Command Palette
Search for a command to run...
Agent探索性策略优化用于多模态Agent推理
Agent探索性策略优化用于多模态Agent推理
Minki Kang Shizhe Diao Ryo Hachiuma Sung Ju Hwang Pavlo Molchanov Yu-Chiang Frank Wang Byung-Kwan Lee
摘要
具备扩展推理能力的视觉语言模型在复杂问题上表现优异,但许多现实世界的问题需要借助外部工具,仅靠内部推理往往难以解决。因此,智能体推理将两种具有结构不对称性的行为交织在一起:思考(作为自包含的默认行为)与工具使用(作为一种高方差的辅助动作)。我们将这种不对称性称为“思考-行动差距”(Thinking-Acting Gap)。在GRPO等标准强化学习(RL)训练策略下,该差距在训练过程中表现为两种诊断性症状:工具使用仅在约30%的rollout中被尝试,且当尝试时,组内使用工具的rollout在约40%的问题上全部错误,从而抑制了本应在所需工具调用处获得的学习信号。我们提出了AXPO(Agent eXplorative Policy Optimization):针对每个全部错误的工具使用子组,AXPO会固定思考前缀,并对工具调用及其后续内容进行重采样,同时结合基于不确定性的前缀选择策略。在九个多模态基准测试以及Qwen3-VL-Thinking的三个规模上,SFT+AXPO的平均表现优于SFT+GRPO(在8B规模上平均提升+1.8pp的Pass@1和+1.8pp的Pass@4),且8B规模的SFT+AXPO在Pass@4指标上超越了32B Base模型,同时参数量仅为原来的四分之一。
一句话总结
AXPO(Agent eXplorative Policy Optimization)通过固定思维前缀并结合基于不确定性的前缀选择对工具调用进行重采样,解决了多模态 Agent 推理中的“思考-行动”鸿沟(Thinking-Acting Gap)。这使得采用 SFT + AXPO 训练的 8B Qwen3-VL-Thinking 模型在九个基准测试上的 Pass@1 和 Pass@4 平均得分比 SFT + GRPO 高出 1.8 个百分点,并在 Pass@4 指标上以四分之一的参数量超越了 32B 基础模型。
