据稀疏性、实现数据发现,并通过数据增强提升集成效果。
- 文中指出,需要一种可扩展且自动化的框架,结合自然语言处理、机器学习和语义网技术,以克服当前依赖人工从文本中提取结构化信息的系统的局限性。
引言
数据集成对于统一不同来源至关重要,但传统系统难以纳入蕴含关键上下文知识的海量非结构化文本。先前的方法通常依赖固定模式或需要大量人工标注,使其难以应对现实世界文本数据的语义歧义、异构性和动态特性。作者通过倡导一种利用知识图谱和先进自然语言处理技术(包括 LLM 和 RAG)的框架来解决这些差距,以自动对文本进行概念化并丰富结构化数据集。该方法旨在缓解数据稀疏性,发现隐含关系,并支持可扩展的模式演进,而无需为每个新的集成场景重新训练模型所带来的高昂资源成本。
数据集
- 该数据集将离散的结构化医疗记录与非结构化临床文本进行集成,以弥合模式差距并发现新关系。
- 结构化数据源包括包含诊断和手术的疾病数据集、跟踪不良事件和药物的并发症数据集、包含人口统计信息的患者表,以及列出处方的药物表。
- 非结构化数据由临床书籍摘录和患者笔记组成,为链接解剖结构、器官和特定医疗状况等实体提供上下文。
- 作者利用文本数据进行数据增强,通过提取推断出的概念和连接路径,例如通过解剖实体将疾病与并发症连接起来。
- 处理过程涉及识别文本中的关系以创建新的关联表,例如将患者与药物链接的处方表,即使它们没有共享的主键。
- 这种方法实现了模式演进和实例丰富,使系统能够适应以前未知的信息,并为复杂查询生成统一视图。
方法
作者提出了一个综合的文本数据集成框架,将本体学习(OL)定位为将非结构化文本转换为结构化知识图谱(KGs)的核心机制。如中央框架图所示,该方法集成了各种自然语言处理组件,包括信息抽取、语言模型和数据集成,以促进稳健的推理和数据管理。
