Command Palette
Search for a command to run...
Intern-S1-Pro:万亿级科学多模态基础模型
Intern-S1-Pro:万亿级科学多模态基础模型
摘要
我们正式推出 Intern-S1-Pro,这是业界首个参数量达到万亿级别的科学多模态基础模型。通过扩展至这一前所未有的规模,该模型在通用领域与科学领域均实现了全面的能力跃升。除了显著增强的推理能力与图文理解能力外,其智能体系还融入了先进的 Agent 能力。与此同时,其科学专业领域得到极大拓展,已掌握涵盖化学、材料科学、生命科学及地球科学等关键学科领域的 100 多项专业任务。实现这一超大规模模型的关键,在于 XTuner 和 LMDeploy 所提供的强大基础设施支持。该支撑体系不仅实现了万亿参数级别下的高效强化学习(Reinforcement Learning, RL)训练,还确保了训练与推理阶段之间严格的精度一致性。通过无缝整合上述技术进展,Intern-S1-Pro 进一步强化了通用智能与专业智能的融合,确立了其作为“可专业化通用智能体”(Specializable Generalist)的定位:在通用能力方面跻身开源模型的第一梯队,而在专业科学任务的深度上则超越了众多闭源专有模型。
一句话总结
上海人工智能实验室的 Intern-S1-Pro 团队推出了 Intern-S1-Pro,这是一个拥有万亿参数的科学多模态基础模型。该模型采用分组路由(Grouped Routing)和直通估计器(Straight-Through Estimators)来稳定超大规模混合专家(Mixture-of-Experts)的训练。这一方法使模型能够掌握超过 100 项专业科学任务,并在深度领域推理和通用能力方面超越专有系统。
主要贡献
- 本文介绍了 Intern-S1-Pro,这是首个万亿参数科学多模态基础模型,集成了先进的智能体(Agent)能力,并掌握了化学、材料、生命科学和地球科学等领域超过 100 项专业任务。