核心贡献
- AXPO(Agent eXplorative Policy Optimization)通过识别全部错误的工具使用子组,并在冻结前置推理前缀的同时对其工具调用及后续内容进行重采样,解决了 Agent 视觉语言模型中的“思考-行动”鸿沟。
- 该机制直接在工具调用边界处运行,而非在工具观测之后,从而恢复了标准组相对策略优化在均匀采样过程中通常会丢失的受抑制学习信号。
- 在 Qwen3-VL-Thinking 模型上的九个多模态基准测试表明,将监督微调与 AXPO 结合使用,可在 8B 规模下使平均 Pass@1 和 Pass@4 得分提升 1.8 个百分点,并使 8B 模型在 Pass@4 指标上以四分之一的参数量超越 32B 基础模型。
引言
具备扩展推理能力的视觉语言模型已取得显著进展,但实际应用场景通常需要借助外部工具进行实时数据检索、复杂计算和细粒度视觉分析。多模态 Agent 推理通过将内部思维过程与工具执行交替进行来满足这一需求,但标准后训练流程难以应对一种被称为“思考-行动”鸿沟的结构化不对称问题。在 GRPO 等常规强化学习方法下,工具调用依然罕见且波动极大,经常导致整个 rollout 组失败,并在模型亟需提升行动能力时有效抹除了学习信号。为突破这一瓶颈,本文采用 AXPO(Agent eXplorative Policy Optimization),这是一种定向框架,能够锚定成功的思维前缀,并在轨迹失败时仅对高方差的工具调用及其后续内容进行重采样。AXPO 将探索精确集中在工具调用边界,并应用基于不确定性的前缀选择机制,从而恢复稳健的行动学习信号,在多模态基准测试中实现显著的性能提升,同时超越参数量大得多的基线模型。
数据集
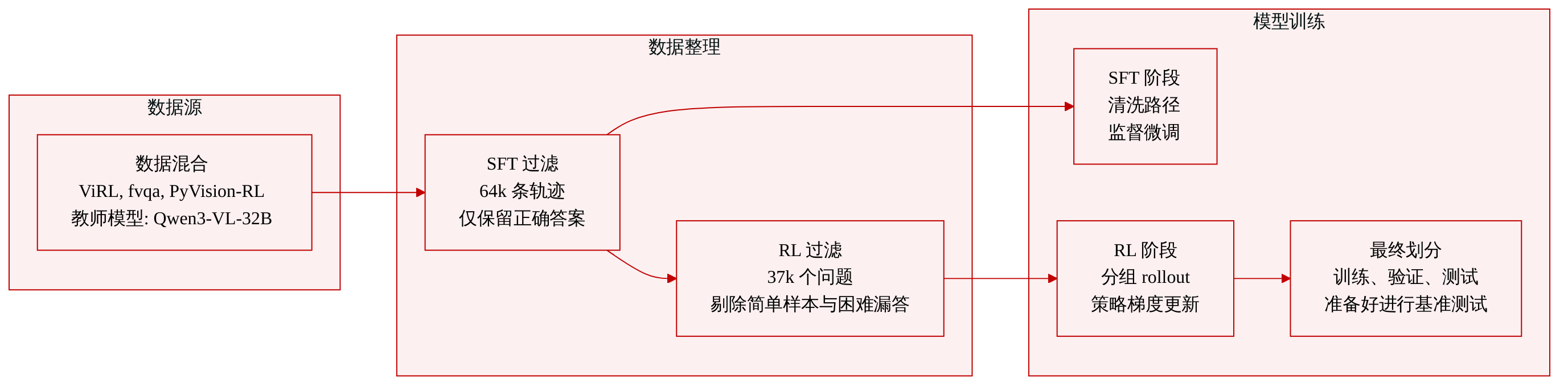
• 数据集构成与来源: 训练语料库通过整合三个成熟数据集中的轨迹构建而成,分别为 ViRL、fvqa 和 PyVision-RL。所有初始轨迹均使用 Qwen3-VL-32B-Thinking 模型作为教师模型进行合成。
