Command Palette
Search for a command to run...
基于流匹配的无数字统一文本到动作生成
基于流匹配的无数字统一文本到动作生成
Guanhe Huang Oya Celiktutan
摘要
生成式模型在固定数量智能体的运动合成方面表现优异,但在处理可变数量智能体时泛化能力不足。现有方法通常基于有限的领域特定数据,采用自回归模型递归生成运动,存在效率低下和误差累积的问题。为此,我们提出统一运动流(Unified Motion Flow, UMF),该框架包含金字塔运动流(Pyramid Motion Flow, P-Flow)和半噪声运动流(Semi-Noise Motion Flow, S-Flow)。UMF 将无数量约束的运动生成解耦为单通道的运动先验生成阶段与多通道的反应生成阶段。具体而言,UMF 利用统一的潜在空间(latent space)弥合异构运动数据集之间的分布差异,从而实现高效统一训练。在运动先验生成方面,P-Flow 在不同噪声水平条件下于分层分辨率上运行,有效降低了计算开销。在反应生成方面,S-Flow 学习联合概率路径,自适应地执行反应变换与上下文重构,显著缓解了误差累积问题。大量实验结果与用户研究证实,UMF 作为面向文本驱动的多人员运动生成的通用模型具有显著有效性。项目主页:https://githubhgh.github.io/umf/。
一句话总结
来自伦敦国王学院的研究人员提出了统一运动流(Unified Motion Flow, UMF),这是一种用于多人运动生成的通用模型,它用单阶段先验和多阶段反应机制取代了低效的自回归方法。通过利用统一的潜在空间和分层噪声条件,该模型有效处理了可变代理数量,同时减轻了误差累积。
主要贡献
- 本文介绍了统一运动流(UMF),这是一个利用统一潜在空间来弥合异构运动数据集之间分布差距的框架,实现了无需指定人数的文本到运动生成的有效统一训练。
- 提出了金字塔运动流(Pyramid Motion Flow)模块,该模块根据噪声水平在分层分辨率上生成运动先验,通过在单个 Transformer 中处理不同分辨率,降低了计算开销。
- 该方法结合了半噪声运动流(Semi-Noise Motion Flow)组件,该组件学习联合概率路径以自适应地执行反应变换和上下文重建,从而减轻了多阶段反应生成中的误差累积。
引言
文本条件的人体运动合成对于虚拟现实和动画等应用至关重要,但现有方法通常在可扩展性和灵活性方面存在困难。先前的方法通常专注于单代理或双代理场景,而能够处理可变数量演员的统一模型在自回归生成过程中经常面临效率低下和误差累积的问题。为了解决这些挑战,作者提出了一种基于流匹配的统一无人数文本到运动生成框架,该框架消除了对显式代理计数的需求,并避免了以往多人系统中存在的误差传播问题。
数据集
- 作者利用两个主要数据集来评估文本条件运动生成:InterHuman(包含 7,779 个交互序列)和 HumanML3D(包含 14,616 个独立序列)。
- 两个数据集中的每个序列都配有三条文本注释,而 InterHuman-AS 子集则在标准 InterHuman 数据的基础上增加了特定的演员 - 反应者顺序注释。
- 本文严格将这些数据集用于评估而非训练,使用弗勒歇 inception 距离(FID)、R 精度、多模态距离(MM Dist)、多样性(Diversity)和多模态性(Multimodality)分数等既定指标来评估保真度和多样性。
