Command Palette
Search for a command to run...
MobileGym:一种用于移动 GUI Agent 研究的可验证且高度并行的仿真平台
MobileGym:一种用于移动 GUI Agent 研究的可验证且高度并行的仿真平台
摘要
本文提出 MobileGym,这是一个基于浏览器托管、轻量级且完全可控的日常移动应用环境,旨在实现高交互保真度,且无需复现专有后端。它使日常应用能够实现两种以往难以企及的能力:基于结构化 JSON 状态的确定性状态评判以提供可验证的结果信号,以及通过低成本并行 rollout 实现可扩展的在线 RL。完整的环境状态以结构化 JSON 形式进行捕获、配置、分叉与比较。单个服务器可托管数百个并行实例,每个实例内存占用约 400 MB,冷启动时间约 3 秒。分层状态模型与声明式任务定义框架确保了状态可编程性与任务创建在大规模应用中的实用性;单一的编程化评判机制则同时提供确定性的评估判决与密集的 RL 奖励。配套的 MobileGym-Bench 基准测试提供了 416 个参数化任务模板,涵盖 28 款应用,其中包括 256 个测试模板与 160 个训练模板。该基准配备确定性评判器以及结构化的 AnswerSheet 协议,从而避免了自由文本匹配失败的问题。在 Sim-to-Real 案例研究中,基于 Qwen3-VL-4B-Instruct 的 GRPO 算法在 256 任务测试集上取得了 +12.8 个百分点的性能提升;在包含 59 个任务的真实设备信号子集上,真实设备执行保留了仿真端训练增益的 95.1%。项目页面:https://mobilegym.github.io.
一句话总结
MOBILEGym 是一个可验证的、基于浏览器的移动 GUI agent 仿真平台。该平台通过结构化的 JSON 状态模型与确定性的程序化评估机制,无需依赖专有后端即可运行。这种设计支持可扩展的并行强化学习。实验表明,在 Qwen3-VL-4B-Instruct 上使用 GRPO 进行训练,可在 MOBILEGYM-BENCH 的 256 任务测试集上获得 +12.8 分的提升,且在真机执行过程中能保留 95.1% 的性能增益。
核心贡献
- MOBILEGYM 是一个基于浏览器的环境,能够将完整的移动界面状态捕获为结构化 JSON,从而实现确定性评估与基于快照的 rollout 分支。该架构支持低成本并行执行与声明式任务框架,在无需专有后端的情况下促进可扩展的强化学习。
- MOBILEGYM-BENCH 提供涵盖 28 款日常应用的 416 个参数化任务模板,配备确定性评估器与 AnswerSheet 协议,以防止自由文本匹配失败。该基准测试包含经验校准的难度层级与诊断指标,以标准化 agent 评估流程。
