Command Palette
Search for a command to run...
面向鲁棒多视图三维重建的几何感知表征去噪
面向鲁棒多视图三维重建的几何感知表征去噪
摘要
随着前馈式3D重建模型的问世,多视图3D重建已取得显著进展。然而,这些模型通常是在理想且无退化的成像条件下进行训练和评估的,而实际观测数据往往包含与这些设定显著不同的退化现象。因此,提升退化条件下多视图3D重建的鲁棒性仍然是一个重要的挑战。我们提出了几何感知表示去噪(GARD)框架,该新颖框架直接在基于前馈的3D重建模型的特征空间中执行基于扩散的多视图恢复。该设计利用了3D重建器的几何感知特征表示,以有效恢复准确的场景几何结构。此外,通过引入额外的RGB图像解码器,优化后的表示还可用于恢复高质量RGB图像,从而实现3D场景几何与高质量图像的同时恢复。在Depth Anything 3(DA3)基准上的综合实验证明了所提出的GARD框架的有效性。
一句话总结
几何感知表示去噪(GARD)是一种基于扩散的框架,它直接在预前向3D重建模型的特征空间中进行多视图恢复,利用几何感知表示和辅助RGB解码器,在真实世界退化条件下实现鲁棒的场景重建。
核心贡献
- 本文提出了几何感知表示去噪(GARD),这是一种基于扩散的框架,直接在预前向3D重建模型的特征空间中进行多视图恢复,而非在标准的像素空间或VAE潜在空间中进行。
- 该方法利用重建器的几何感知表示,在去噪过程中保持跨视图一致性和细粒度结构细节,从而避免压缩潜在表示带来的信息瓶颈。
- 集成的RGB图像解码器将优化后的几何特征还原为清晰的多视图图像,使模型能够在相机运动模糊等真实世界退化条件下实现鲁棒的3D几何恢复。
引言
多视图3D重建将2D观测数据转化为精确的场景几何结构,为自主导航、机器人技术和增强现实等关键应用提供了支持。尽管现代预前向Transformer模型简化了这一流程,但在处理受运动模糊影响的真实世界图像时,其性能会显著下降。运动模糊会掩盖细微纹理并破坏跨视图的几何一致性。先前的恢复策略难以弥补这些缺陷,因为单视图图像空间方法忽略了多视图之间的关联,而基于VAE的压缩潜在空间则会形成信息瓶颈,导致结构细节丢失。作者提出了一种名为GARD的基于扩散的去噪框架,该框架直接在现有重建模型的高维几何感知特征空间中运行。通过对这些结构化表示进行优化,并将其路由至辅助解码器,该方法能够同时恢复高质量图像,并在所有视角下保持精确的3D几何结构。