- 模型训练采用 AdamW 优化器,初始学习率为 10−4,并配合余弦衰减调度;VAE 阶段使用 128 的 mini-batch 大小,流匹配阶段使用 64。
- 训练过程包括 6K 个 epoch 的 VAE 阶段,随后是 P-Flow 和 S-Flow 阶段各 2K 个 epoch,除现有注释外,未提及具体的裁剪策略或元数据构建细节。
方法
作者提出了统一运动流(UMF),这是一个专为无人数文本到运动生成设计的通用框架。与局限于固定代理数量的标准方法或容易遭受误差累积的自回归方法不同,UMF 利用异构运动先验作为反应流路径的自适应起点。这种设计减轻了误差累积,并允许在异构数据集上进行有效的统一训练。请参阅框架图,以直观比较朴素方法、固有先验方法和所提出的 UMF 架构。
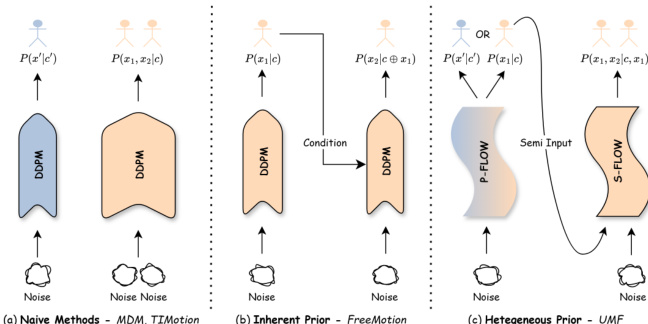
为了弥合异构运动数据集之间的分布差距,UMF 建立了一个统一的潜在空间。如下图所示,该框架包含三个主要阶段。第一阶段涉及一个单一的运动分词器,它将来自异构数据集的原始运动编码为正则化的多 token 潜在表示。这种基于 VAE 的编码器 - 解码器利用潜在适配器将内部 token 表示与最终潜在维度解耦。VAE 的训练损失定义为:
LVAE=Lgeometric+Lreconstruction+λKLLKL.这种正则化的潜在空间稳定了在异构单代理和多代理数据集上的流匹配训练。
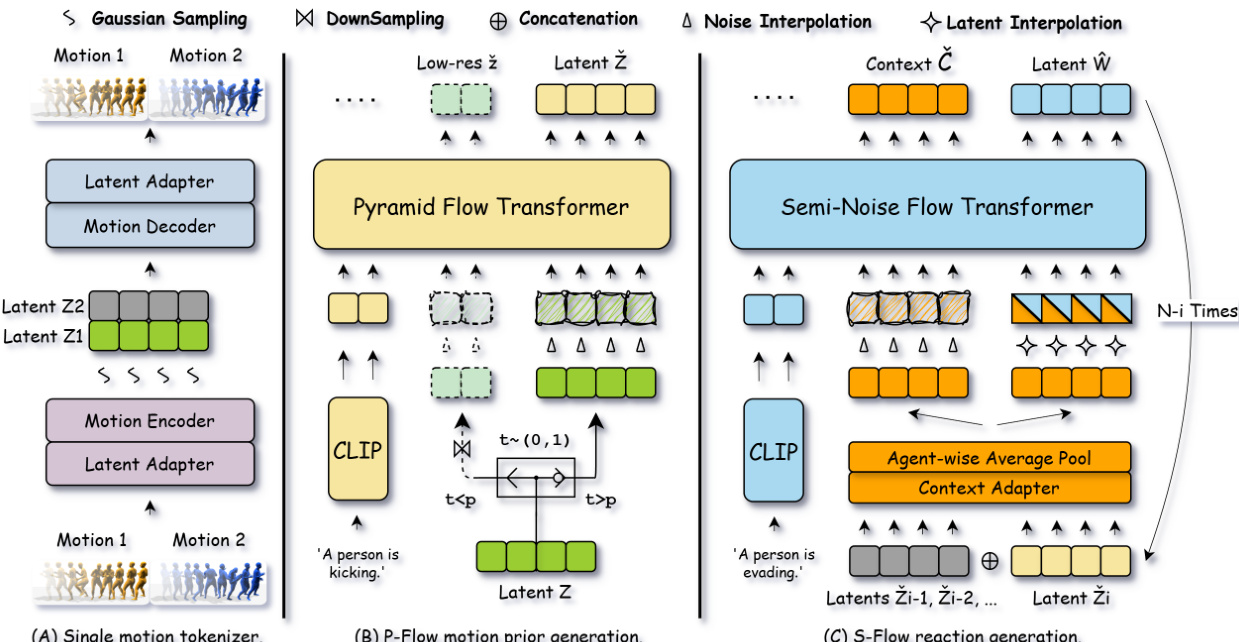
为了高效地进行个体运动合成,作者引入了金字塔运动流(P-Flow)。该模块在基于噪声水平的分层分辨率上运行,以减轻计算开销。P-Flow 根据时间步将运动先验生成分解为连续的分层阶段。它在早期时间步处理下采样的低分辨率潜在变量,并在单个 Transformer 模型的后期阶段切换到原始分辨率潜在变量。该模型被训练以在条件向量场上回归流模型 GθP,其目标如下:
LP−Flow=Ek,t,z^ek,z^skGθP(z^t;t,c)−(z^ek−z^sk)2.对于反应和交互合成,该框架采用半噪声运动流(S-Flow)。S-Flow 通过平衡反应变换和上下文重建来学习联合概率路径。S-Flow 不使用生成的运动作为静态条件,而是将其整合以定义上下文分布。该源分布初始化反应生成路径,使模型能够专注于学习运动分布之间的动态变换,同时从噪声分布中重建上下文作为正则化项。S-Flow 的训练目标是反应变换损失和上下文重建损失的加权和:
LS−Flow=Ltrans+λreconLrecon.这种联合训练在反应预测和上下文感知之间取得了平衡,使模型在自回归生成过程中不易产生误差累积。
实验
- 在 InterHuman 和 InterHuman-AS 基准上的定量评估表明,该方法在文本遵循度、运动保真度和多样性方面显著优于通用和专用基线,验证了其生成逼真多代理交互的卓越能力。
- 定性比较和用户研究证实,该模型能够产生连贯的物理交互并在复杂场景中正确定位代理,包括在基线方法失败的变量组大小情况下的零样本生成。
- 消融研究验证了利用来自单代理数据集的异构先验可以增强多代理性能,而所提出的潜在适配器和多 token 设计对于有效的无人数生成至关重要。
- 效率分析显示,与基线相比,金字塔流结构显著降低了计算成本和推理时间,其中非对称步长分配被确定为平衡速度与质量的最佳策略。
- 组件分析证实,半噪声流设计、上下文适配器和重建损失对于防止误差累积和保持高生成保真度至关重要。