Command Palette
Search for a command to run...
ViMU:视频隐喻理解基准测试
ViMU:视频隐喻理解基准测试
Qi Li Xinchao Wang
摘要
任何新兴媒介在诞生之初,其用途便远超单纯传递显性内容。其所承载的信息通常具备双重层级:一是直接呈现的内容,二是潜藏于其下的副文本(subtext)——即创作者试图通过该媒介传达的隐含观点与意图。同样,随着视频技术的广泛普及,视频不仅成为记录和交流视觉信息的有力工具,更成为情感、态度以及往往难以明确表述的社会意义的载体。因此,许多视频的真正含义并不仅局限于画面所呈现的内容;它们往往内嵌于语境、表达风格以及观众的社会经验之中。此类视频副文本的形式多样,有的充满幽默感,有的则蕴含反讽、嘲弄或批判意味。这些隐含的意义在不同的文化背景和社会群体间也可能引发截然不同的解读。然而,现有的大多数视频理解模型仍主要聚焦于字面层面的视觉解析,例如识别物体、动作或时间关系,缺乏对视频中嵌入的隐喻、反讽及社会意义进行系统性理解的能力。
一句话总结
作者提出了 ViMU,这是一个评估视频模型在隐喻、讽刺和社会潜台词方面表现的基准,而非字面视觉理解,旨在解决现有视频理解模型缺乏系统理解隐含意义能力的问题。
核心贡献
- ViMU 被引入作为一个基准,旨在通过关注潜台词理解(包括修辞、社会和文化根基的含义)来评估超越字面感知的视频模型。该基准利用结构化的分类法和无提示提问,要求模型从演变的多模态信号中推断潜在含义。
- 评估结果表明,当前前沿模型在解释隐含意义方面存在显著困难,尽管表面能力强劲,但整体表现低于 50%。这些发现突显了现有视频理解系统在细微社会或文化含义方面的根本局限性。
- 细粒度分析揭示了模型在无需先验解释假设的情况下恢复预期解读时存在的系统性差距和不同的行为模式。这一证据表明,迈向稳健的解释需要在可见内容之外对潜在含义进行建模。
引言
大型多模态模型的近期进展使得视觉定位等任务的视频理解变得有效,但这些系统仍主要局限于表面可见内容。先前的基准通常关注隐含的物理关系或狭窄的幽默现象,并依赖多项选择题格式,无意中揭示了潜台词假设。为了填补这一空白,作者引入了 ViMU,这是一个旨在评估模型能否在没有明确提示的情况下恢复潜在社会潜台词的基准。他们策划了一个包含 588 个视频和 2,352 个问题的高质量数据集,以测试跨多种修辞机制的隐喻理解。
数据集
- 数据集组成与来源
- 作者引入了 ViMU,这是一个包含来自 YouTube、Bilibili 和 TikTok 的 588 个视频的 2,352 个问题的基准。
- 内容通过超过 10 种修辞机制和社会价值信号针对潜台词理解。
- 每个子集的关键细节
- 任务包括开放式解读、修辞和社会信号的多项选择识别以及证据定位。
- 证据来源涵盖视觉帧、可见文本、编辑模式、转录文本和音频语调。
- 目标主体涵盖个人、社会角色、机构和身份群体。
- 所有问题均无提示,以确保模型在没有明确线索的情况下推断含义。