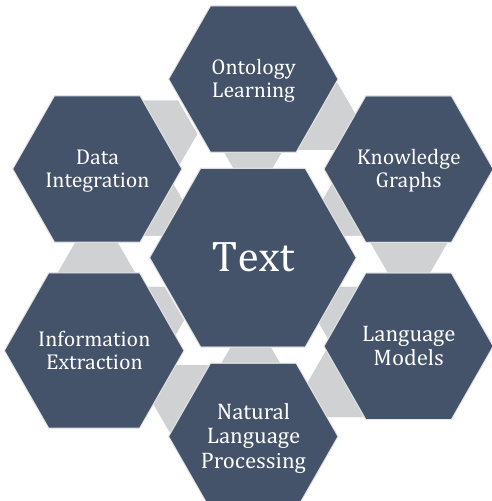
本体的构建遵循从基本语言单位到复杂逻辑规则的层次化进程。请参阅层次结构图,该图概述了这些层级:从术语和同义词开始,进阶到概念和概念层次结构,然后是关系,最终形成概念与关系表示及公理。
初始阶段涉及概念提取,即利用命名实体识别(NER)、共指消解或句法解析等技术从文本中识别实体。较新的实践利用基于 Transformer 架构的神经语言模型(LM),如 BERT 或 T5,以监督方式提取概念。随后,利用词汇句法模式或分布语义将这些概念组织成分类关系(上下位关系)。
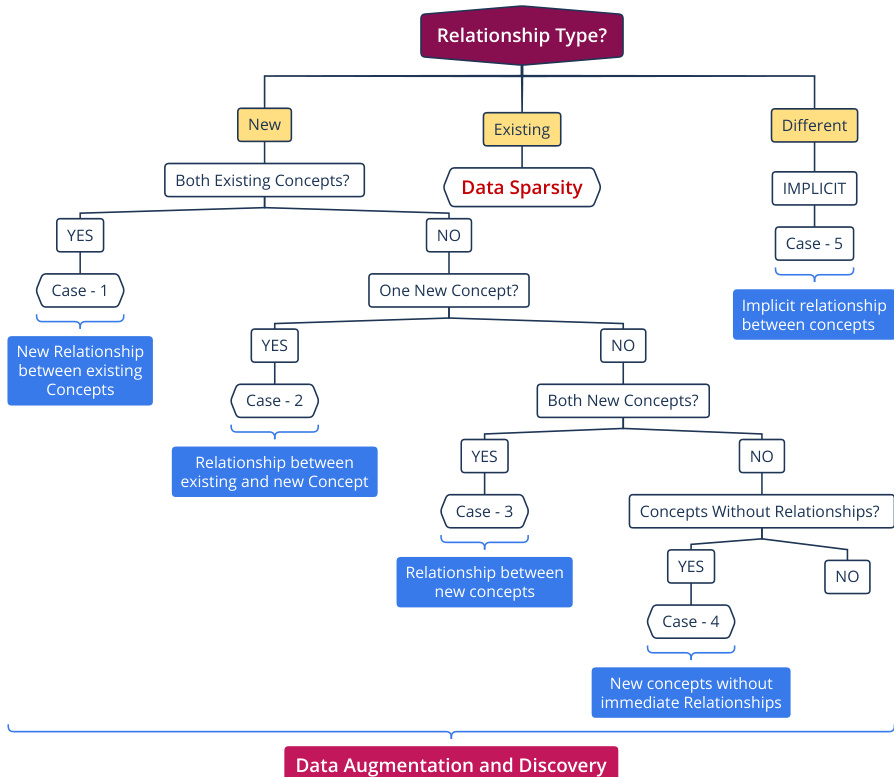
在概念识别之后,该方法专注于提取非分类关系,如属性、主题角色、整体 - 部分关系和因果关系。系统根据底层概念的状态(现有概念与新概念)对关系类型进行分类,以处理数据稀疏性并促进发现。关系类型的决策过程在流程图中详细说明,该图分支为现有概念之间的新关系、涉及新概念的关系以及隐含关系等情形。
为了表示这些数据,作者主张将信息建模为具有动态模式的知识图谱,利用 RDF、RDFS 和 OWL 等表示语言。这提供了简单数据图所缺乏的高级抽象和推理能力。最终的数据模型将结构化数据集与从文本中推导出的推断数据集成,通过 surgery_for 或 affects 等定义的关系链接疾病、手术和解剖结构等实体。
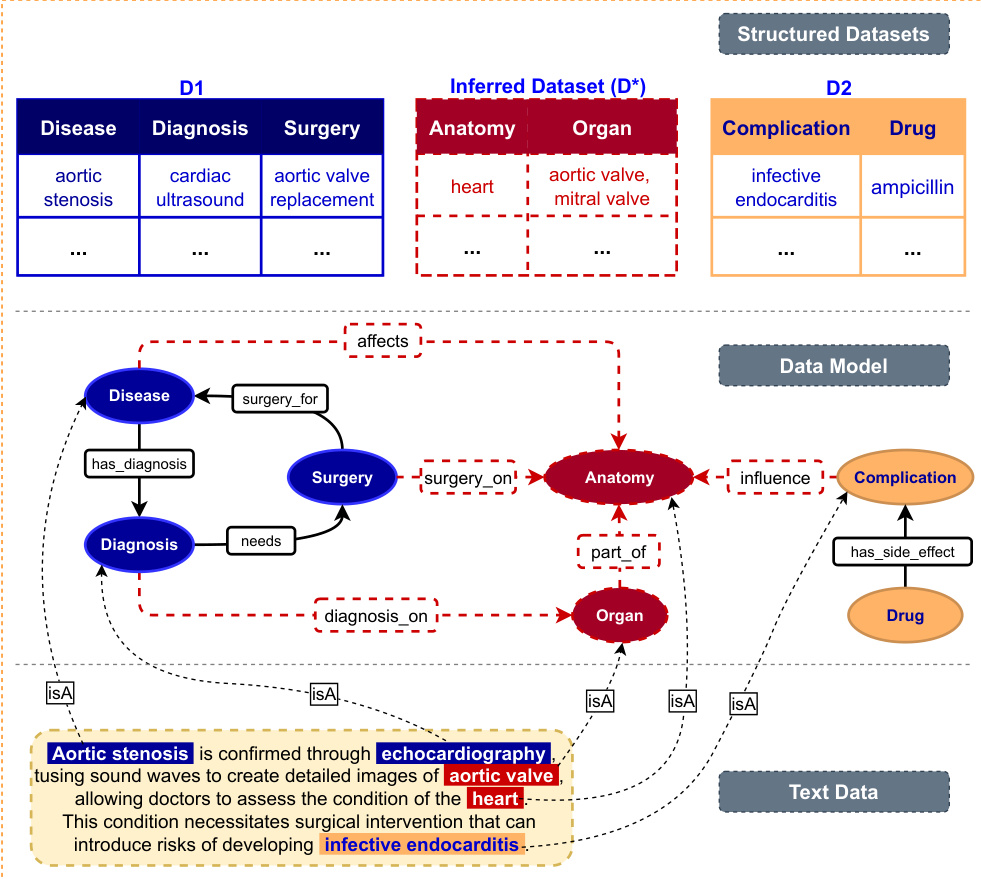
该过程最后以公理的定义结束,公理是规范概念与关系之间交互的规则和约束。这些公理通常用一阶逻辑或描述逻辑表达,为本体增加了表达能力,对于领域内的自动推理和知识发现至关重要。