Command Palette
Search for a command to run...
Voxtral TTS
Voxtral TTS
摘要
我们推出 Voxtral TTS,这是一款支持多语言、具有高表现力的文本转语音(TTS)模型,仅需 3 秒参考音频即可生成自然语音。Voxtral TTS 采用混合架构,将语义语音 token 的自回归生成与声学 token 的流匹配(flow-matching)相结合。这些 token 通过 Voxtral Codec 进行编码与解码;该语音 tokenizer 从头训练,并采用混合 VQ-FSQ 量化方案。由母语人士参与的人为评估显示,得益于其自然度与表现力,Voxtral TTS 在多语言语音克隆任务中更受青睐,相比 ElevenLabs Flash v2.5 的胜率高达 68.4%。模型权重已在 CC BY-NC 许可下开源发布。
一句话总结
Mistral AI 推出了 Voxtral TTS,这是一款多语言文本转语音模型,采用混合架构,将自回归语义令牌生成与流匹配(flow-matching)声学令牌生成相结合。该方法能够仅凭极少量的音频参考实现高保真语音克隆,在自然度和表现力方面的人类评估中超越了 ElevenLabs Flash v2.5。
主要贡献
- 本文介绍了 Voxtral TTS,这是一款多语言零样本文本转语音模型,利用混合架构,将用于语义令牌的自回归生成与用于声学令牌的流匹配相结合,以平衡长程一致性与丰富的声学细节。
- 提出了一种名为 Voxtral Codec 的新型语音分词器,该分词器从头开始训练,采用混合 VQ-FSQ 量化方案,将参考音频编码为低比特率的语义和声学令牌流。
- 人类评估表明,该模型在多语言语音克隆任务中取得了 68.4% 的胜率,优于 ElevenLabs Flash v2.5;同时,作者已在 CC BY-NC 许可下发布了模型权重。
引言
自然且富有表现力的文本转语音对于虚拟助手和辅助工具等应用至关重要,然而在零样本设置下捕捉人类语音的细微差别仍然困难。先前的系统通常依赖深度自回归声学生成,尽管使用了因子化的语音表示,但这仍可能限制效率并削弱声学细节的丰富性。作者推出了 Voxtral TTS,这是一款多语言零样本系统,结合了用于语义令牌的自回归 Transformer 和用于声学令牌的轻量级流匹配模型,以同时提升一致性和细节。此外,作者还将直接偏好优化(Direct Preference Optimization)适配到这种混合离散 - 连续设置中,在支持低延迟流式传输的同时,实现了优于领先专有模型的说话人相似度和自然度。
方法
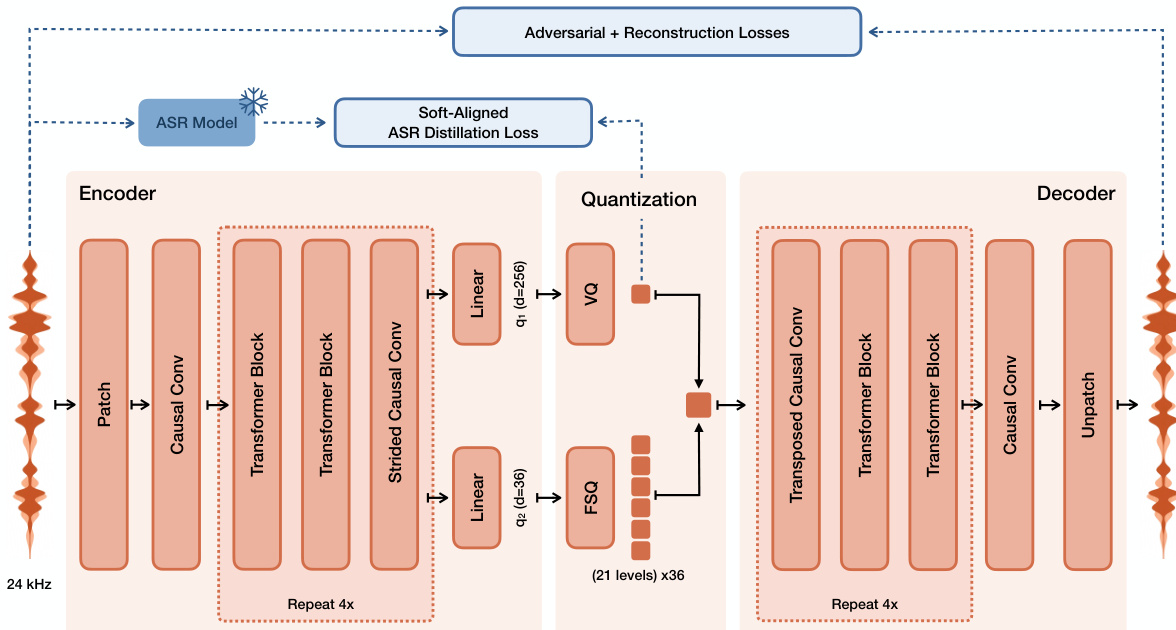
