Command Palette
Search for a command to run...
Calibri:通过参数高效校准增强 Diffusion Transformer
Calibri:通过参数高效校准增强 Diffusion Transformer
Danil Tokhchukov Aysel Mirzoeva Andrey Kuznetsov Konstantin Sobolev
摘要
本文揭示了 Diffusion Transformers (DiTs) 在生成式任务中提升性能的潜在能力。通过对去噪过程的深入分析,我们证明引入单个可学习缩放参数即可显著提升 DiT 模块的性能。基于这一发现,我们提出了 Calibri,一种参数高效的校准方法,通过优化 DiT 组件以提升生成质量。Calibri 将 DiT 校准建模为黑盒奖励优化问题,并采用进化算法高效求解,仅修改约 100 个参数。实验结果表明,尽管 Calibri 设计轻量,但在多种文本到图像模型中均能持续提升性能。值得注意的是,Calibri 在保持高质量输出的同时,还显著减少了图像生成所需的推理步骤。
一句话总结
来自密歇根州立大学(MSU)和 FusionBrain Lab 的作者介绍了 Calibri,这是一种参数高效的方法,通过仅优化约一百个参数来对齐扩散 Transformer(Diffusion Transformers)。与需要大量微调的先前方法不同,Calibri 在保持计算效率的同时,显著提升了详细图像合成的生成质量。
主要贡献
- 本文介绍了 Calibri,这是一种参数高效的方法,将扩散 Transformer 的校准问题构建为通过进化算法求解的黑盒奖励优化问题,仅调整约 100 个缩放参数。
- 这项工作表明,将学习到的标量权重应用于各个 DiT 块输出,可显著提升生成质量,并减少图像合成所需的推理步数。
- 实验结果验证了 Calibri Ensemble 方法(集成多个校准模型)在各种文生图基线模型上 consistently 提升了性能,且未引入额外的计算开销。
引言
现代视觉生成已转向结合流匹配(flow matching)的扩散 Transformer(DiT),为从文生图合成到视频生成等任务确立了新标准。然而,近期分析显示,这些模型在其均匀块中存在次优的权重分配问题,其中某些层会引入伪影,而其他层对最终输出的贡献则不均匀。作者利用这一洞察提出了 Calibri,这是一种参数高效的方法,将块校准构建为通过进化算法求解的黑盒奖励优化问题。通过仅调整约 100 个缩放参数,Calibri 显著提升了生成质量并减少了所需的推理步数,同时避免了全量微调带来的计算开销。
方法
扩散 Transformer(DiT)架构由一系列 DiT 块组成,这些块将输入令牌转换为输出令牌。标准 DiT 块包含多头自注意力(MHSA)层和前馈层。这两层都对输入数据应用层归一化(LayerNorm),并由时间嵌入进行调制。这种调制是通过向量 α,β,γ 实现的,这些向量由一个独立的多层感知机(MLP)生成。对于多模态处理,作者使用了多模态扩散 Transformer(MM-DiT)。该块在标准结构的基础上,通过拼接组合文本和视觉令牌并并行处理它们。模态间通信仅限于多模态注意力层(MultiModal Attention Layer),从而实现两种模态之间的有效交互。每种模态采用独立的调制向量,视觉令牌记为 αv,βv,γv,文本令牌记为 αt,βt,γt。如下图所示,块结构图展示了标准 DiT 与 MM-DiT 架构之间的结构差异。