• 子集详情:
- 监督微调(SFT)数据:共 64,274 条轨迹。约 25% 的轨迹包含至少一次工具调用,其余 75% 完全依赖内部推理。本文应用严格的正确性过滤机制,仅保留与真实标签对比得出最终正确答案的轨迹。
- 强化学习数据:约 37,000 道题目。该子集将 15,591 道从 SFT 池中筛选出的题目与来自 MMFinetReason-hard 的 22,000 道额外难题相结合。本文移除了在四次 rollout 中均被监督检查点完美解决的 SFT 题目,以及教师模型在四次 rollout 中均失败的问题,从而有效剔除 trivial(简单)与 unreachable(不可达)任务。
• 训练用途与处理: 清洗后的 SFT 轨迹构成初始训练集。随后转入强化学习阶段,策略模型针对每道题目生成最多三轮交互,每组问题包含八个 rollout。数据通过 verl 和 rllm 库进行路由,以应用策略梯度更新,并采用非对称裁剪范围与固定参考策略进行 KL 正则化。
• 其他处理说明: 所提供的文档未详细说明具体的图像裁剪方法或自定义元数据模式。本文主要依赖轨迹长度限制、基于 rollout 的采样以及答案验证来构建和验证训练数据。
方法
本文提出 AXPO,一种专为解决基于组的 Agent 推理中“思考-行动”鸿沟而设计的强化学习算法。在该场景中,工具使用尝试不足,且使用工具的子组经常完全失败,导致 tool-call tokens 的优势值非正。该框架基于标准的组相对策略优化(GRPO)流程构建,该流程训练视觉语言模型(VLM)策略 πθ 生成思维片段、工具调用与观测值的序列,最终得出答案。在 GRPO 中,每个输入采样一批包含 N 个 rollout 的样本,组内奖励经过归一化以计算优势值,随后通过 PPO-clip 代理目标更新策略。
AXPO 的核心创新在于工具调用重采样,该方法通过将对探索的注意力集中在确认工具调用之后的后续内容上,针对工具使用行为训练不足的问题进行优化。具体实现方式为固定一个已跨越工具调用边界的思维前缀 t1src,确保所有后续生成的内容在结构上均包含工具调用。基于该固定前缀,从策略 πθ(⋅∣x,t1src) 中抽取 K 个后续内容进行执行并向后推进 rollout。