- 使用 GRPO 训练 Qwen3-VL-4B-Instruct 可在 256 任务测试集上获得 12.8 分的提升。Sim-to-Real 研究证实,真机执行能够保留模拟训练中 95.1% 的性能增益。对九款 agent 的评估及 VLM-judge 审计结果均验证了该环境在交互式 GUI agent 开发中的实用价值。
引言
移动 GUI agent 正快速发展,能够从截图与自然语言指令中处理智能手机任务,然而利用在线强化学习扩展其训练仍受限于可复现环境的缺失。既往研究被迫在基于模拟器的平台与真机基准测试之间做出艰难权衡:前者可重复但仅限简单应用,且需大量计算资源;后者覆盖日常应用,但存在状态不可控、操作不可逆以及无法并行化 rollout 的问题。本文引入 MOBILEGym 以解决这些结构性限制。MOBILEGym 是一款轻量级的基于浏览器的仿真环境,将所有设备与应用状态表示为结构化 JSON。该架构使环境完全可读、可写且支持分支,从而在标准硬件上实现确定性的结果验证、安全的沙盒执行以及数百个并行实例。通过将此可编程基础设施与类型化的 AnswerSheet 协议及全面的 416 任务基准测试相结合,研究团队提供了一个可扩展的基础架构,弥合了真实移动交互与可靠在线 agent 训练之间的差距。
数据集
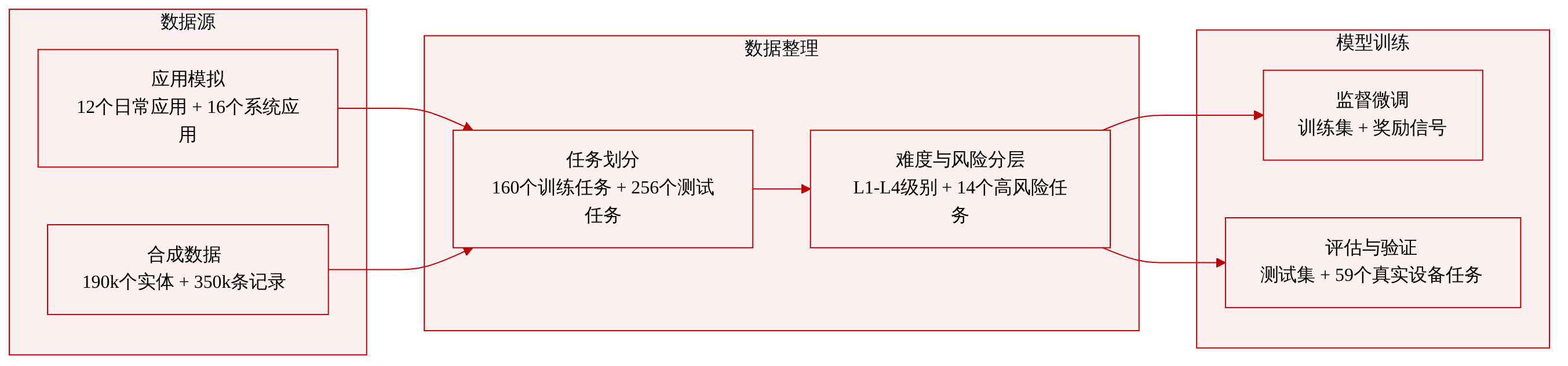
数据集构成与来源
- 本文提出 MOBILEGYM-BENCH,这是一个基于浏览器的类 Android 仿真环境,包含 28 款重构应用中的 416 个参数化任务模板。
- 数据集涵盖 12 款日常应用与 16 款系统应用,均通过 LLM 辅助实现构建,并填充了超过 19 万个合成实体与 35 万条从可配置 JSON 默认值中加载的结构化记录。
- 任务模板被严格划分为 160 任务的训练集与 256 任务的测试集,划分之间无重叠任务。
子集详情与筛选
- 训练集划分侧重于涵盖核心交互技能的单应用任务,测试集则将 36% 的任务分配给跨应用工作流,以评估分布外泛化能力。
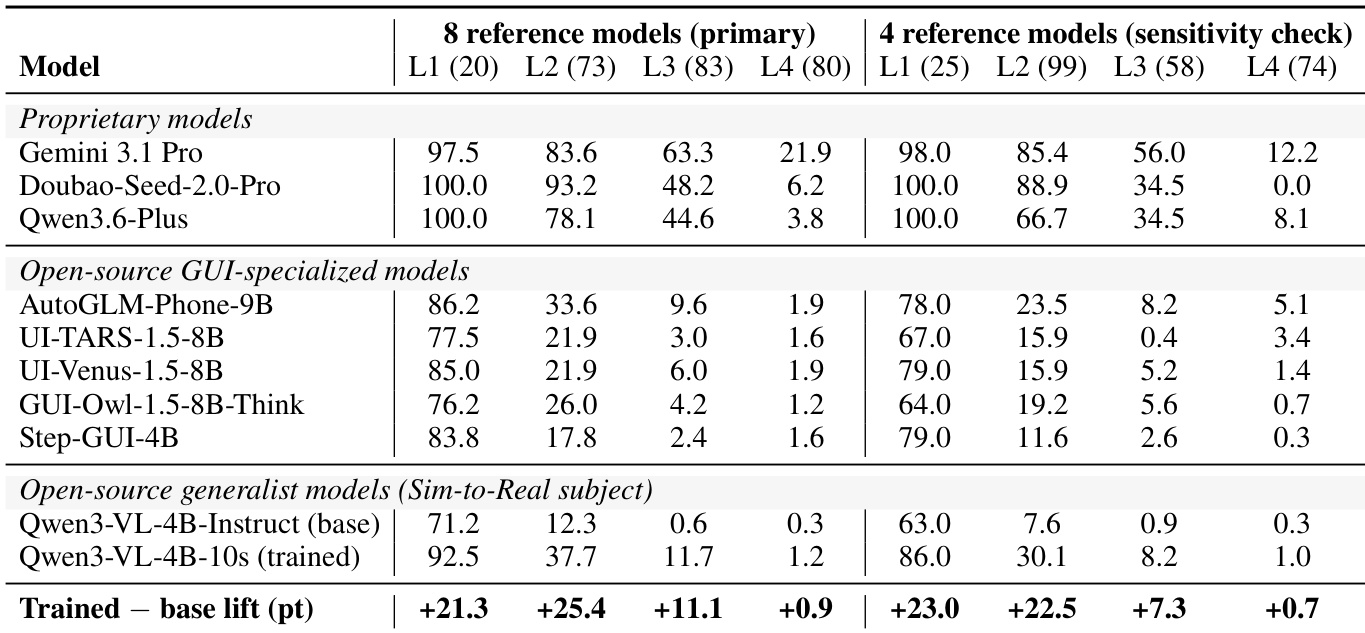
- 难度等级通过事后经验校准分配,该过程使用八款参考模型完成。测试集根据成功率与精确率划分为四个诊断层级:Level 1 包含 20 个任务,Level 2 包含 73 个,Level 3 包含 83 个,Level 4 包含 80 个。
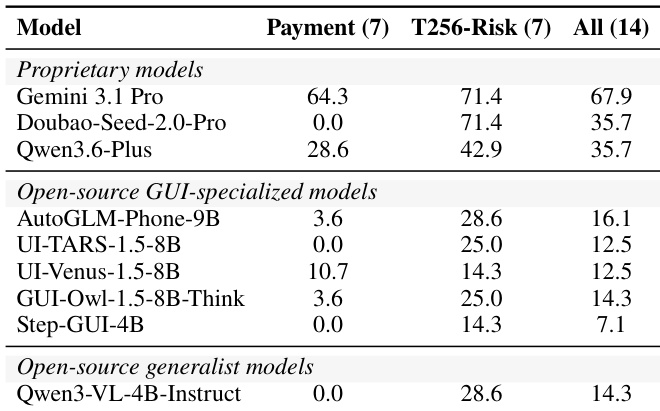
- 一个包含 14 个任务的专用高风险子集独立隔离了独立支付操作与不可逆的账户修改,用于衡量高后果场景下的执行能力。
- 针对真机验证,本文采用基于结果的分层抽样方法筛选出 67 个信号任务,排除 8 个不可复现案例,最终确定包含 59 个任务的验证集,并补充 15 项稳定失败的基础检查。
数据使用与处理
- 本文利用训练集划分进行监督微调与强化学习,依赖环境提供的确定性状态重置与结构化奖励信号。
- 所有任务均支持动态参数采样,Level 3 与 Level 4 任务进一步包含两到三个正交指令变体,以在不修改应用代码的前提下扩展多样性。
