Command Palette
Search for a command to run...
AutoResearch AI:迈向人工智能驱动的科学发现研究自动化
AutoResearch AI:迈向人工智能驱动的科学发现研究自动化
摘要
科学研究正日益受到人工智能系统的重塑,这些系统已超越孤立的辅助功能,介入文献 grounding(背景定位)、假设生成、实验验证、报告撰写及修订等更长周期的流程。这一转变标志着“AI for Science”(科学领域人工智能)从任务级辅助向工作流级研究自动化的演进。然而,该领域目前仍处于碎片化状态:现有系统在自主性、领域范围、执行环境、验证机制以及对人类监管的依赖程度等方面存在显著差异。尽管许多系统能够生成看似合理的观点、操作工具、运行受控实验或产出精美的成果,但在证据保全、可复现性、淘汰薄弱研究方向、溯源追踪、跨领域鲁棒性以及可问责的科学闭环等方面,仍面临持续的挑战。本综述以 AutoResearch 为视角考察上述发展动态,我们将 AutoResearch 定义为 AI 驱动的科学工作流自动化的发展谱系。在此谱系中,Vibe Research(氛围式研究)代表人类主导的区域,即通过基于 prompt 的辅助和经人工验证的执行来扩展局部研究能力;而新兴的 AI 主导系统则开始协调发现循环中的更大 portions(部分),尽管尚未实现稳健的自主性。
一句话总结
本综述通过 AutoResearch 的视角考察了由 AI 驱动的科研工作流自动化,定义了从人类引导的 Vibe Research 到新兴 AI 主导系统的发展谱系,同时分析了证据保存和可重复性方面的持续挑战,以促进负责任的科学闭环。
核心贡献
- 本综述将 AutoResearch 定义为 AI 驱动科研工作流自动化的发展谱系,并将 Vibe Research 指定为人类引导区域,其中 AI 通过基于提示的辅助和人类验证的执行扩展局部能力。
- 本综述通过以工作流为中心的自主性谱系组织该领域,并考察了 The AI Scientist 和 Co-Scientist 等系统,以证明实践前沿仍集中在人类引导的辅助上。
- 本综述分析了领域条件的自主性上限,表明计算科学为工作流闭环提供了有利条件,而实验领域由于物理和安全限制施加了更严格的限制。
引言