方法
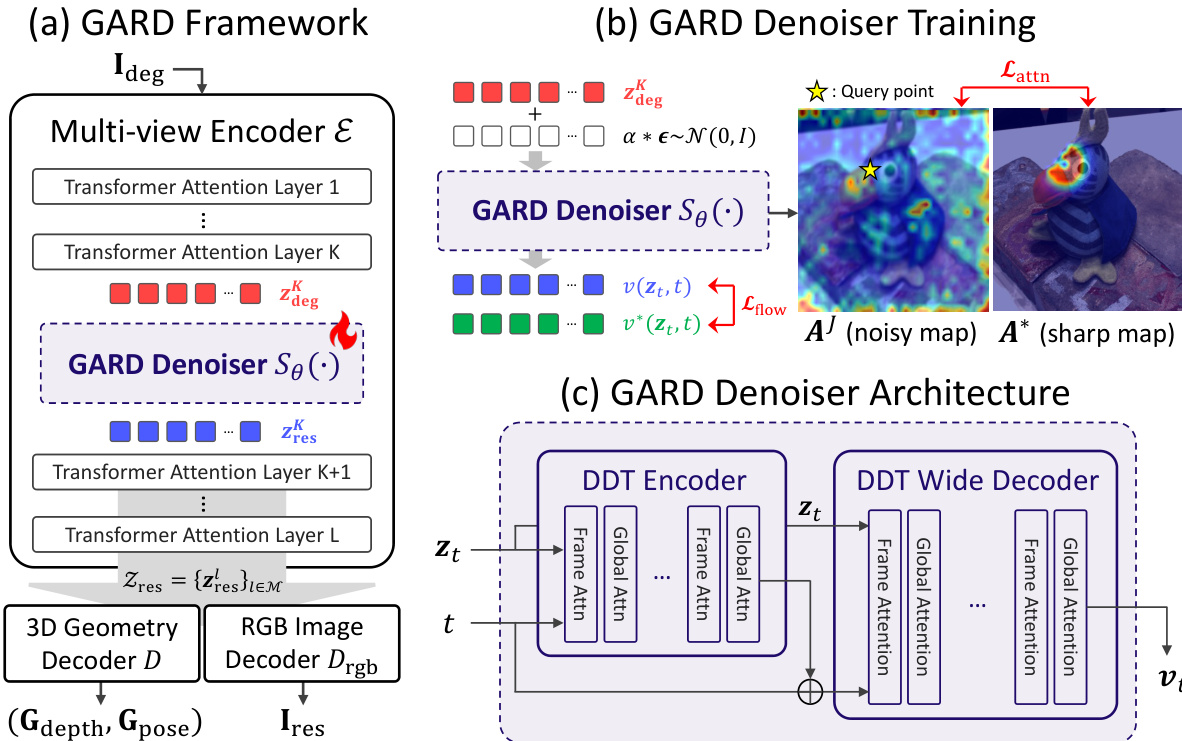
作者提出了几何感知表示去噪(GARD),这是一种专为在预训练预前向3D重建模型的几何感知特征空间内直接执行多视图图像恢复而设计的框架。该方法与传统的像素空间恢复方法形成对比。传统方法通常先对图像进行去噪,再将其输入重建器,这种方式无法利用多视图一致性,且可能引入视图相关的伪影。GARD框架的核心是一个去噪器 Sθ(⋅),它在重建器的多视图编码器 F(⋅) 生成的中间特征表示上运行,而非直接作用于原始图像。如下图所示,该框架将退化的多视图图像作为输入,并通过编码器处理,在特定层生成退化的特征表示 zdegK。GARD去噪器在此层介入,将特征表示优化为 zresK,随后将其传递至剩余的编码器层。恢复后的特征 Zres 随后由几何解码器和RGB图像解码器进行解码,生成最终输出:恢复后的图像和估计的3D场景几何结构。该设计使得模型能够在单次前向传播中同时恢复视觉和几何信息,且无需重新训练底层骨干网络。

GARD去噪器 Sθ(⋅) 被实现为一个多视图潜在扩散模型,具体基于表示自编码器(RAEs)中的 DiTDH 架构构建。其架构如下文图所示,由一个DDT编码器和一个DDT宽解码器组成。该模型通过交错的全局注意力层进行了增强,从而支持多视图建模。帧级注意力负责捕捉每个视图内的局部空间结构,而全局注意力则促进跨视图上下文信息的聚合,使模型能够利用跨视图对应关系并强制保持几何一致性。该去噪器采用插值流匹配损失与注意力对齐损失的组合进行训练。流匹配损失在噪声扰动的源分布上进行优化,通过预测速度场,促使模型学习从退化特征到干净特征的映射。注意力对齐损失对此进行了补充,该损失对去噪器的全局注意力图进行正则化,使其与从干净输入数据推导出的目标对应图对齐,从而促进更清晰且连贯的注意力模式。
实验
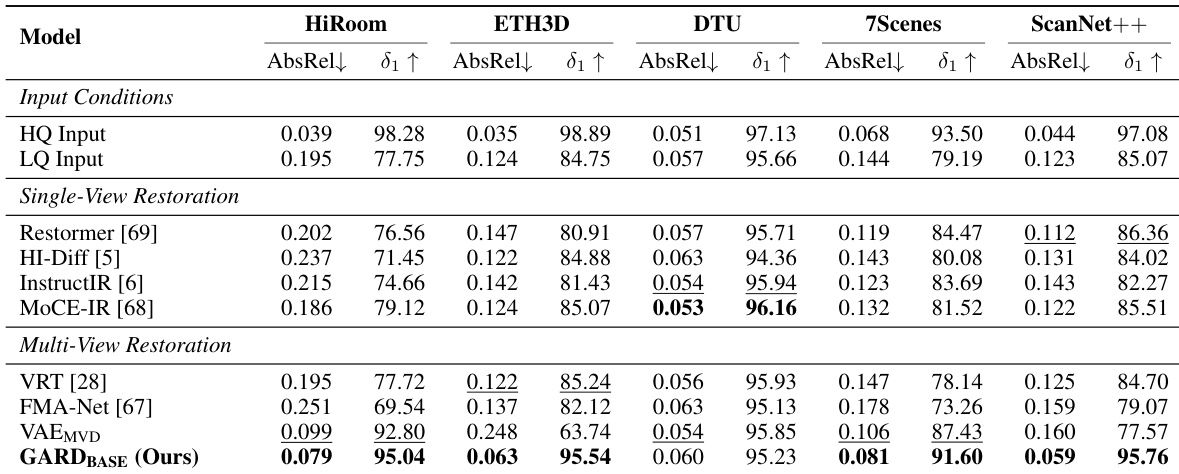