- 评估框架将交互轨迹处理为将视觉帧与 JSON 状态转换配对的五元组,从而支持为世界模型、状态预测器与奖励验证器进行可控的数据合成。
- 任务元数据通过来自 13 标签词库的能力标签进行丰富,同时测试分布针对难度、目标类型与组成类别进行明确追踪。
元数据构建与环境处理
- 本文将所有交互坐标归一化至统一的 0 到 1000 网格,使原生 agent 动作空间能够清晰映射到标准化的 17 动作抽象层。
- 每个交互字段均附带明确的提示字符串,用于定义严格的输入格式。自动化评估器会强制执行该格式,以防止歧义并消除因自然语言变化导致的误报。
- 后端服务与动态内容被替换为可控制的 JSON 状态对象,在确保可复现评估与稳定强化学习信号的同时,将 agent 面向的交互语义与真实服务器行为隔离。
- 评估流程通过为数值输入应用浮点数容差,并直接比较结构化状态差异来验证任务完成情况,从而规避了脆弱的字符串匹配机制。
方法
MOBILEGYM 框架设计为一款基于浏览器的轻量级仿真环境,能够在保持对环境状态的完全控制权的同时,实现与日常移动应用的高保真交互。该系统专注于交互保真度,即建模可见的 UI 表面及对用户输入的行为响应,而无需复制专有后端系统或底层 Android 内部机制。这一目标通过分层状态模型实现,该模型将大型只读世界数据(如公开帖子、商品或联系人)与紧凑的可变运行时状态分离开来,后者用于捕获由 agent 引发的变更。运行时状态与操作系统运行时(包括任务栈、权限与系统事件)共同构成结构化环境状态,该状态对外暴露以支持配置、重置与比较。最终的用户界面通过将运行时状态叠加至世界数据上生成,确保所有变更均可追踪且支持程序化检查。
如图下方所示,系统架构围绕组合模型构建,最终 UI 通过结合世界数据、运行时叠加层与 OS 运行时组件进行渲染。环境状态被序列化为结构化 JSON,从而实现确定性快照、分支与状态恢复。这支持并行 rollout,并助力可扩展的在线强化学习。环境状态通过具有非持久化策略的统一状态存储进行管理,浏览器刷新等同于设备重启,即在保留用户数据的同时重置运行时状态。该设计使得转账或删除等高风险操作能够无后果执行,因为模拟器可在每条轨迹结束后恢复至操作前的状态。
该系统为每款应用支持声明式导航规范,形式化为扩展有限状态机(EFSM)。EFSM 模型定义了 UI 状态、输入、转换守卫与更新操作,同时支持运行时导航与静态分析。转换函数采用数据驱动方式,允许基于应用状态变量进行条件分支,并支持状态空间的动态扩展。EFSM 语法中的守卫机制可对路由路径、查询参数或应用状态值施加约束,从而确保正确的导航行为。该规范用于驱动运行时的 UI 转换,并生成候选任务轨迹,支持自动化任务创建与一致性检查。