科学研究正从孤立的 AI 辅助过渡到工作流级别的自动化,其中系统管理文献基础、假设生成和实验。这一转变之所以重要,是因为它扩大了 AI 在整个发现循环中的参与,但引入了证据保存、可重复性和负责任科学闭环方面的挑战。先前的工作往往通过关注模型架构或任务完成来碎片化该领域,同时忽视了控制和验证权威的重新分配。作者将 AutoResearch 定义为工作流级别的范式,并引入了五级自主性谱系,以区分人类引导的辅助与 AI 主导的协调。他们进一步围绕五个反复出现的工作流条件组织技术基础,并提出以科学可信度为中心的评估维度,如新颖性和来源。他们的分析表明,自动化的实践上限强烈依赖于领域条件,在计算领域比在具身或高风险科学领域发展得更快。
数据集
-
数据集组成与来源
- 作者从当前的 AutoResearch 景观中策划了异构的评估工具栈。
- 来源包括 DiscoveryBench、ResearchBench、MAgentBench、ScienceAgentBench、DeepScholar-Bench 和 CiteME。
- 该集合代表了一套碎片化的资源,而非统一的基准制度。
-
每个子集的关键细节
- 发现基准测试结构化搜索、分解和面向前沿的构思。
- 实验和验证基准测试强调可执行行为、复制和实证纪律。
