Command Palette
Search for a command to run...
面向基于 LLM 的多说话人语音识别的基于门控交叉注意力适配器的两阶段声学自适应方法
面向基于 LLM 的多说话人语音识别的基于门控交叉注意力适配器的两阶段声学自适应方法
Hao Shi Yuan Gao Xugang Lu Tatsuya Kawahara
摘要
大型语言模型(LLM)在双说话人自动语音识别(ASR)的序列化输出训练(SOT)中展现出强大的解码能力,但在三说话人混合等挑战性场景下,其性能显著下降。当前的主要局限在于,现有系统仅通过投影前缀注入声学证据,这种方式不仅存在信息损耗,且与 LLM 的输入空间对齐不完美,导致解码过程中缺乏细粒度的声学 grounding。解决这一局限对于实现鲁棒的多说话人 ASR 至关重要,尤其是在三说话人混合场景下。本文通过显式地将说话人感知的声学证据注入解码器,提升了基于 LLM 的多说话人 ASR 性能。我们首先重新审视了基于连接主义时间分类(CTC)的前缀提示(prefix prompting)方法,并比较了三种包含递增声学信息的变体。其中的 CTC 信息源自我们前期工作中提出的序列化 CTC(serialized CTC)。尽管富含声学信息的前缀提示优于仅依赖 SOT 的基线,但仅依靠前缀条件化仍不足以应对三说话人混合场景。为此,我们提出了一种轻量级的门控残差交叉注意力适配器(gated residual cross-attention adapter),并设计了一个基于低秩自适应(LoRA)的两阶段声学适应框架。在第一阶段,我们在自注意力子层之后插入门控交叉注意力适配器,以作为外部内存稳定地注入声学嵌入;在第二阶段,我们利用参数高效的 LoRA 对交叉注意力适配器及预训练 LLM 的自注意力投影进行联合微调,从而在数据有限的情况下提升大型骨干网络的鲁棒性;训练得到的更新最终被合并至基础权重中以用于推理。在 Libri2Mix 和 Libri3Mix 数据集上的实验表明,无论是在干净还是噪声环境下,该方法均取得了 consistent 的性能提升,并在三说话人设置中表现出尤为显著的改进。
一句话总结
来自 IEEE 附属机构的作者提出了一种基于大语言模型(LLM)的多说话人自动语音识别(ASR)两阶段声学适应框架。该框架通过门控交叉注意力适配器和 LoRA 微调注入说话人感知的证据,显著提升了在具有挑战性的三人混合场景中的鲁棒性,而在此类场景中,标准的前缀提示方法往往失效。
主要贡献
- 本文系统比较了三种具有递增声学内容的连接主义时间分类(CTC)衍生前缀变体,以评估它们在多说话人设置中为大型语言模型(LLM)解码器提供显式指导的有效性。