- 提出了一种新颖的分组路由机制和梯度估计方案,以解决超大规模混合专家架构中的训练不稳定和路由优化挑战,确保高效的负载均衡和加速专家更新。
- 该工作通过专为科学图像设计的字幕生成流程,以及基于 XTuner 和 LMDeploy 协同设计的架构,在科学基准测试中展现了最先进(SOTA)的性能。该架构支持在万亿参数规模下进行高效的强化学习训练,同时保持严格的精度一致性。
引言
大语言模型(LLM)和视觉语言模型(VLM)的快速增长,催生了对统一系统的需求,以加速化学、生物学和材料科学等跨领域的科学发现。先前的方法往往难以应对科学领域巨大的多样性,其中专业知识需求和独特的推理模式需要巨大的模型容量,而小型或单一用途的模型无法提供。此外,扩展到万亿参数级别带来了显著的工程挑战,包括由专家负载不平衡引起的训练不稳定,以及在混合专家架构中优化路由嵌入的困难。为了解决这些挑战,作者推出了 Intern-S1-Pro,这是首个万亿参数科学多模态基础模型,它利用新颖的分组路由机制和协同训练框架来确保稳定性和效率。通过将先进的智能体能力与通用及专业任务的联合训练相结合,该模型在超过 100 项科学任务中实现了最先进性能,并在专业深度上超越了专有模型。
数据集
-
数据集构成与来源:作者为 Intern-S1-Pro 构建了一个 6T token 的预训练语料库,结合了通用图像 - 文本数据和一个专门的 270B token 科学子集。这些科学数据主要源自生命科学、化学、地球科学和材料科学领域的 PDF 语料库,解决了标准网络来源中高质量、对齐的科学图像 - 文本对稀缺的问题。
-
科学子集的关键细节:
- 来源:包含高信息密度图表(如实验结果、统计图和结构图)的大规模 PDF 语料库。
- 提取:团队使用 MinerU2.5 进行布局分析,以检测和定位图表、公式和表格,并将其裁剪为标准化的子图像。
- 去重:应用感知哈希(pHash)在大规模范围内消除冗余视觉内容。