- 深度研究基准测试评估长视野检索、报告构建和开放世界信息集成。
- 审查和来源工具针对主张支持、引用可追溯性和部署文档。
-
论文如何使用数据
- 论文利用这些资源展示从任务准确性到工作流特定科学负担的转变。
- 基准作为 AutoResearch 行为的补充约束,而非相互替代。
- 评估涵盖新颖性、有效性、可靠性和来源等不同工作流阶段的维度。
- 未定义训练分割或混合比例,因为重点仍在于评估基础设施。
-
处理和选择细节
- 作者保留其主要贡献是可用于研究 agents 的直接可用评估工具的资源。
- 基准按评估角色而非主题或领域分组。
- 选择过程突出了 AutoResearch 评估关于新颖性和有效性的方法属性。
- 性能被视为有界能力的证据,而非成熟 AI 主导自主性的充分支持。
方法
作者将 AutoResearch 的技术基础构建为一组工作流条件,而非单一的大型模型,这些条件约束了科学活动如何变得有据可依、可执行、可修订和可交流。整体架构被分解为五个反复出现的阶段,将原始研究输入转化为可交流的科学制品。参考框架图了解 AutoResearch 分解为这五个阶段,从文献基础到报告。
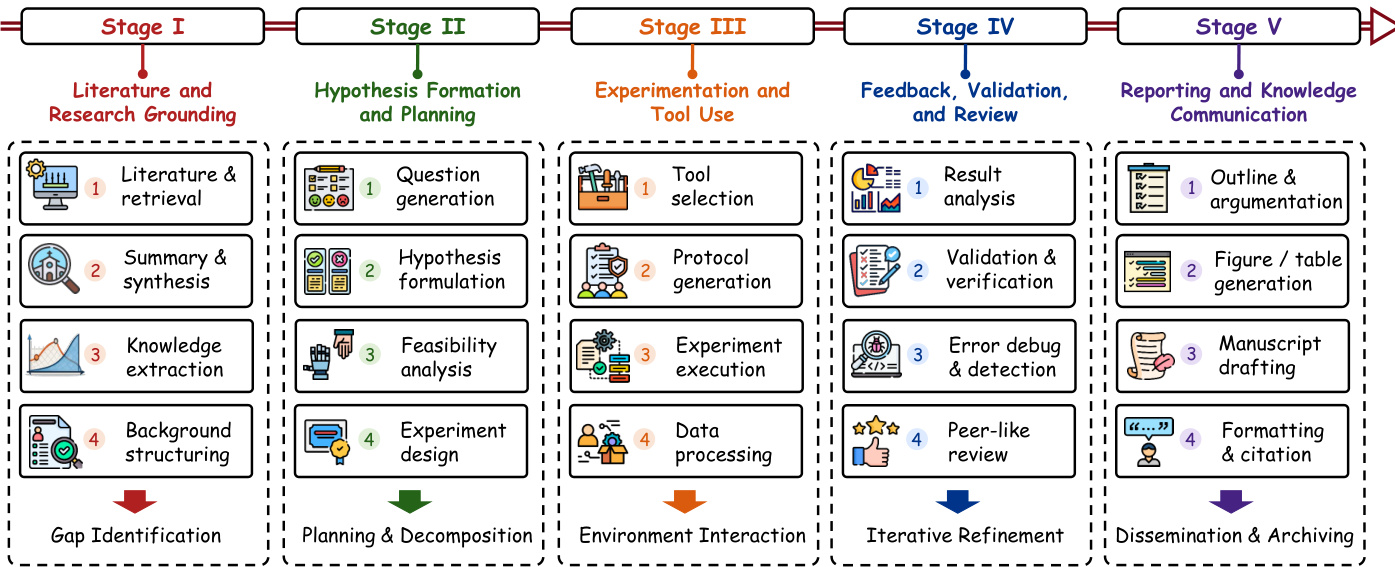
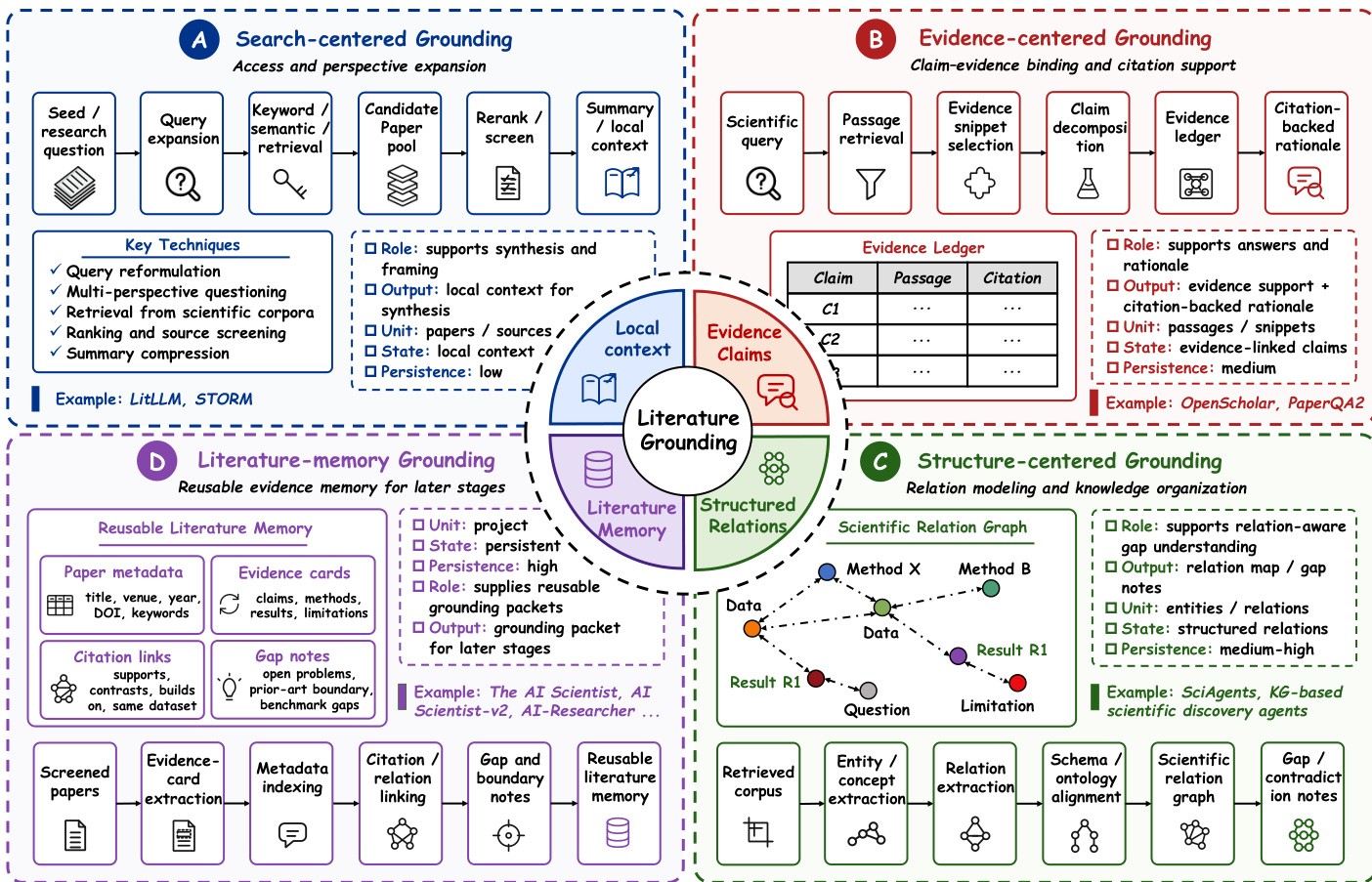
阶段 I:文献与研究基础 文献与研究基础是第一个主要技术阶段,因为工作流的每个后续部分都取决于如何访问、过滤、表示和重用先前工作。此阶段建立了提出假设、设计实验和解释结果所依据的证据基础。核心技术关切不仅是系统能否找到相关论文,而是能否构建一个随着工作流演变而保持可用、可检查和可更新的科学背景。当前的基础技术组织为四个反复出现的制度:以搜索为中心、以证据为中心、以结构为中心和文献记忆基础。这些制度在证据强度、持久性和工作流集成方面有所不同。参考下图了解这些制度作为证据状态构建的比较。
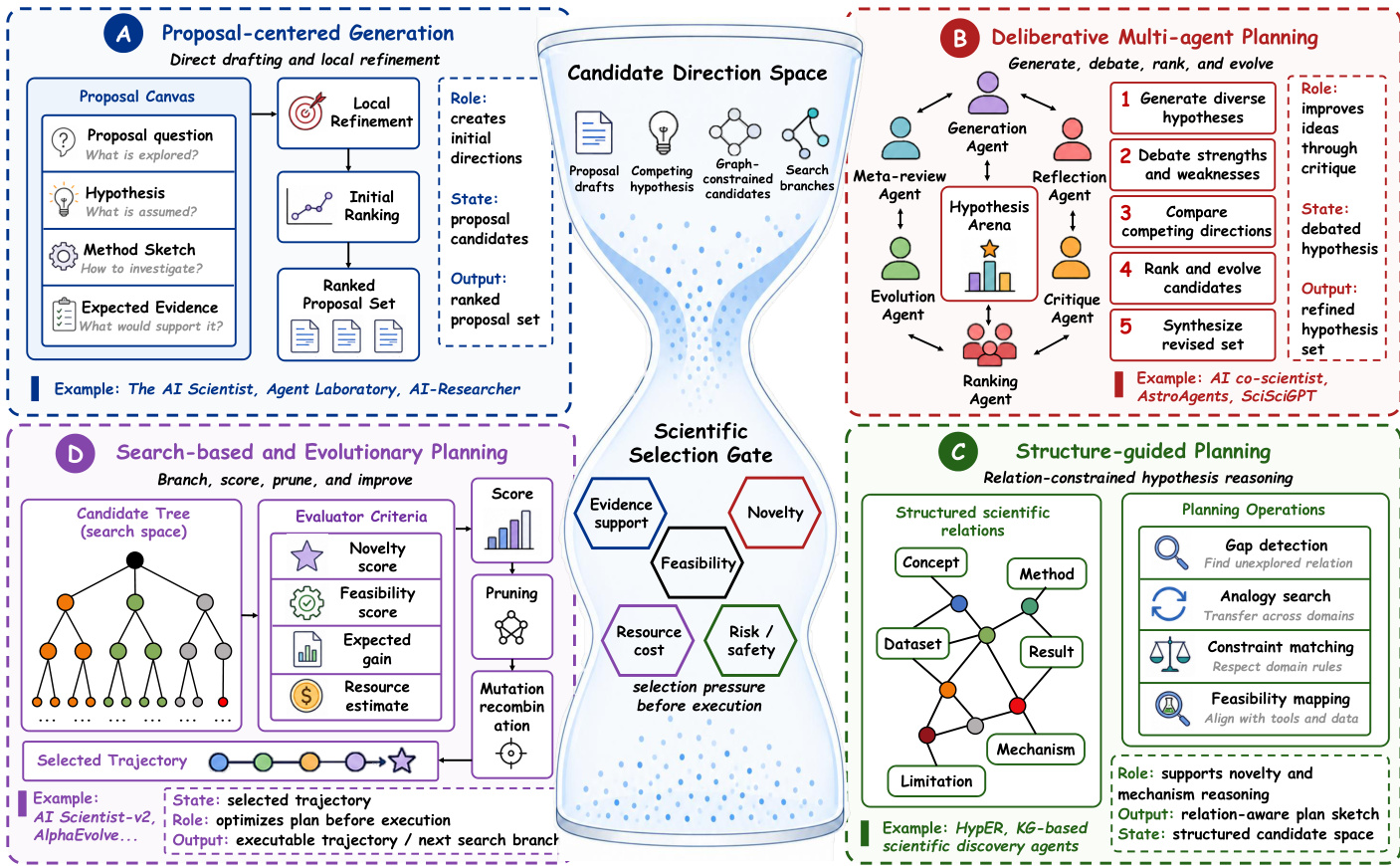
阶段 II:假设形成与规划 假设形成与规划构成第二个主要技术阶段,其中基础科学背景被转换为候选方向。如果文献基础决定了系统对先前工作的了解,此阶段决定了系统准备如何利用这些知识。技术目标是将基础背景转化为有纪律的科学方向,以便后续阶段继承足够基础、可比较和可拒绝的候选假设和计划。当前的假设形成技术组织为四个反复出现的制度:以提案为中心的构思、审议式多 agent 构思、结构引导的构思和基于搜索的构思与规划。参考下图了解这些规划制度的比较。