- 提出了一种轻量级门控残差交叉注意力适配器,用于在自注意力子层之后注入说话人感知的声学嵌入作为外部记忆,从而在每一步解码过程中动态访问细粒度的声学证据。
- 提出了一种利用低秩更新(LoRA)的两阶段声学适应框架,用于优化交叉注意力适配器和预训练 LLM 的自注意力投影。在 Libri2Mix 和 Libri3Mix 上的实验表明,该方法带来了持续的性能提升,特别是在具有挑战性的三人混合场景中。
引言
大型语言模型(LLM)作为序列化输出训练(Serialized Output Training)中的强大解码器,广泛应用于多说话人自动语音识别,但在处理复杂的三人混合场景时,其性能会显著下降。先前的方法依赖于将声学证据投影到静态前缀中,这往往导致有损表示,无法提供解耦密集交织语音流所需的细粒度基础。为此,作者提出了一种两阶段声学适应框架,利用轻量级门控残差交叉注意力适配器,将说话人感知的声学证据直接注入 LLM 解码器。此外,他们还利用参数高效的 LoRA 更新对适配器和 LLM 的自注意力投影进行了微调,确保了即使在数据有限的条件下也能实现稳定的训练和鲁棒的性能。
数据集
-
数据集构成与来源:作者在 LibriMix 上评估了其模型,LibriMix 是基于 LibriSpeech 语料库构建的重叠语音识别基准。噪声条件下的加性噪声采样自 WHAM! 语料库。
-
子集详情:
- Libri2Mix:使用官方脚本和标准的 ESPnet 偏移设置,基于 LibriSpeech 的 train-clean-100、train-clean-360、dev-clean 和 test-clean 子集合成,用于两人配置。训练集包含约 270 小时的语音,而开发集和测试集各包含约 11 小时。
- Libri3Mix:使用自定义偏移文件生成,以确保三人混合场景具有多样化的起始时间配置。训练集包含约 186 小时的语音,开发集和测试集各包含约 11 小时。
-
在模型训练中的使用:作者遵循官方 LibriMix 协议生成 Libri2Mix 和 Libri3Mix 混合数据。这些数据集作为主要的评估基准,其中训练集用于模型优化,开发集和测试集用于性能评估。
-
处理与元数据:团队利用官方 LibriMix 脚本合成干净混合数据,并应用特定的偏移文件来控制说话人的起始时间。虽然两人场景使用了标准设置,但为了增加配置多样性,针对三人混合场景构建了自定义偏移文件,这些文件计划在评审期结束后发布。
方法
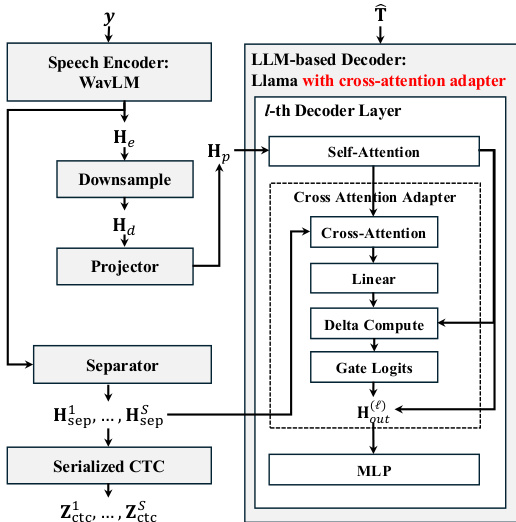
作者提出了一种基于 LLM 的多说话人 ASR 框架,将声学证据直接集成到解码器中。该系统由语音编码器、用于说话人特定流的分离器和增强有交叉注意力适配器的 LLM 解码器组成。