每个重采样的轨迹均与源 rollout 共享相同的前缀,从而将随机性集中于工具调用及其直接后续阶段。该方法在恢复正确的工具使用 rollout 方面被证明优于标准采样,因为它消除了在非工具 rollout 上采样的资源浪费,而这正是 GRPO 中扩展 N 规模时的关键局限性。
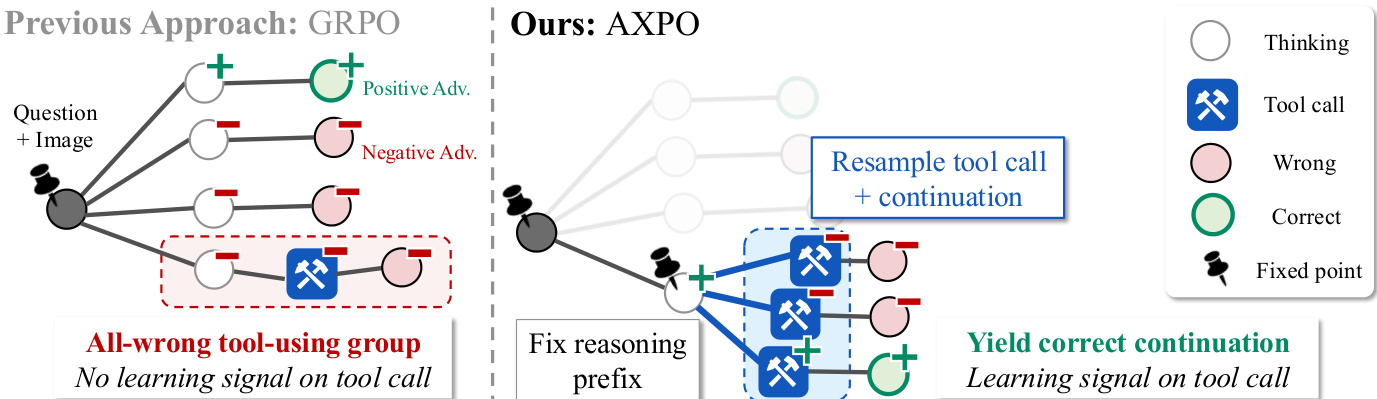
如图所示,AXPO 仅作用于工具使用子组非空且完全错误的组,这类组被识别为非正优势值的主要来源。这确保了重采样机制被应用于能产生最大梯度提升的位置。为控制计算成本,AXPO 将每步的额外重采样预算上限设置为 r⋅BN,实践中 r=0.25,并按广度优先策略向所有触发问题的组分配资源。在这些组内,候选前缀根据其不确定性进行排序,该不确定性通过源 rollout 中分配给 tool-call tokens 的平均策略概率来衡量。这一置信度代理指标是预测熵的可处理替代方案,使 AXPO 能够优先重采样不确定性最高的前缀,因为它们更有可能包含正确的后续内容。
AXPO 的优势值计算旨在避免由共享前缀引发的梯度冲突。对于每个选定的前缀,K 个重采样的后续内容构成一个独立的优势组,其 per-token advantages A^kres 基于组归一化奖励进行计算。这些优势值仅应用于 continuation tokens,prefix tokens 被掩码处理。源轨迹的 prefix tokens 通过独立的恢复奖励 rprefix 进行更新,若至少一个重采样的后续内容正确则为 1,否则为 0。该恢复奖励在组归一化过程中替换原始源 rollout 的奖励,从而生成应用于 prefix tokens 的逐前缀优势值 A^prefix。该机制确保只要重采样成功,前缀即可获得正向奖励,从而将覆盖范围的增益转化为强化梯度信号。选定前缀的最终 AXPO 损失函数结合了源前缀与重采样后续内容的裁剪代理损失。
实验