- 模型使用与评估
- 该数据集严格作为评估基准而非训练资源。
- 实验评估模型能否推断隐含含义并将解读定位在多模态证据中。
- 性能指标侧重于语义类别上的开放式准确性和多项选择选择。
- 处理与元数据构建
- 策划遵循涉及多模态证据提取和 LLM 驱动标注的五阶段流程。
- 提取均匀采样的帧和 ASR 转录文本,以将推理定位在可观察信号中。
- 迭代优化循环验证问题质量,最多进行三轮以保持难度。
- 五位人类专家验证最终集,以确保视频自包含且无需外部上下文。
- 细粒度标签被聚合为宏观类别以进行一致评估。
方法
作者利用多阶段流程将原始视频数据转换为经过验证的基准。请参阅框架图以了解整体架构。
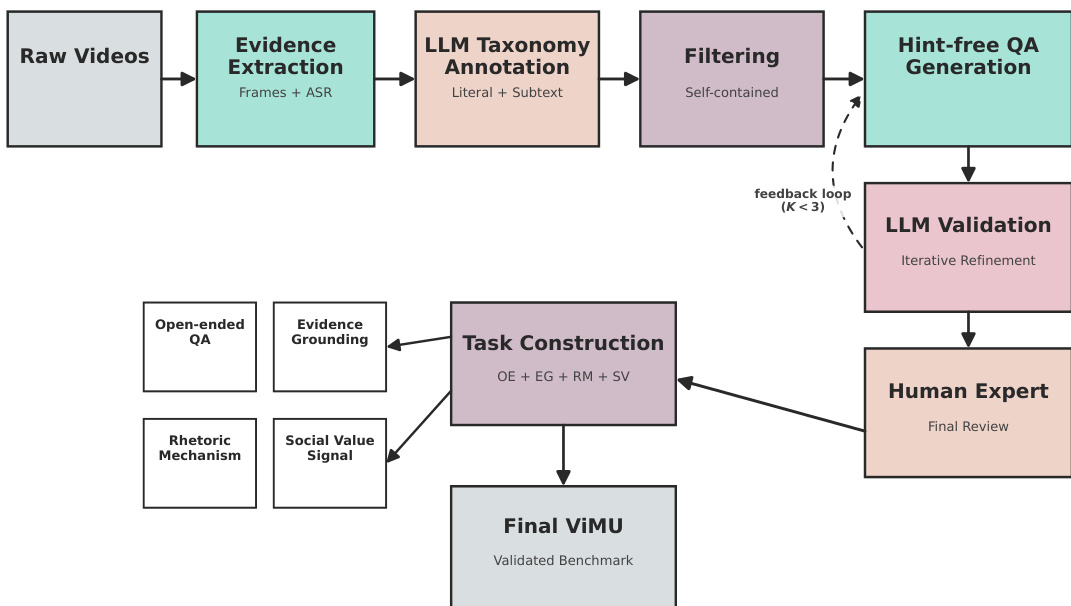
该过程始于原始视频,经过证据提取以收集视觉帧和自动语音识别 (ASR) 转录文本。提取的证据随后由 LLM 分类法标注模块处理,负责根据字面含义和潜台词元素对内容进行分类。标注后,过滤步骤确保内容自包含,然后进行无提示 QA 生成。
为了确保质量,系统采用迭代优化循环。LLM 验证模块审查生成的问题,利用反馈机制允许最多三次迭代 (K<3) 来纠正错误。优化后的数据随后经过人类专家审查以进行最终验证。验证后,数据进入任务构建阶段。此阶段将内容组织为四个不同的任务类别:开放式 QA、证据定位、修辞机制和社会价值信号。
对于结构化潜台词理解任务,特别是修辞机制和社会价值信号识别,作者在两种不同的提示设置下评估模型。无引导设置仅提供任务问题、转录文本、选项和输出规则。相比之下,引导设置补充了五个宏观类别的分类法定义以协助模型。标注期间使用的分类法包括特定类别,如字面/直接,其中视频传达其信息而不使用讽刺或比喻框架,以及对立/不一致,涵盖诱饵转换或角色反转等机制。此外,社会价值引导选项对应于总结视频中表达的更细粒度态度的高级社会价值信号。此流程的最终输出是最终 ViMU 验证基准。
实验
评估在 ViMU 基准上对 16 个多模态大语言模型进行测试,通过零样本测试衡量开放式解读、证据定位以及隐含社会或修辞理解的任务。发现表明,强大的通用视频解读能力并不能保证对隐含立场或编码含义的精确理解,性能在不同模型系列之间差异显著,而非严格区分开放权重和专有模型。此外,错误分析表明,模型主要未能检索完整的支持证据,而非幻觉线索,同时表现出对更安全、字面类别的偏见,而非细微的社会信号。
该表可视化了无引导下的模型选项亲和性偏见,表明模型相对于真实值普遍存在系统性倾向,即过度预测或低估特定选项。正值代表过度预测,负值代表低估,揭示模型在各种架构中一致偏好某些类别(如选项 B),而避免其他类别(如选项 E)。这种模式表明模型在解释社会价值信号方面存在共享偏见,通常默认为情感态度而非细微的意识形态框架。模型对选项 B 表现出强烈的正向偏见,表明倾向于过度选择情感态度。选项 E 存在一致负向偏见,显示模型经常低估身份或意识形态信号。偏见模式在不同模型系列中保持相对稳定,表明处理复杂社会信号存在共同局限性。