为确保结果可验证,MOBILEGYM 采用确定性评估机制,通过检查结构化环境状态来评估任务完成情况。每个任务均关联一个程序化评估器,用于检查预期的状态变更并检测非预期的副作用(如意外发送消息或数据修改)。该方法消除了对不可靠视觉语言模型评估的依赖,并提供细粒度、可复现的信号。AnswerSheet 协议进一步提升了可靠性,要求 agent 填写包含类型化字段的结构化表单,这些字段通过特定类型的匹配器(如精确文本、数值容差或选项检查)进行验证。这有效防止了因自由文本匹配启发式规则而产生的误报与漏报。
该系统还支持标准化的应用层架构,每个应用模块均遵循一致的结构,包含清单文件、状态存储、导航规范与默认数据。该设计支持零注册自动发现,并便于新应用与功能的集成。跨应用通信通过意图系统、内容提供程序与广播总线实现,复刻了 Android 的数据与事件共享机制。返回键分发通过优先级链机制进行管理,确保不同 UI 组件间的事件得到正确处理。
在强化学习管线中,环境通过将初始状态分支为多个实例来支持并行 rollout,每个实例独立执行一条轨迹。结构化状态使得高效的状态比较与差异分析成为可能,并生成成功、进度、副作用与过度使用等信号。这些信号用于计算密集的 RL 奖励与基准指标,从而实现可扩展的训练与评估。框架设计支持高吞吐量仿真,单台服务器即可托管数百个并行实例,每个实例仅需约 400 MB 内存与 3 秒冷启动时间。该基础设施支持大规模训练与现实世界迁移研究,Sim-to-Real 案例研究已证明其在真机执行中能够高度保留性能增益。
实验
评估框架在基于浏览器的移动基准测试上对视觉语言 agent 进行测试,采用固定的步骤预算与程序化状态验证,以测量经过校准的难度层级下的成功率、进度与非预期副作用。基准测试结果证明,agent 性能随任务复杂度一致扩展,有效区分了模型能力,同时揭示出环境非预期修改与整体成功率之间并非严格相关。Sim-to-real 迁移实验证实,在仿真中微调的强化学习能够生成高度可迁移的策略,在物理设备上保持性能增益,并成功适应现实世界的 UI 变化。最后,效率分析表明,与传统模拟器配置相比,该轻量级仿真器显著降低了硬件与 API 成本,使得无需专用集群基础设施即可实现可扩展的 agent 训练。
本文展示了不同类别模型的性能对比,强调专有模型的成功率高于开源 GUI 专用模型与通用模型。结果显示专有模型与开源模型之间存在明显的性能差距,专有模型在所有评估指标上均表现出显著更优的结果。类别内部性能存在差异,部分开源模型在特定条件下展现出具有竞争力的表现。专有模型在所有评估指标上均优于开源模型。开源 GUI 专用模型的表现优于开源通用模型。模型类别内部性能存在差异,部分开源模型在特定条件下能够取得具有竞争力的结果。
下表对比了使用 VLM 评估器评估移动任务的 API 成本,显示 Qwen3.6-Plus 在不同场景下均显著低于 GPT-5.4。本文强调,其方法采用代码级评估,无需产生额外费用,因此比基于 VLM 的评估更具可扩展性。结果表明,基于 VLM 的评估成本显著更高,尤其是在大规模应用时,主要受限于高昂的输入与输出 token 成本。在基于 VLM 的评估中,Qwen3.6-Plus 的成本远低于 GPT-5.4。代码级评估零成本,支持可扩展评估。基于 VLM 的评估成本显著更高,尤其在大规模场景下。