评估环节在九个多模态基准测试上采用 Qwen3-VL 模型,以检验 Agent 在推理、感知与搜索任务中的工具使用能力。主实验验证了 AXPO 通过在强化学习过程中动态重采样工具调用,有效弥合“思考-行动”鸿沟,从而维持工具使用率并从初始失败的推理前缀中恢复正确轨迹。消融实验与对比分析证实,这些性能提升源于计算资源的战略性分配与精确的优势值计算,而非增加 rollout 预算或奖励塑形。最终,该方法通过同步扩展策略可到达的正确轨迹范围并提升条件性工具使用可靠性,使较小规模的模型能够匹配甚至超越较大的基线模型。
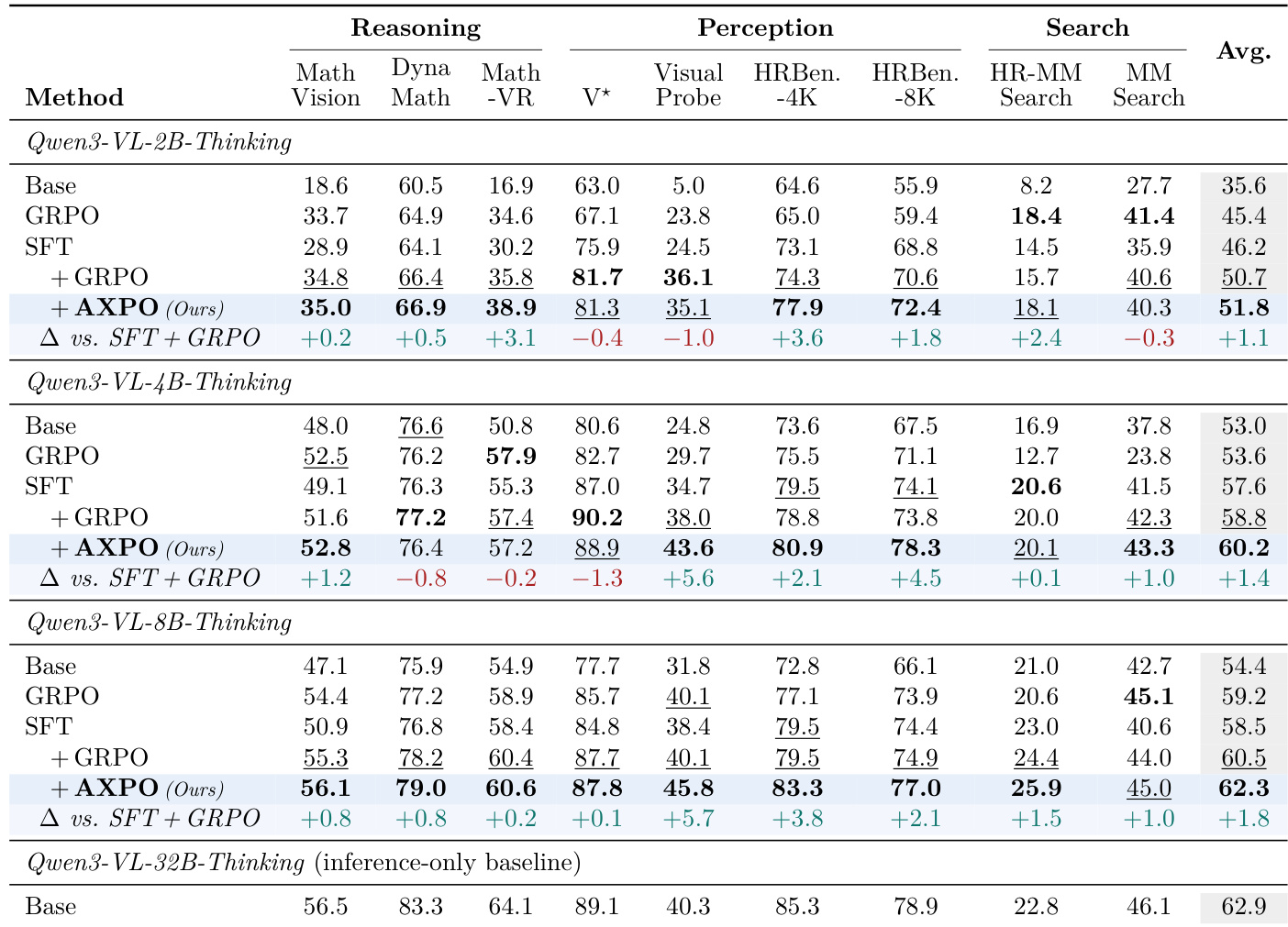
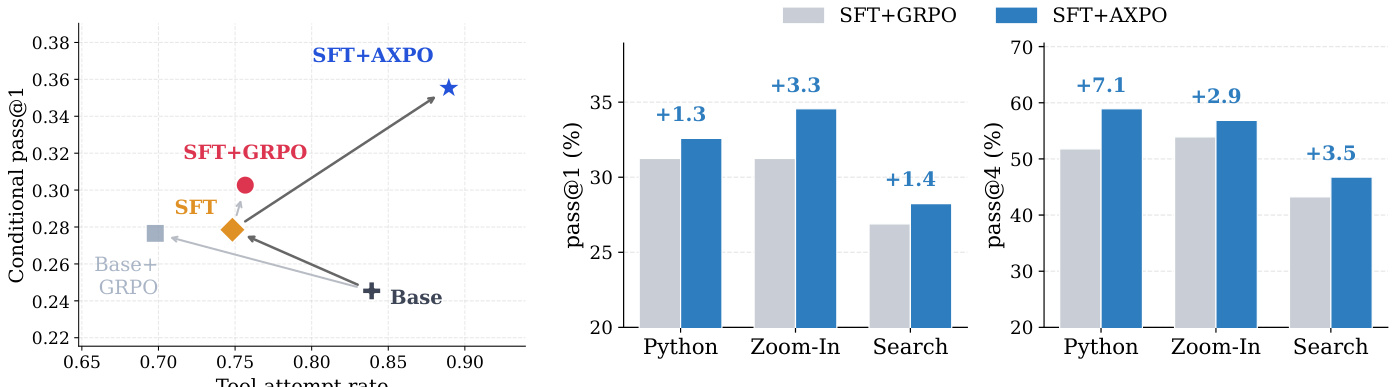
本文在多种模型规模与基准测试上评估了 AXPO 方法的性能,并与多个基线方法进行对比,重点关注多模态推理、感知与搜索任务。结果表明,AXPO 在各项指标上均稳定优于 SFT + GRPO,尤其在感知任务中表现突出,同时在工具使用频率与正确性方面均实现提升。该方法通过提高工具利用率并降低训练期间全部错误工具使用子组的频率,有效解决了“思考-行动”鸿沟问题。AXPO 在所有模型规模上均优于 SFT + GRPO,其中在感知任务与 Pass@4 指标上的提升最为显著。AXPO 提高了工具使用频率并降低了工具使用子组的完全错误率,表明模型在 tool-call 上的学习信号得到改善。该方法优于其他强化学习训练配方,消融实验表明 AXPO 的所有组件对其性能提升均不可或缺。
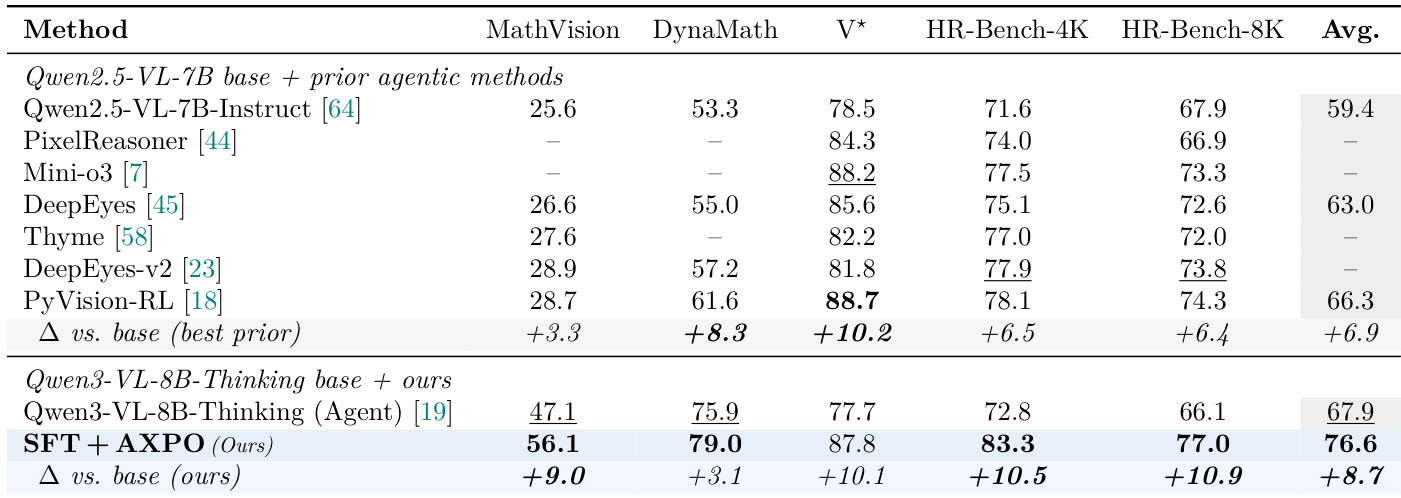
本文在五个基准测试上将所提出的 AXPO 方法与既往的 Agent VLM 系统进行对比,结果显示 AXPO 在五个基准中的四个以及全部基准的平均得分上均取得更高性能。结果表明,AXPO 的性能超越以往方法,尤其在图像数学任务中表现优异,且相较于其基线模型的提升幅度大于既往方法对其基线的提升幅度。AXPO 在五个基准中的四个及整体平均分上均优于既往 Agent VLM 系统。相较于基线模型,AXPO 取得的提升幅度大于既往方法对其基线的提升。AXPO 在图像数学基准上表现尤为出色,而既往方法在该领域的投入相对较少。
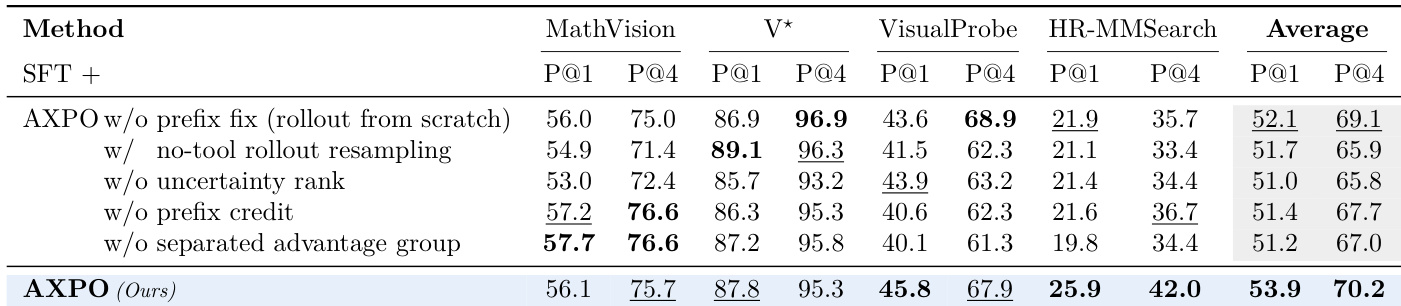