- 字幕策略:模型路由机制将科学子图像分配给 InternVL3.5-241B 以生成领域特定的描述,而非科学子图像则由 CapRL-32B 处理,该模型经过可验证奖励强化学习(RLVR)训练,用于生成密集字幕。
- 质量控制:一个 0.5B 参数的文本质量判别器用于过滤乱码文本、重复表达和低信息密度内容。
-
训练中的数据使用:作者使用完整的 6T token 混合数据继续进行预训练。该流程强调整合新生成的科学字幕,以增强模型理解和推理复杂视觉内容的能力,超越原始文献中常见的简短或不对齐的字幕。
-
处理与元数据细节:
- 提示策略:采用多模板随机化提示策略,以确保生成字幕的语言多样性。
- 对齐重点:该流程专门针对创建密集字幕,其中文本明确指代视觉元素,纠正了原始文献文本通常作为扩展而非描述这一常见问题。
- 评估背景:虽然训练数据侧重于科学和通用多模态对齐,但生成的模型在包括 SciReasoner、SFE 和 MMMU-Pro 在内的一系列基准测试中进行了评估,以测试推理和感知能力。
方法
Intern-S1-Pro 模型构建于专为科学模态设计的基础架构之上,并采用 1T 混合专家(MoE)架构。整体框架整合了三大核心支柱:科学模态基础、科学与通用数据融合,以及通过智能体强化学习实现的演进。
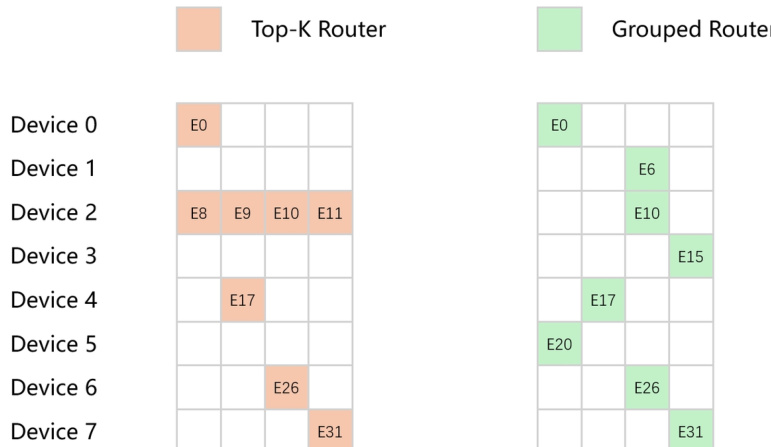
模型架构通过专家扩展过程源自 Intern-S1。这种“升级循环”(upcycling)初始化确保了基础模型中训练良好的专家被分布到各个组中以维持稳定性。为了解决超大规模 MoE 模型中的负载不平衡问题,作者用分组路由器(Grouped Router)取代了传统的 Top-K 路由器。该设计根据设备映射将专家划分为互不相交的组,并在每个组内选择顶级专家,从而在 8 路专家并行策略下实现设备间的绝对负载均衡。
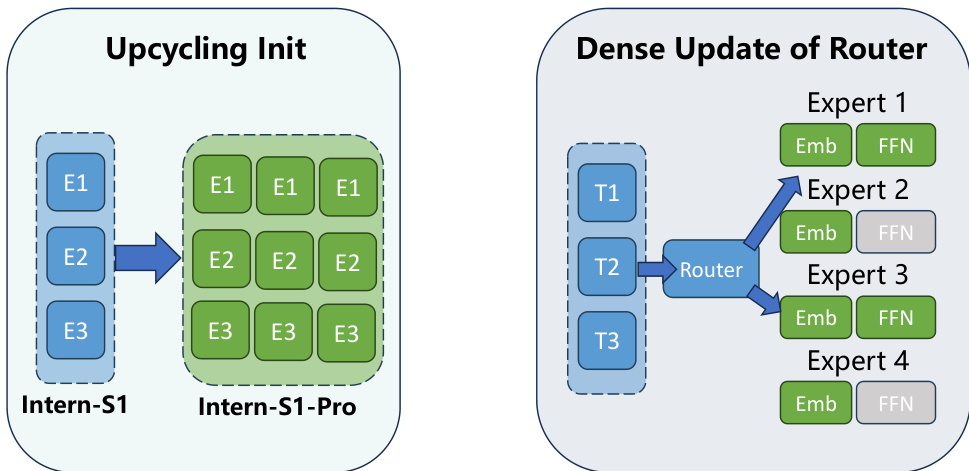
