Command Palette
Search for a command to run...
SEAR:基于模式的 LLM 网关评估与路由
SEAR:基于模式的 LLM 网关评估与路由
Zecheng Zhang Han Zheng Yue Xu
摘要
评估生产环境中的 LLM 响应并在 LLM 网关中跨提供商路由请求,需要细粒度的质量信号以及基于实际运营状况的决策。为填补这一空白,我们提出了 SEAR——一种面向多模型、多提供商 LLM 网关的基于模式(schema)的评估与路由系统。SEAR 定义了一个可扩展的关系型模式,涵盖 LLM 评估信号(包括上下文、意图、响应特征、问题归因和质量评分)以及网关运营指标(如延迟、成本和吞吐量),并通过跨表一致性链接关联约一百个具有类型定义、支持 SQL 查询的列。为可靠地填充评估信号,SEAR 提出了自包含的信号指令、模式内推理机制以及多阶段生成流程,能够产出可直接写入数据库的结构化输出。由于信号是通过 LLM 推理而非浅层分类器生成的,SEAR 能够捕捉复杂的请求语义,提供人类可解释的路由决策依据,并在单一查询层中统一评估与路由功能。在数千次生产会话的测试中,SEAR 在人工标注数据上实现了高信号准确性,并支持实用的路由决策,包括在保持相当质量的前提下显著降低运营成本。
一句话总结
Strukto.AI 和 Infron.AI 的研究人员提出了 SEAR,这是一种基于模式的系统,用于多提供商 LLM 网关。该系统用模式内推理取代了浅层分类器,以生成结构化的评估信号,从而实现可解释的路由决策。在保持生产环境高响应质量的同时,显著降低了成本。
主要贡献
- 本文介绍了 SEAR,这是一个基于模式的系统,它将 LLM 评估信号和网关运营指标统一到一个单一的、可通过 SQL 查询的层中,该层包含约一百个类型化的列,支持灵活的质量分析和路由。
- 提出了一种可扩展的关系模式,涵盖了完整的请求生命周期,包括上下文、意图和问题归因,同时强制执行跨表一致性,从而基于每个信号的证据实现人类可解释的路由解释。
- 提出了一种模式驱动的裁判(Judge)方法,利用自包含的信号指令、模式内推理和多阶段生成,可靠地生成可直接用于数据库的结构化输出。实验验证了该方法在人工标注数据上的高准确率,以及在生产流量中显著的成本降低。
引言
随着生产环境中的 LLM 流量在多个领域扩展,团队依赖多模型网关来平衡成本和质量,但现有的评估方法难以提供智能路由所需的细粒度信号。先前的方法通常产生难以聚合的非结构化文本,将质量压缩为掩盖故障模式的单一分数,或者依赖无法捕捉复杂请求语义的浅层分类器。此外,当前的路由系统经常作为黑盒运行,仅提供建议,而缺乏在生产环境中安全部署所需的、基于信号级别的可解释说明。为了解决这些挑战,作者提出了 SEAR,这是一个基于模式的系统,将 LLM 评估和网关操作统一在单一的 SQL 可查询数据层中。作者利用 LLM 裁判生成结构化的、相互关联的关系表,其中包含约一百个类型化的信号,从而实现精确的质量诊断,以及基于明确证据的透明、具有成本效益的路由决策。