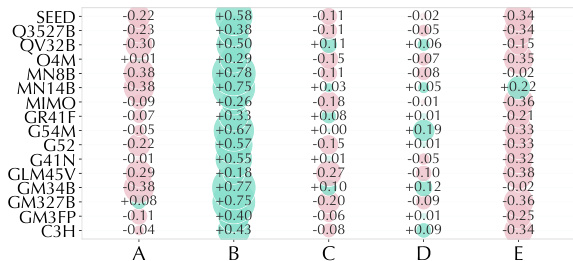
该表显示了五个类别上的模型选项亲和性偏见分数,突出了模型预测中的系统性倾向。它揭示了一种一致的模式,即模型强烈过度预测选项 B,同时低估选项 E。这些结果表明,当前模型默认采用广泛的情感解释,而非捕捉细微或隐含的社会信号。选项 B 显示出强烈的正向偏见,表明几乎所有模型都频繁过度预测。选项 E 一致显示负值,反映了广泛低估该类别的倾向。数据证明了明显的选项级偏见,表明模型在处理特定隐含或基于身份的信号方面存在困难。
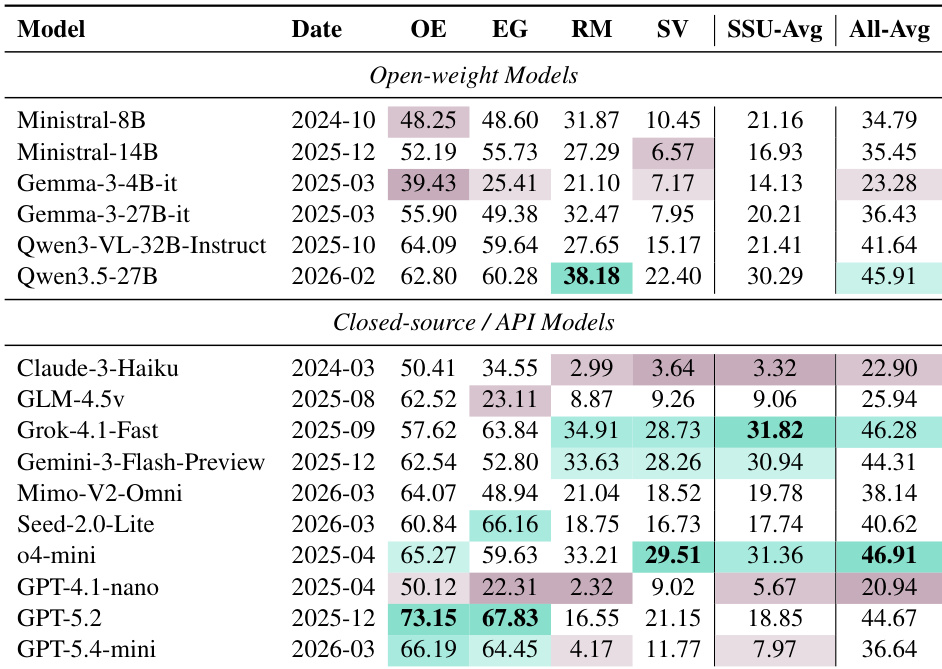
作者在旨在测试隐含视频理解的基准上评估了 16 个多模态语言模型。结果表明存在明显的性能差距,模型在通用开放式解读和证据定位方面表现出色,但在识别特定修辞机制和社会价值信号方面存在显著困难。开放式解读中表现最佳的模型在识别修辞机制或社会价值信号时准确率急剧下降。不同模型系列表现出不同的优势,某些专用模型在结构化潜台词理解任务上优于通用领导者。开放权重模型在与专有模型的竞争中表现出竞争力,某些开源变体实现了比特定闭源对应物更高的整体平均值。
作者分析模型预测的分类法几何结构,以评估模型在证据定位和修辞任务中保留不同类别之间结构关系的程度。结果表明,虽然模型恢复了一些主要的共现模式,但其预测矩阵通常比真实值更平坦且对比度更低,表明未能保留细粒度关系。此外,提供引导引入了这些关系中的系统性局部偏移,但并未相对于真实值一致地提高整体结构保真度。模型捕捉有限的分类法结构,预测矩阵看起来比真实值更平坦且对比度更低。引导机制诱导成对关系中的局部偏移,但未能一致地恢复全局结构保真度。与孤立的感知线索相比,当前模型在恢复结构化多源证据模式方面明显较弱。

作者在 ViMU 基准上评估了 16 个多模态大语言模型,该基准评估开放式解读、证据定位、修辞机制识别和社会价值信号识别。结果突显了显著的性能差距,擅长通用视频解读的模型通常在隐含修辞和社会理解任务上挣扎。此外,分析表明闭源模型并非在所有评估指标上均优于开放权重模型。在开放式解读中表现优异的模型通常在识别修辞机制和社会价值信号时表现出性能急剧下降。结果表明,通用视频理解的前沿能力并不自动转化为对隐含立场或社会编码含义的精确理解。开放权重模型如 Qwen3.5-27B 可以实现比某些闭源模型如 GPT-4.1-nano 和 Claude-3-Haiku 更高的平均分数。
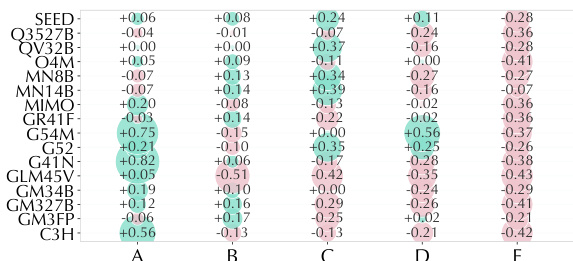
评估在 ViMU 基准上对 16 个多模态语言模型进行测试,揭示模型虽然在通用开放式解读方面表现出色,但在识别特定修辞机制和社会价值信号方面存在显著困难。分析表明存在系统性亲和性偏见,模型过度预测情感态度而低估意识形态信号,即使在应用引导机制的情况下也未能保留细粒度结构关系。此外,开放权重模型在与专有对应物的竞争中表现出竞争力,表明通用视频理解的前沿能力并不自动转化为对隐含立场的精确理解。