本文在 MOBILEGYM-BENCH 基准上评估了多款模型,结果显示所有模型的成功率均随任务难度增加而下降。专有模型表现优于开源模型,其中 Gemini 3.1 Pro 性能最高,尤其在简单任务上表现突出。经过微调的 Qwen3-VL-4B-Instruct 版本展现出显著的成功率提升,特别是在中等难度任务上,并实现了强劲的 sim-to-real 迁移能力,在真机上保留了大部分训练增益。专有模型在所有难度层级上均持续优于开源模型,Gemini 3.1 Pro 位居榜首。对 Qwen3-VL-4B-Instruct 模型进行微调显著提高了成功率,尤其是在 L2 与 L3 任务上,且在真机评估中展现出优异的增益保留率。成功率随任务难度单调递减,最难任务(L4)对所有模型而言仍具挑战性,标志着当前的性能边界。
下表对比了在不同规模下使用不同评估方法对 agent 轨迹进行评估的成本。结果显示,使用 Qwen3.6-Plus 或 GPT-5.4 等 VLM 评估器会产生显著的 API 成本,且成本随轨迹数量增加而上升,而代码级评估器则完全免费。在更大规模下,VLM 评估器的成本大幅攀升,其中 GPT-5.4 的成本显著高于 Qwen3.6-Plus。使用 VLM 评估器会产生随轨迹数量增加的 API 成本,而代码级评估器无此费用。在相同评估规模下,使用 GPT-5.4 的成本远高于 Qwen3.6-Plus。在大规模训练中,VLM 评估器的 API 成本相较于代码级评估成本成为一个重要考量因素。

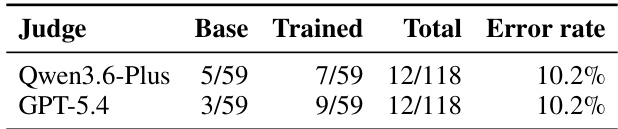
在 sim-to-real 迁移实验中,本文分析了 Qwen3.6-Plus 与 GPT-5.4 两款视觉语言模型在评估真机任务结果时的错误率。两款模型在被评估轨迹上的整体错误率相同,表明尽管内部推理过程存在差异,但误判模式保持一致。错误分析显示,训练后模型的轨迹更为复杂,导致其误判率略高于基础模型,这表明轨迹复杂度的增加可能为 VLM 评估器提供更多误解结果的机会。Qwen3.6-Plus 与 GPT-5.4 在评估真机任务结果时表现出相同的整体错误率。训练后模型的误判率高于基础模型,可能归因于更复杂的轨迹。两款模型均呈现出一致的错误模式,表明这些错误并非模型特有,而是源于评估任务本身。
评估设置在不同任务难度下对比专有模型与开源模型,同时对基于 VLM 的代码级评估方法的可扩展性与可靠性进行基准测试。结果表明,专有模型在性能上始终领先,但针对性的微调与 GUI 专用架构使部分开源模型仍能保持竞争力。成本分析证实,VLM 评估器在大规模应用时成本高昂,而代码级评估则提供了一项免费且高效的替代方案。最后,错误分析揭示,尽管 sim-to-real 迁移能有效保留训练增益,但轨迹复杂度的增加会系统性地引入误判模式,且对所有 VLM 评估器产生同等影响。