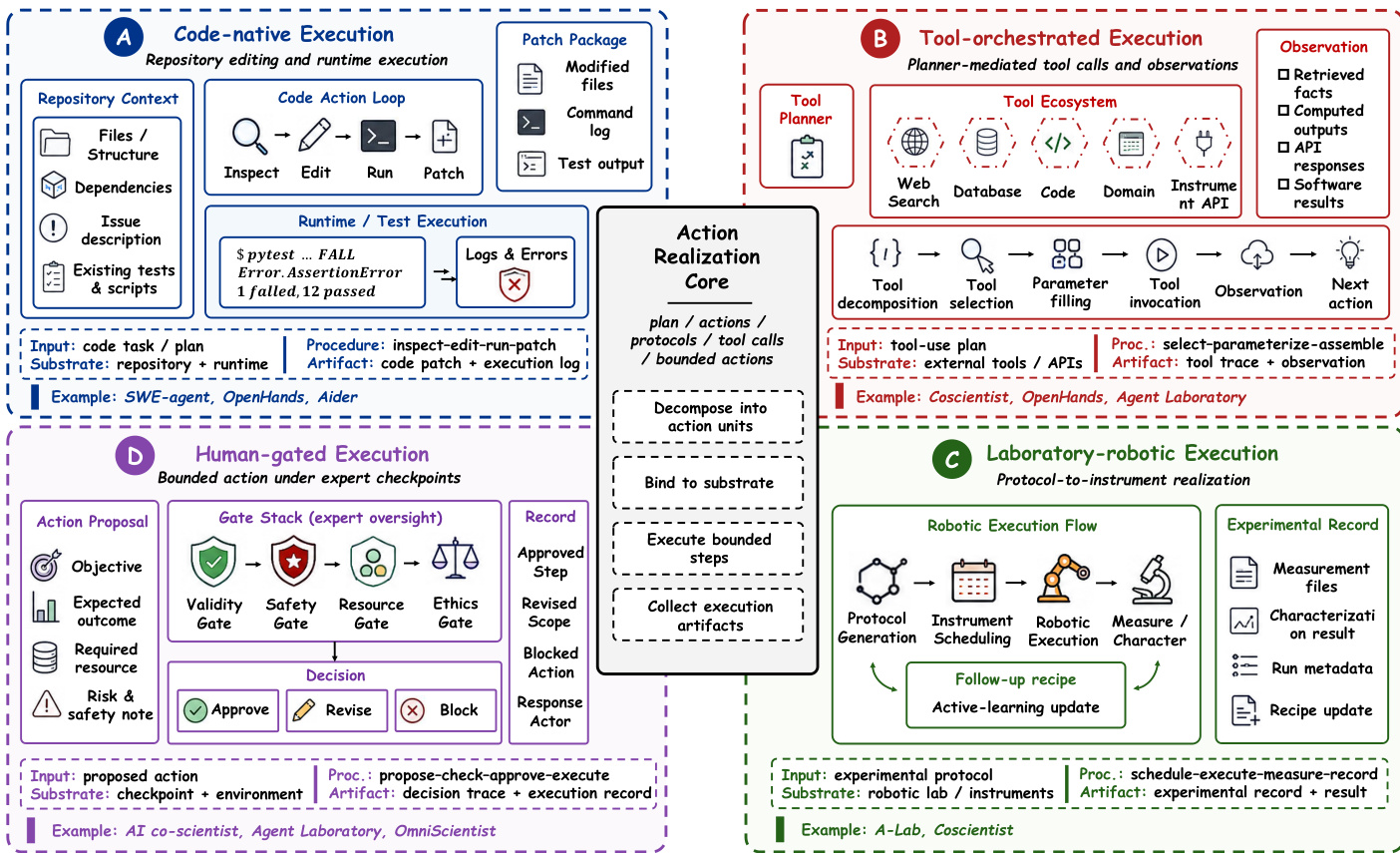
阶段 III:实验与工具使用 实验与工具使用构成第三个主要技术阶段,因为它们决定了候选科学方向如何转化为具体行动。如果基础建立证据依据且规划决定哪些方向值得追求,执行则决定这些方向能否通过代码、工具、仪器或协议实现。此阶段不仅限于通用工具调用,还包括仓库编辑、代码执行、模拟器使用和科学软件调用。当前的执行技术组织为四个反复出现的制度:代码原生、工具编排、实验室机器人和人工门控执行。参考下图了解这些行动实现制度的比较。
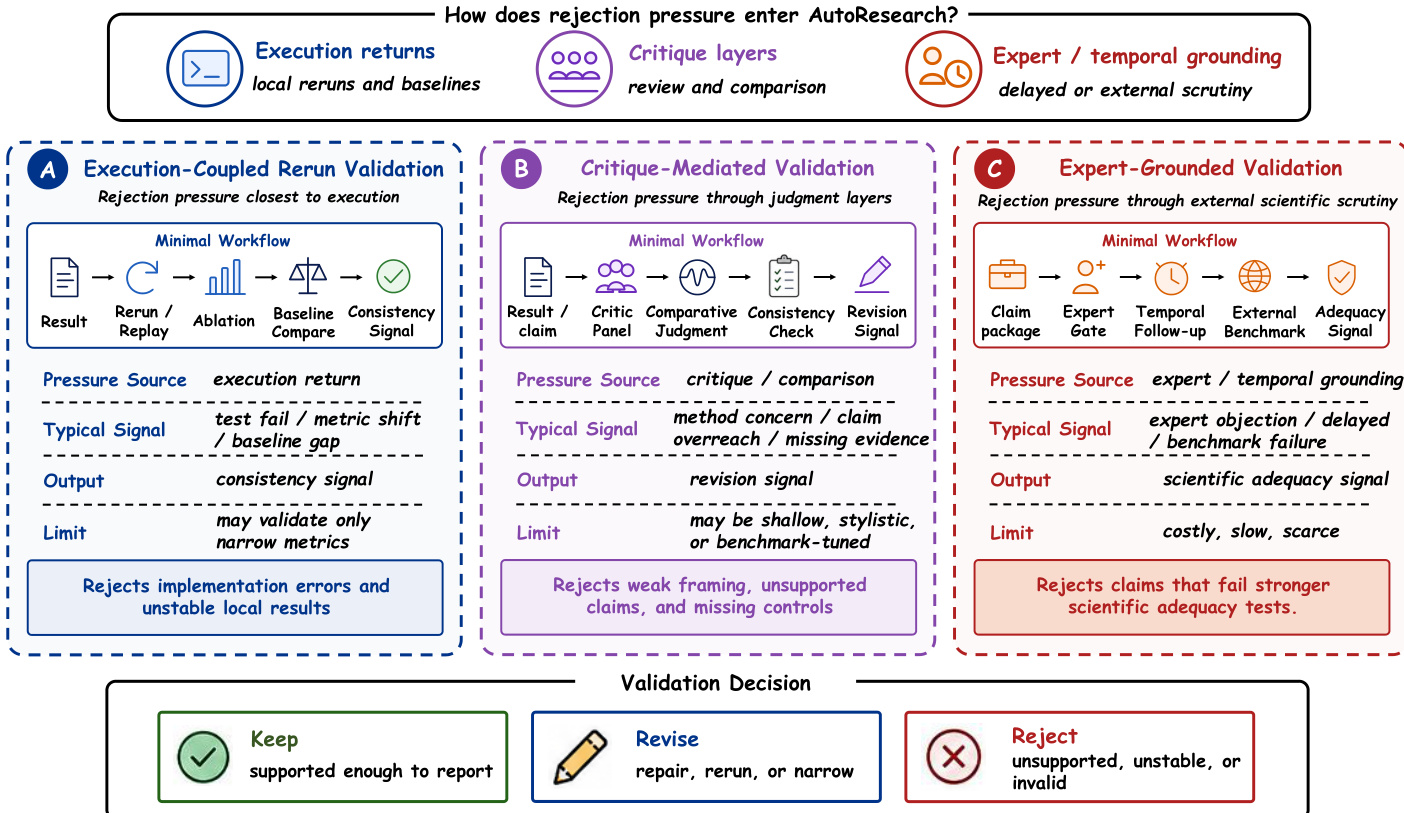
阶段 IV:反馈、验证与审查 反馈、验证与审查构成第四个主要技术阶段,因为它们决定了中间和最终输出是被修订、拒绝还是允许作为候选科学主张持续存在。如果执行将方向暴露于操作或实证阻力下,验证则决定生成的输出是否经过足够强的过滤以支持可信的科学进展。此阶段包括基线比较、重运行验证、错误检测和批判性审查。当前的验证技术组织为三个反复出现的制度:执行耦合重运行验证、批评介导的验证和专家或时间基础验证。参考下图了解这些验证制度的比较。