实验在严重运动模糊退化条件下,将提出的GARD方法与多种单视图、多视图及视频恢复基线进行了对比,验证了其在相机位姿估计、三维场景重建和图像恢复方面的有效性。该方法直接在几何感知特征空间内运行,而非依赖压缩的潜在表示或孤立的单视图处理,成功保留了基线方法无法维持的跨视图一致性、结构保真度和细微几何细节。消融实验进一步证实,将插值流匹配与注意力对齐相结合能显著增强对应关系学习,而使用额外的输入视图则能持续改善几何恢复效果。总体而言,结果表明将特征空间去噪与前馈重建器相结合,为恢复退化多视图环境提供了一种鲁棒且准确的解决方案。
作者在严重退化条件下将所提方法与多种恢复和重建基线进行了对比,重点评估相机位姿估计和3D重建性能。结果表明,该方法在几何感知特征空间内运行,优于单视图和多视图恢复方法,实现了更高的位姿估计精度和更一致的3D重建结果。在严重退化条件下,所提方法相比单视图和多视图恢复基线,在相机位姿估计精度上表现更优。该方法在3D重建质量上优于现有方法,能够生成几何一致性更强且更完整的重建结果。增加输入视图数量持续提升了位姿估计和重建性能,表明更丰富的多视图信息具有显著优势。
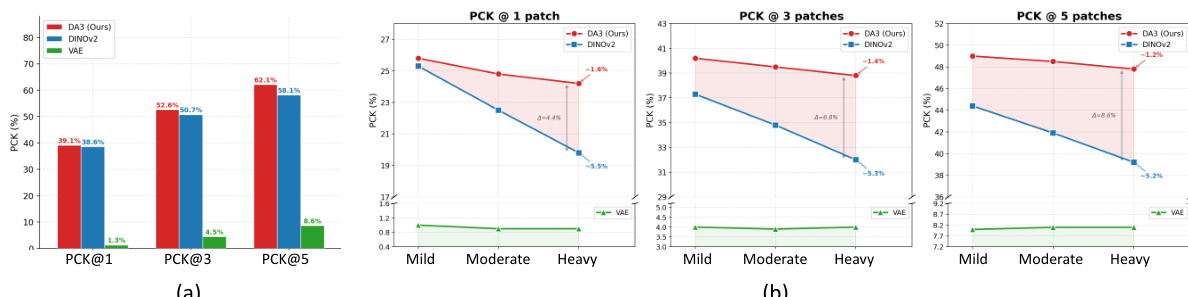
作者在严重运动模糊退化条件下,将所提方法与多种单视图和多视图恢复方法进行了对比,用于相机位姿估计。结果表明,所提方法在多个基准测试中均优于所有基线,通过利用几何感知特征空间去噪,实现了最高的位姿估计和重建精度。该方法在单视图和多视图恢复方法上展现出一致的改进,特别是在保持结构保真度和跨视图一致性方面。与单视图和多视图恢复基线相比,所提方法在所有基准测试的相机位姿估计中均取得了最佳性能。该方法直接在几何感知特征空间内运行,优于现有的多视图恢复方法,有效提升了结构保真度和跨视图一致性。结果表明,增加输入视图数量能够同时改善位姿估计和3D重建质量,凸显了丰富跨视图信息的价值。
作者对GARD去噪器进行了消融实验,评估了其训练组件和输入视图数量的影响。结果表明,将插值流匹配与注意力对齐相结合可提升不同基准测试的性能,而增加输入视图数量则能持续增强位姿估计和3D重建精度。与单独使用任一组件相比,结合插值流匹配与注意力对齐能够进一步提升性能。使用更多输入视图可带来更优的相机位姿估计和3D重建质量。完整的GARD模型配置在所有评估基准中均取得了最佳结果。