作者推出了 Voxtral TTS,其依赖一种名为 Voxtral Codec 的新型语音分词器,将音频离散化为语义和声学令牌。Codec 架构如下图所示。它通过卷积 - Transformer 编码器处理 24 kHz 单声道波形,将输入块投影为嵌入向量。这些嵌入向量经过多个包含因果自注意力和因果 CNN 层的模块进行下采样。生成的潜在表示被拆分为 256 维的语义分量和 36 维的声学分量,并分别进行量化。语义分量使用大小为 8192 的码本的向量量化(VQ),而声学分量则使用具有 21 个均匀层级的有限标量量化(FSQ)。这种混合方案实现了约 2.14 kbps 的低比特率。解码器镜像编码器结构,从这些离散令牌重建波形。
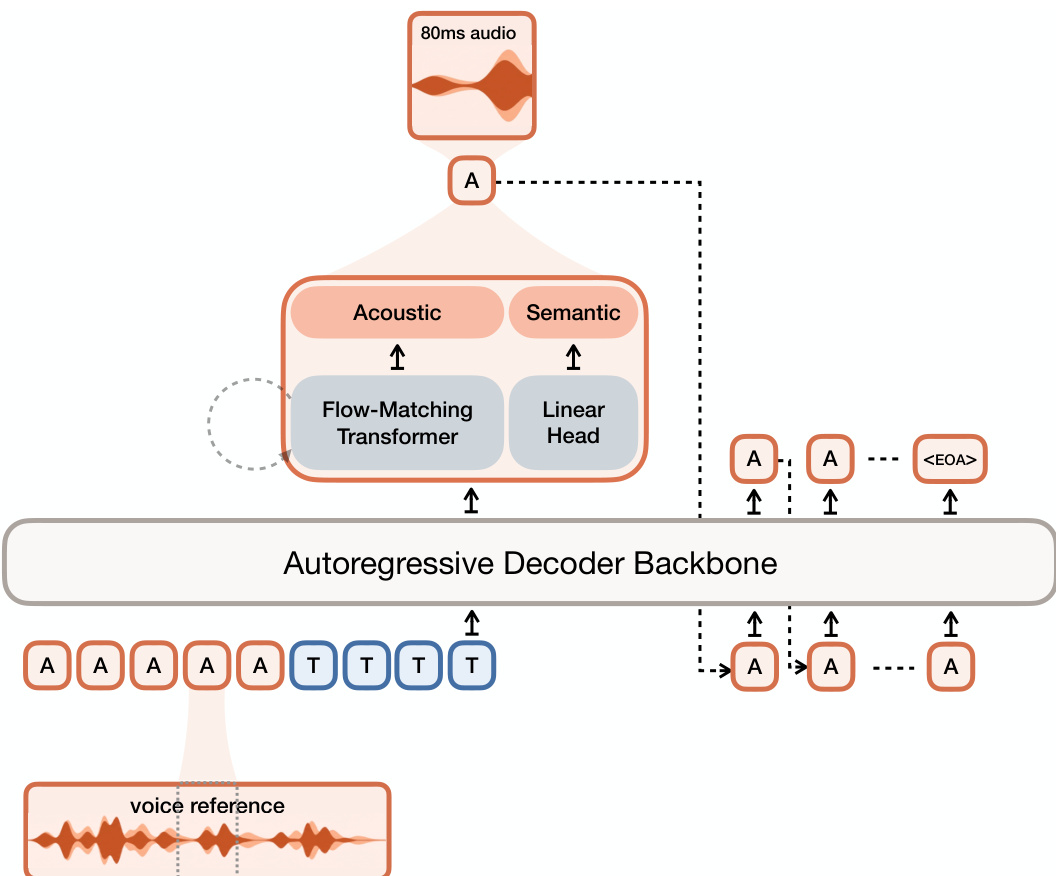
在生成过程中,作者利用结合自回归建模与流匹配的混合架构。整体系统布局请参阅框架图。输入包括语音参考音频令牌和文本令牌,它们被送入基于 Ministral 3B 的自回归解码器主干网络。该主干网络自回归地生成语义令牌序列。在每个时间步,来自主干网络的隐藏状态被传递给流匹配 Transformer,以预测相应的声学令牌。流匹配 Transformer 对速度场进行建模,该速度场在一系列函数评估步骤中将高斯噪声传输到声学嵌入空间。语义令牌通过线性头进行预测,该线性头将隐藏状态投影到语义词汇上的 logits。最后,生成的语义和声学令牌由 Voxtral Codec 解码器解码为最终波形。
训练过程涉及优化 Codec,结合使用重建损失、对抗损失以及辅助的 ASR 蒸馏损失,以使语义令牌与文本内容对齐。TTS 模型使用两部分损失函数进行训练,包括语义令牌的交叉熵损失和声学令牌的流匹配损失。流匹配目标旨在最小化预测的速度场与从数据分布和高斯噪声导出的条件速度目标之间的差异。
实验
- Voxtral Codec 在所有客观指标上均优于 Mimi,在配置相似比特率时,其主观语音质量与之相当或更优。
- 自动评估显示,Voxtral TTS 在说话人相似度方面显著超越 ElevenLabs 模型,尽管 ElevenLabs Flash v2.5 在某些自动可懂度和质量评分上领先。
- 人类评估表明,虽然 UTMOS 等自动指标与人类偏好相关性较差,但 Voxtral TTS 在跨多种语言的隐式情感控制和零样本语音克隆方面始终优于竞争对手。
- 直接偏好优化(DPO)训练减少了幻觉和音量渐弱现象,同时提高了可懂度和质量,对说话人相似度的影响微乎其微。
- 将推理步数增加至 8 步并调整 CFG 参数,可在质量和情感遵循度之间取得平衡;对于高质量音频,较低的 CFG 值更受青睐,而对于野外录音,较高的 CFG 值更优。
- CUDA 图加速将延迟降低了 47%,并将实时因子提高了 2.5 倍,实现了高吞吐量服务,支持单张 GPU 上超过 30 个并发用户,且延迟低于一秒。