为了实现稀疏路由机制的有效训练,采用了直通估计器(STE)。该技术解耦了前向和反向传播,允许梯度在反向传播期间通过完整的密集 softmax 分布流动,同时在前向传播中保持稀疏选择。这确保了所有路由嵌入都能接收到具有信息量的学习信号,从而改善负载均衡和收敛性。
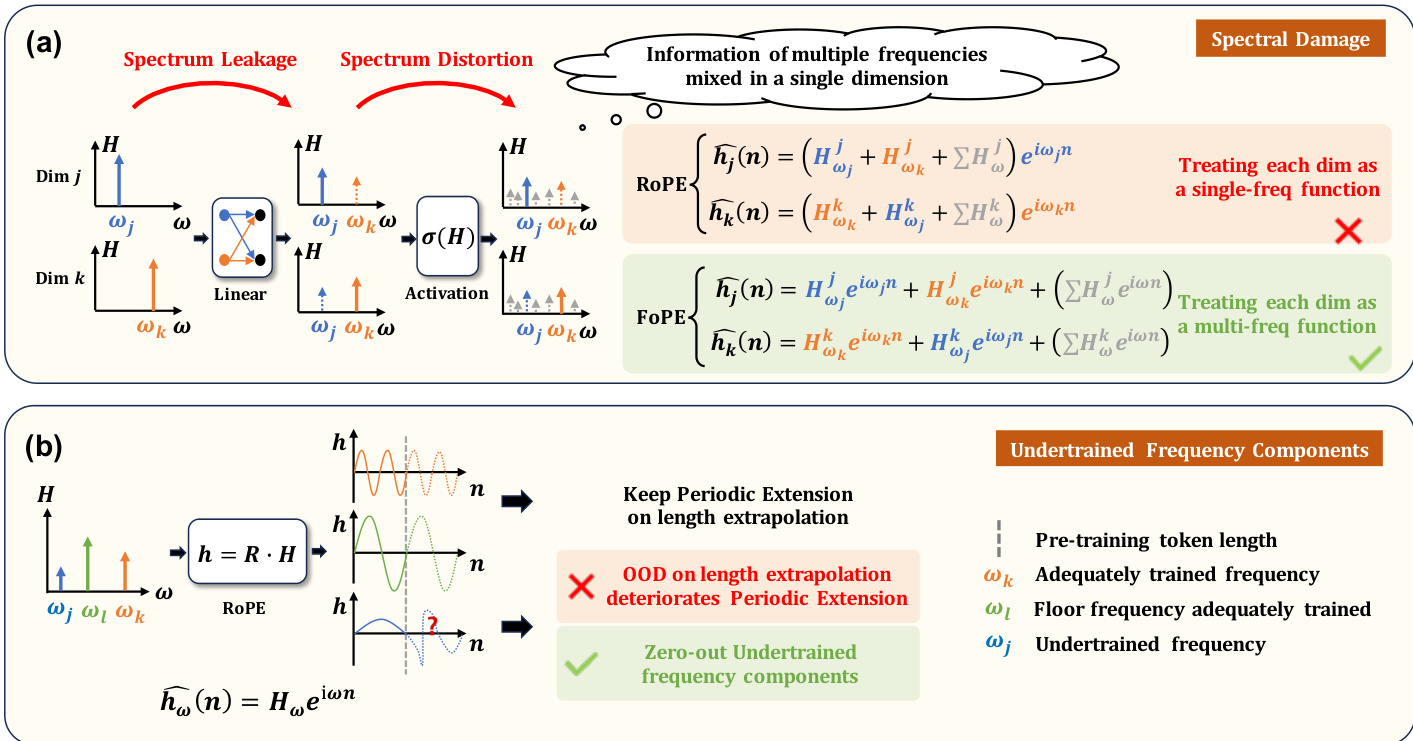
在位置编码方面,模型引入了傅里叶位置编码(FoPE),以更好地处理物理信号的连续性和类波特性。与将每个维度视为单频函数且可能遭受频谱损伤的旋转位置嵌入(RoPE)不同,FoPE 将每个维度建模为多频函数。这种方法更有效地分离信息,并缓解了长度外推期间未充分训练的频分量的相关问题。
该架构还包括一个专用的时间序列模块,用于处理多样化的科学数据。该模块具有自适应下采样模块,可根据信号和采样率动态确定补丁大小和步长。这使得模型能够将异构时间序列压缩到统一的表示空间中,处理从 100 到 106 个时间步的序列,同时保留结构特征。
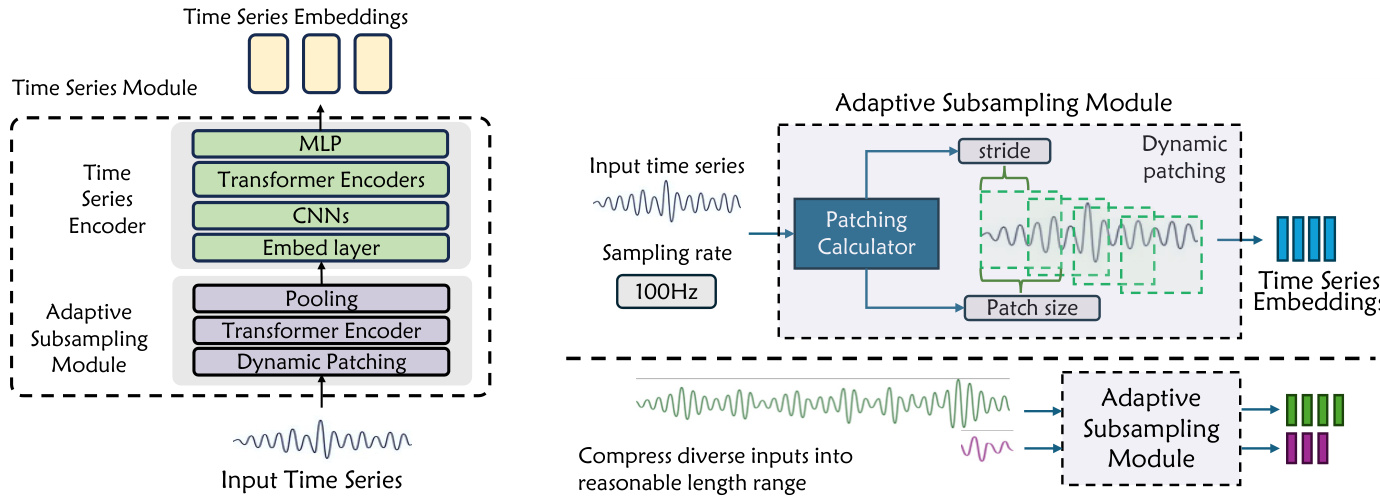
训练过程通过结构化科学数据转换和系统提示隔离等策略,解决了科学与通用数据之间的冲突。此外,针对稀疏 MoE 模型实施了稳定的混合精度强化学习,利用 FP8 量化处理专家层,并使用 FP32 处理语言建模头,以确保数值保真度和训练稳定性。
实验
- 在纯文本和多模态设置下,对科学和通用基准测试的全面评估证实,Intern-S1-Pro 在性能上与顶级开源模型具有竞争力,并在科学推理方面超越了领先的闭源模型。
- 与上一代 Intern-S1 的对比表明,该模型在通用能力、多样化科学领域的覆盖范围以及多步规划和环境感知的智能体技能方面均有显著提升。
- 时间序列实验证实,引入专用的时间序列编码器和动态下采样过程,使模型在捕捉复杂时间动态方面显著优于现有的文本和视觉 - 语言模型。
- 生物学领域的案例研究表明,在专业数据上训练的更大规模的通用模型优于专用的领域特定模型,证明了将通用推理与专业知识相结合能产生协同效应,从而提升解决问题的能力。