参考框架图以了解整体架构。输入波形 y 由语音编码器(WavLM)处理,生成帧级表示 He。这些特征通过下采样进行时间缩减至 Hd,并投影到 LLM 隐藏维度 Hp。同时,分离器模块处理编码器输出,生成 S 个说话人特定流 Hsep1,…,HsepS,这些流也用于序列化 CTC 监督。
基于 Llama 的 LLM 解码器在每个解码层中集成了专门的交叉注意力适配器。如下图所示,该适配器插入在自注意力子层之后。它接收来自自注意力的隐藏状态作为查询(Queries),并将投影后的声学记忆作为键(Keys)和值(Values)。适配器计算上下文向量,随后通过线性层和 Delta 计算块进行处理。门控 Logits 机制控制残差更新,确保在注入声学信息的同时不破坏预训练的语言表示。
训练过程遵循两阶段适应策略,旨在平衡语义初始化与鲁棒的声学条件化。下图展示了每个阶段的流程和动机。
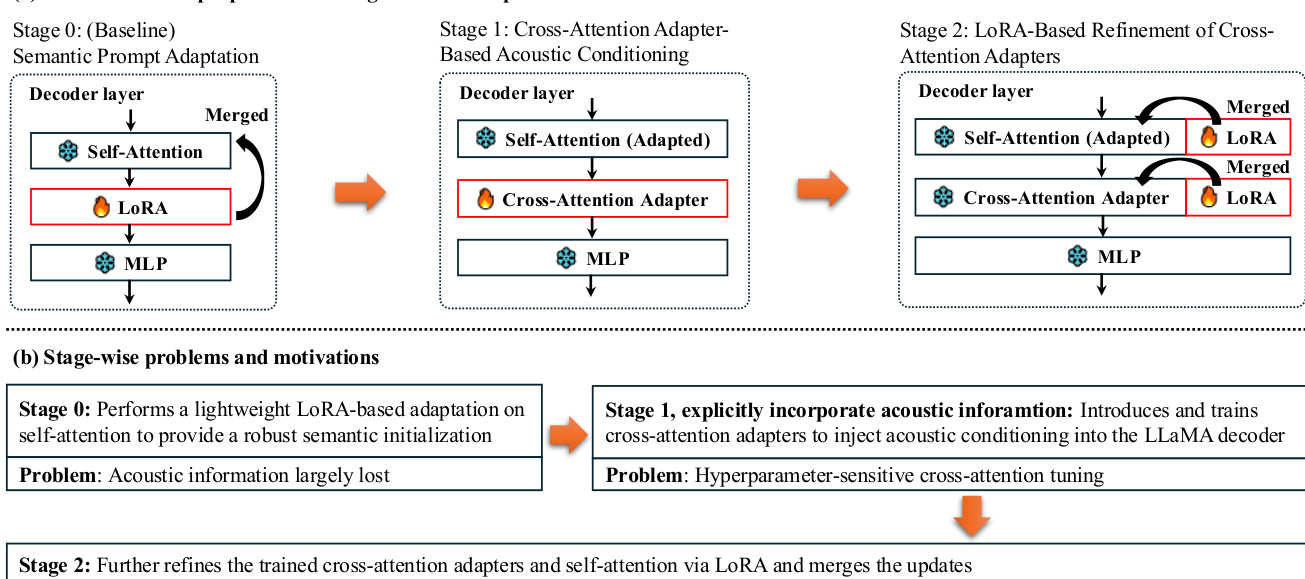
阶段 0 作为基线,使用 LoRA 对 LLM 解码器的自注意力投影进行适应。这提供了鲁棒的语义初始化,而无需显式的声学注入。阶段 1 引入门控交叉注意力适配器,以显式地融入声学信息。该阶段训练适配器通过门控残差更新将说话人感知的声学证据注入解码器。然而,训练这些适配器可能对超参数敏感。为解决这一问题,阶段 2 对交叉注意力适配器和自注意力投影应用基于 LoRA 的微调。这种微调增强了适应能力,并提高了在数据有限情况下的鲁棒性。最后,将学习到的低秩更新合并到基础权重中, resulting 得到一个在推理时不增加额外参数的模型。
实验
- 基于 LLM 的系统通过利用语义先验,显著提升了两人混合场景的性能,但由于静态前缀条件化中的上下文分辨率不足,在三人场景中表现挣扎。
- 富含声学信息的前缀通过为 LLM 解码提供更好的约束,优于纯文本提示,但仅靠单样本前缀(one-shot prefixing)在严重重叠的语音中仍不足以进行细粒度的说话人分配。
- 通过交叉注意力在解码器端注入声学信息,通过实现逐步访问声学记忆,在三人条件下带来了显著增益;而朴素的堆叠交叉注意力由于过度条件化,可能会降低较简单的两人场景的性能。
- 与朴素堆叠相比,门控交叉注意力适应通过调节注入水平并保留预训练语言表示,提供了更稳定且有效的声学条件化,尽管在最具有挑战性的区域中,其表现仍落后于序列化 CTC 对齐。
- 阶段 2 的 LoRA 微调增强了鲁棒性并降低了超参数敏感性,其中交叉注意力适配器和自注意力投影的联合微调始终带来最佳的整体结果,特别是对于 3B 规模的骨干网络。
- 所提出的方法在三人设置中相比现有流程具有明显优势,且更大的 LLM 解码器即使在使用序列化 CTC 参考时,也始终优于从头训练的模型。