数据集
-
数据集构成与来源 作者通过从三个具有独特工作负载概况的不同组织(包括多语言、角色扮演和以翻译为主的任务)中随机采样 3,000 个会话,构建了一个生产级数据集。该数据涵盖了单轮请求和多轮代理工作流,与公共基准相比具有高度的代表性。所有会话的收集均严格遵守组织的数据使用、同意和隐私政策。
-
每个子集的关键细节
- 训练和验证池:主池包含 2,940 个会话(总数 3,000 减去预留的测试集),用于模型评估和模式开发。
- 预留测试集:预留了 300 个会话的子集(每个组织 100 个),由两名高级工程师对所有语义评估列进行人工标注,以建立真实值(Ground Truth)。
- 验证集:额外采样了 60 个会话(每个组织 20 个,不在主池内),专门用于模式开发和迭代。
-
数据使用与处理 作者利用这些数据训练和评估一个基于 LLM 的裁判系统(使用 GPT-5-mini 和 GPT-5.2),该系统填充了一个五表关系模式。
- 语义评估:四个表捕获请求上下文、模型响应、问题归因和质量严重程度。裁判处理原始会话输入以生成离散标签(布尔值、分类枚举或序数刻度),而非连续分数,以提高一致性。
- 运营指标:第五个表由服务网关直接填充,记录 100% 的流量指标,如延迟、令牌使用量和失败率,这些指标通过外键与语义评估相关联。
- 一致性检查:作者利用 SQL 查询检测跨表不一致性(例如,需要工具调用但未产生),以标记并重新裁判或过滤错误记录。
-
元数据与模式构建
- 离散标记策略:为了避免数值刻度的不稳定性,模式使用具有清晰语义边界的显式离散类型,例如“真/假”或“轻微/严重”级别。
- 跨表对齐:该设计在表之间镜像维度,以实现从请求意图到最终质量分数的可追溯性,从而允许对用户要求与模型输出之间的差距进行根本原因诊断。
- 可扩展性:该模式支持增量演进,允许通过可选的外键添加新表或列,而不会破坏现有工作流。
方法
SEAR 框架旨在提取并推理 LLM 请求会话,以生成结构化、类型化的评估记录。这些记录与网关运营指标共置于单一的 SQL 可查询数据层中。
请参阅框架图以了解整体系统架构。中央 LLM 网关位于 LLM 应用程序和提供商之间,处理请求路由、速率限制和故障转移。它将延迟和令牌计数等运营指标记录到网关指标表中。为了管理 LLM 作为裁判的评估成本,网关对可配置比例的请求进行采样。这些采样会话包含完整的对话历史和当前的 LLM 响应,并被转发给 SEAR 裁判。SEAR 裁判是一个推理 LLM,它生成结构化信号并将其插入到多个外键链接表的关系模式中。该模式包括上下文信号、用户意图、响应特征、问题归因和质量分数表。通过将评估信号与网关指标共置,下游任务(如路由和漂移检测)变成了标准的 SQL 查询。