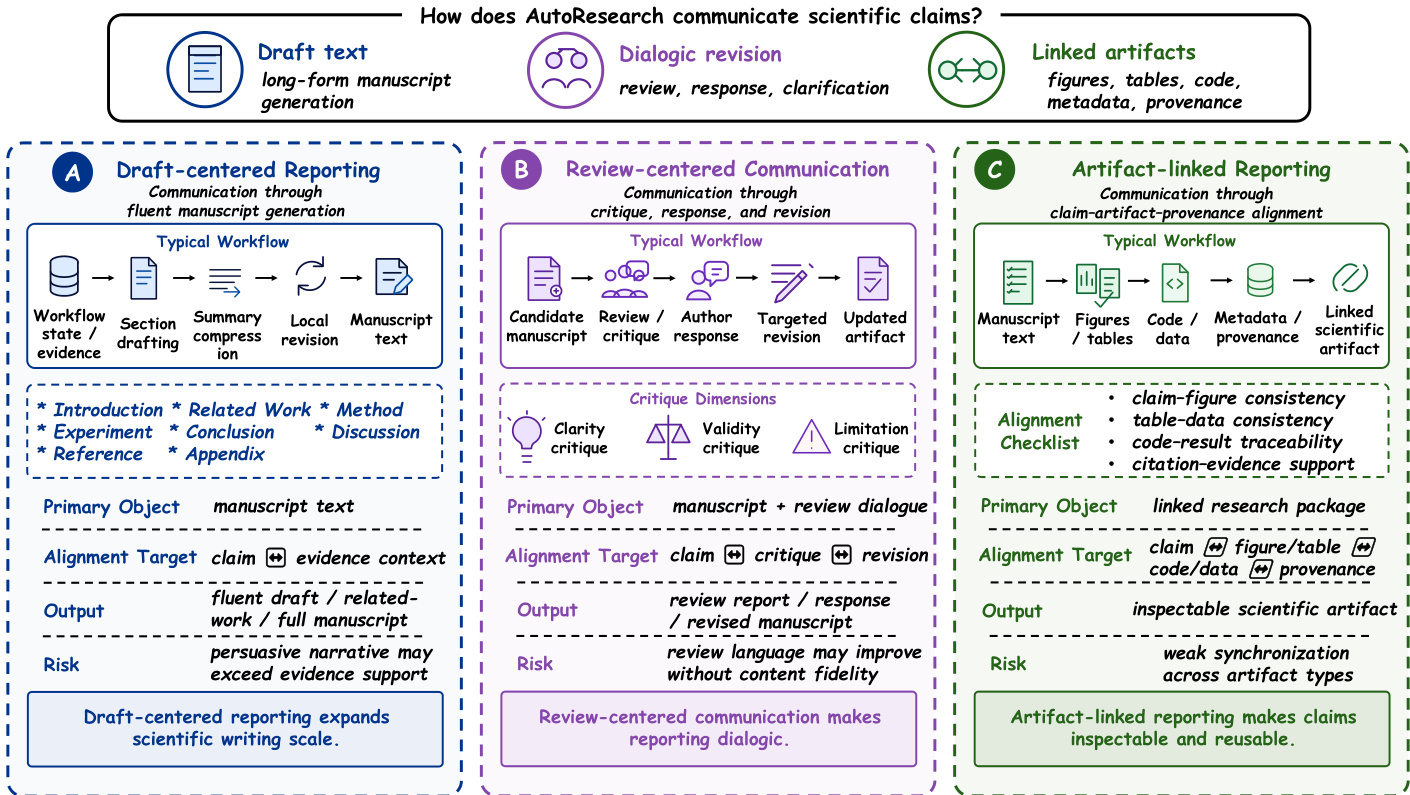
阶段 V:报告与知识交流 报告与知识交流构成第五个主要技术阶段,因为它们决定了工作流状态如何转化为可检查、可批评和可重用的科学制品。如果验证决定了哪些输出经受住了审查,报告则决定了这些过滤后的输出如何呈现给科学受众。此阶段包括起草、修订、图表制作,以及将主张与证据、代码和来源链接。当前的报告技术组织为三个反复出现的制度:以草稿为中心的报告、以审查为中心的交流和以制品链接的报告。参考下图了解这些交流制度的比较。
实验
计算和形式科学目前充当 AutoResearch 的主要测试床,因为它们的数字底层支持快速迭代和端到端工作流,而化学、生物学和社会科学等其他领域仅支持受物理或解释因素约束的狭窄自主岛屿。当前的评估设置主要测量工作流执行和可靠性,而非科学价值,使得新颖性和长期影响等维度难以通过短视野基准评估。因此,现有系统验证了其在有界实验循环内运行的能力,但在没有人工监督的情况下选择重大问题或建立广泛科学闭环方面仍然有限。