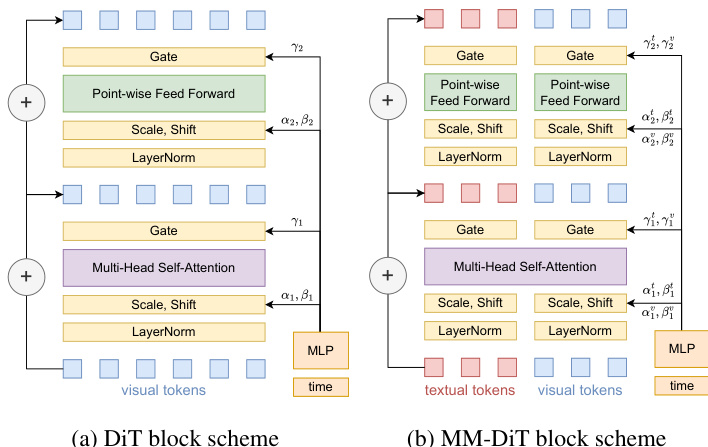
标准 DiT 层的输出可以用以下公式描述:
xl=xl−1+γ1MHSA(α1LN(xl−1)+β1),xl+1=xl+γ2FF(α2LN(xl)+β2),其中 xl−1 表示输入令牌序列,xl 和 xl+1 分别表示中间输出和最终输出。MM-DiT 块的前向传播表示为:
xlv=xl−1v+γ1vMHSA(α1vLN(xl−1)+β1v),xlt=xl−1t+γ1tMHSA(α1tLN(xl−1)+β1t),xl+1v=xlv+γ2vFF(α2LN(xlv)+β2v),xl+1t=xlt+γ2tFF(α2LN(xlv)+β2t),其中 xlv 和 xlt 分别对应于视觉和文本模态的转换后令牌。
为了增强这些 Transformer 的生成能力,作者引入了 Calibri,这是一种旨在校准模型最小子集参数的方法。校准过程被构建为一个优化问题,其目标是找到最优参数配置 c∗ 以最大化奖励函数:
c∗=argcmaxR(c),其中 R(∗) 是一个标量值函数,用于衡量扩散 Transformer 在给定任务上的性能。校准模型的搜索空间由扩散 Transformer 中应用调整的具体位置决定。作者为内部层校准参数引入了三个粒度级别:块缩放(Block Scaling),均匀调整注意力和 MLP 层的输出;层缩放(Layer Scaling),调整块内的各个层;以及门控缩放(Gate Scaling),这对于具有多模态交互(如 MM-DiT)的架构尤为重要。
为了确定最优校准系数,该方法采用了协方差矩阵自适应进化策略(CMA-ES),这是一种强大的无梯度优化方法。CMA-ES 通过基于多元高斯分布 N(μ,σ2C) 迭代细化采样分布来优化目标函数。方法示意图如下所示。
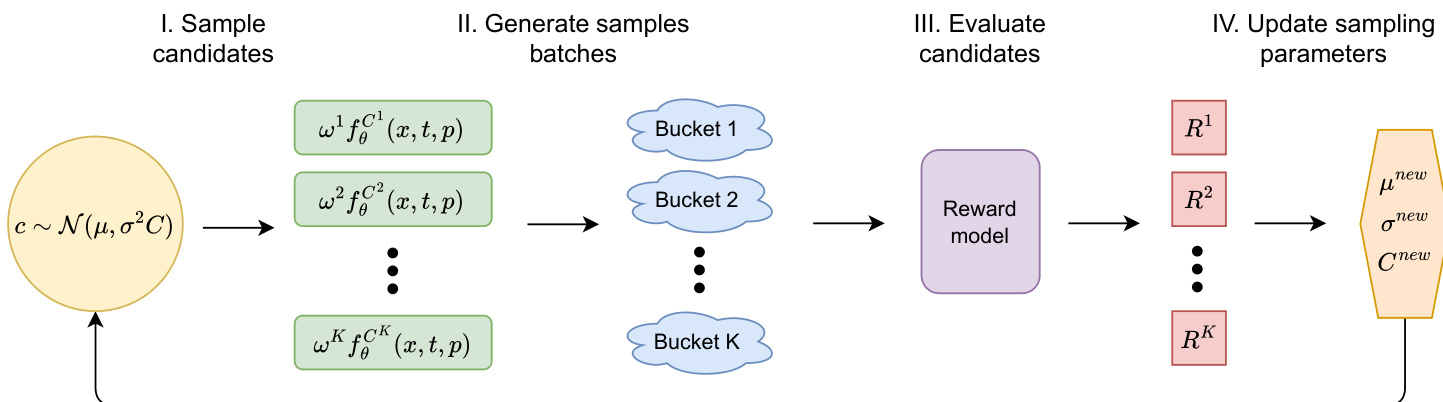
在每次迭代中,候选解从该高斯分布中抽取,并使用目标函数进行评估。该过程包括采样候选解、生成样本批次、通过奖励模型评估候选解,最后更新采样参数。CMA-ES 通过向表现更好的候选解移动来更新均值向量,同时调整协方差矩阵以反映搜索空间中的成功方向。这种迭代细化允许高效的探索和利用,从而在连续的迭代中优化校准系数以提升模型性能。
实验
- 动机实验表明,DiT 块的贡献是不均匀的,移除特定层可能会意外地提高图像质量,从而发现对各个块应用最优缩放因子可以提升整体模型性能。
- 设计决策研究表明,与块缩放或门控缩放相比,层缩放在多个奖励函数上提供了最一致的提升,而 Calibri Ensemble 有效地聚合了校准模型,从而提高了奖励,并将最优推理步数从 30–50 步减少到 10–15 步。
- 在不同骨干网络上的评估证实,Calibri consistently 提升了生成质量和文本对齐度,同时显著减少了推理步数;人类评估验证了这些提升是真实的感知改进,而非奖励伪影。
- 集成测试显示,Calibri 可以与现有的对齐方法(如 Flow-GRPO)结合,以进一步提升各种目标上的性能,在更新极少参数的情况下实现了与大规模微调相当的结果。
- 多样性分析表明,尽管使用了更少的推理步数,Calibri 仍保持了与基线模型相当的生成多样性,而其他优化方法往往在无法提供速度优势的情况下降低了多样性。
- 对比研究确立,CMA-ES 在优化校准系数方面比基于梯度的方法(如 Flow-GRPO)效率显著更高,其训练动态显示出清晰的收敛性,允许提前终止以节省计算资源。