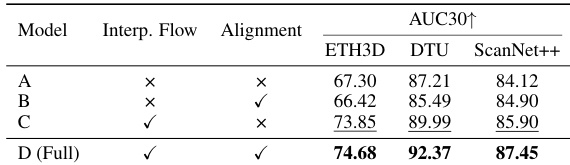
作者在严重运动模糊背景下,将提出的GARD方法与单视图和多视图恢复基线进行了对比,应用于相机位姿估计和3D重建。结果表明,GARD在多个基准测试中均优于所有基线,在保持几何一致性和结构保真度方面展现出卓越性能。消融实验进一步证实了GARD框架中关键组件的有效性,以及使用更多输入视图的优势。与单视图和多视图恢复基线相比,GARD在所有基准测试的相机位姿估计和3D重建中均取得了最佳性能。所提方法优于现有的多视图恢复方法,尤其在严重退化条件下保持几何一致性和结构保真度方面表现突出。消融研究表明,使用更多输入视图能够同时改善位姿估计和重建质量,凸显了丰富跨视图信息的价值。
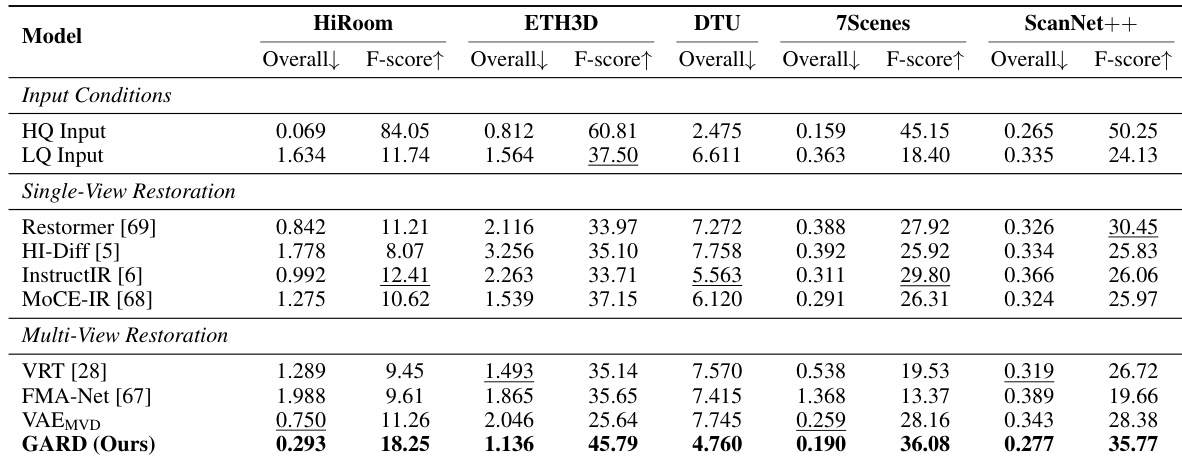
作者在严重退化条件下,将所提方法应用于相机位姿估计任务,并与多种单视图和多视图恢复基线进行了对比。结果表明,所提方法在多个基准测试中均优于所有基线。与单视图和基于VAE的多视图方法相比,其在位姿精度和重建质量上实现了显著提升。该方法通过在保留结构保真度和跨视图一致性的几何感知特征空间内运行,实现了卓越的性能。在多个基准测试的相机位姿估计任务中,所提方法均优于所有单视图和多视图恢复基线。该方法取得了优于基于VAE的多视图恢复方法的结果,后者因压缩潜在空间的信息丢失而受限。单视图恢复模型由于无法利用多视图输入之间的互补信息,其性能提升较为有限。
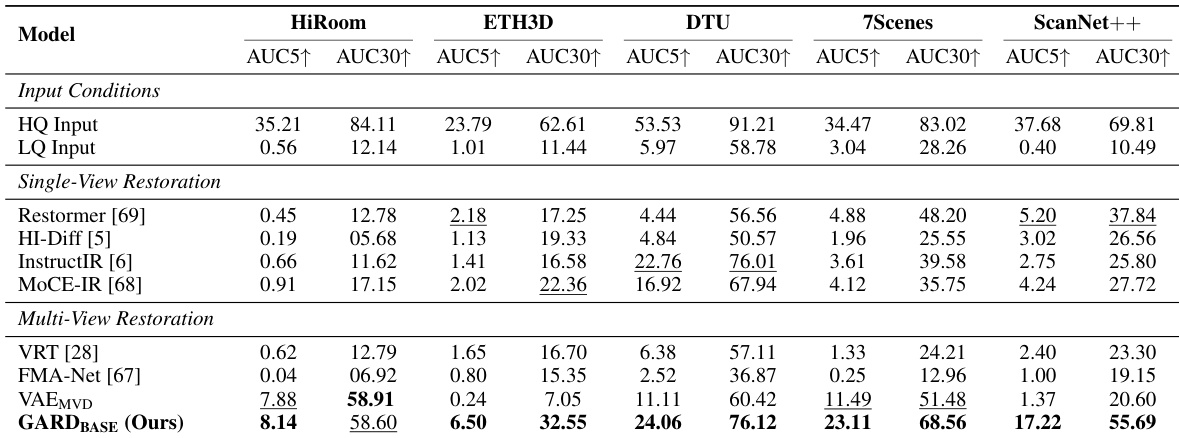
作者在严重运动模糊退化条件下,将所提方法应用于相机位姿估计和3D重建,并与单视图和多视图恢复基线进行了对比。该方法通过在保留结构保真度和跨视图一致性的几何感知特征空间内运行,持续优于现有技术。消融实验同时证实,结合插值流匹配与注意力对齐能够取得最优结果。此外,利用额外的输入视图能够可靠地提升重建质量,表明该方法成功克服了基于VAE方法的信息丢失局限以及单视图模型固有的约束。