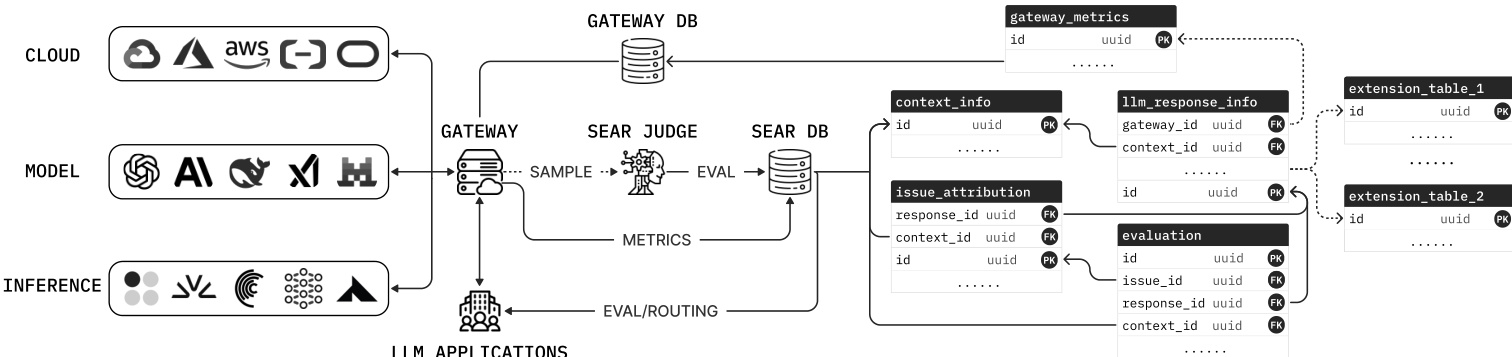
系统的核心是模式驱动裁判(Schema-Driven Judge),它必须为包含约一百个类型化列的语义评估表生成有效记录。为了解决可靠生成大型结构化输出的挑战,作者采用了自包含的信号指令。对于每个表,裁判使用类型化的 JSON 模式在一次结构化输出调用中发出所有信号,其中字段直接映射到表列。每个列描述都指定了其定义、证据范围和值分配规则,以减少列间干扰。
为了在严格的模式约束下保持推理质量,作者提出了模式内推理(in-schema reasoning)。裁判不是在单独的调用中生成自由文本的推理轨迹,而是将临时推理文本字段 r 作为 JSON 模式中的第一个属性放置。由于生成遵循模式顺序,模型会在单次自回归过程中在信号列之前发出 r。形式上,设 x 表示输入上下文,Y=(Y1,…,Yd) 表示 d 个信号列。生成推理和信号的概率建模为:
p(r,Y∣x)=p(r∣x)i=1∏dp(Yi∣Y<i,r,x).与需要分别调用推理和结构化输出的标准思维链(CoT)方法相比,这种方法不需要额外的 LLM 调用。
生成过程被编排为多个阶段,以提高稳定性并管理上下文长度。如下图所示,阶段依赖关系遵循自然的请求流。第一阶段处理上下文信息,每个后续阶段接收上下文以及所有上游结构化输出。此序列与数据库模式中的外键依赖关系一致,从上下文和用户意图移动到响应特征化,最后到问题归因和质量评分。
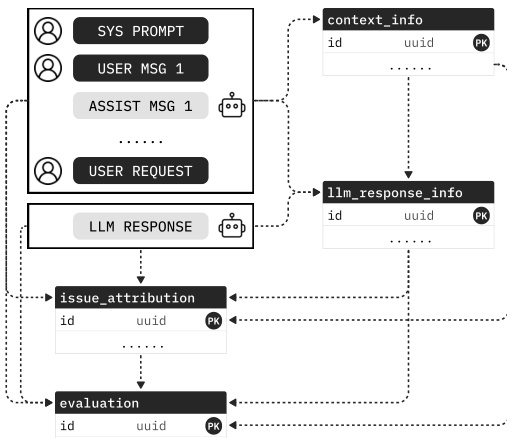
这种分解确保每次调用发出的模式更小,从而减少格式错误的字段。一旦所有阶段完成,该过程将实例化外键链接,并在一个事务中提交所有链接的记录。生成的记录支持数据驱动的路由,其中路由器查询流量切片中观察到的质量和成本,以生成模型和提供商路由策略。对于实时路由,轻量级 LLM 对传入请求的上下文级别属性进行分类,网关查找匹配的 SEAR 衍生策略。
实验
- 数据驱动的评估和路由工作流被验证为对结构化 SEAR 记录的标准 SQL 查询,无需自定义管道即可实现统一的模型、提供商和用户风险画像。
- 裁判性能实验证实,更高的推理努力始终能提高布尔值、分类和序数信号的准确率,而模式内推理提供了互补的提升。
- 跨表一致性检查被证明是一种有效的事后质量保证机制,能够过滤不一致的记录并改善指标,特别是对于较弱的裁判配置。
- 多阶段生成被验证为实际模式约束评估所必需的,因为单阶段方法经常产生格式错误的输出。
- 元任务混淆(即裁判将评估指令与用户任务混淆)被确定为一种故障模式,通过增加推理努力可以有效缓解。
- 路由实验表明,SEAR 衍生的查询可以识别成本显著更低但保持可比输出质量的替代模型。
- 实时上下文分类使用轻量级模型进行了验证,该模型以可接受的准确率提取与路由相关的信号,从而实现低延迟的每请求路由决策。