本文开展消融实验,以评估 AXPO 方法中各个独立组件对多基准测试下模型性能的影响。结果表明,移除任何关键设计元素(包括前缀固定、基于不确定性的前缀选择、前缀奖励分配或独立优势分组)均会导致性能持续下降,这表明每个组件都对方法的整体有效性有所贡献。完整的 AXPO 方法在所有评估指标上均取得最高分数,证明整合这些组件对于实现最优性能至关重要。移除 AXPO 的任何组件均会导致所有基准测试中的性能出现可测量的下降。完整的 AXPO 方法优于所有消融变体,凸显了其集成设计的重要性。各消融变体的得分均低于完整方法,表明所有组件对达成最优结果均必不可少。
本文在多个基准测试上对比了 SFT+AXPO 与 SFT+GRPO 及其他基线方法,结果表明 AXPO 同时提升了工具使用频率与工具使用轨迹的质量。结果显示,在所有模型规模下,AXPO 在 Pass@1 和 Pass@4 指标上均稳定优于 SFT+GRPO,性能提升主要集中在工具使用至关重要的感知任务中。该方法通过增加工具使用并降低训练期间全部错误工具使用子组的频率,有效缩小了“思考-行动”鸿沟。相较于 SFT+GRPO,AXPO 在工具使用频率与轨迹质量上均实现改善。AXPO 在所有模型规模下均取得更高的 Pass@1 与 Pass@4 分数,其中在感知任务中的提升最为显著。AXPO 降低了工具使用子组的完全错误率,并在训练期间提高了工具使用率,从而扭转了“思考-行动”鸿沟的典型症状。
{"summary": "本文评估了一种名为 AXPO 的方法,该方法通过重采样工具调用以解决“思考-行动”鸿沟,从而增强 Agent 推理中的强化学习性能。结果表明,AXPO 通过提高工具使用频率并纠正工具使用子组中的失败情况,在多个基准测试上提升了性能,尤其在感知任务中表现突出。该方法优于基线方法与其他训练配方,其性能提升主要源于对未充分探索的工具调用轨迹实现了更好的覆盖。", "highlights": ["AXPO 提高了训练期间的工具使用频率,并纠正了工具使用子组中的失败情况,从而在各基准测试中实现性能提升。", "AXPO 优于 SFT + GRPO 及其他强化学习配方,性能提升主要集中在工具使用至关重要的感知任务中。", "消融实验证实 AXPO 的所有组件均对性能有所贡献,特别是在工具调用边界处的重采样与优势分组机制。"]}
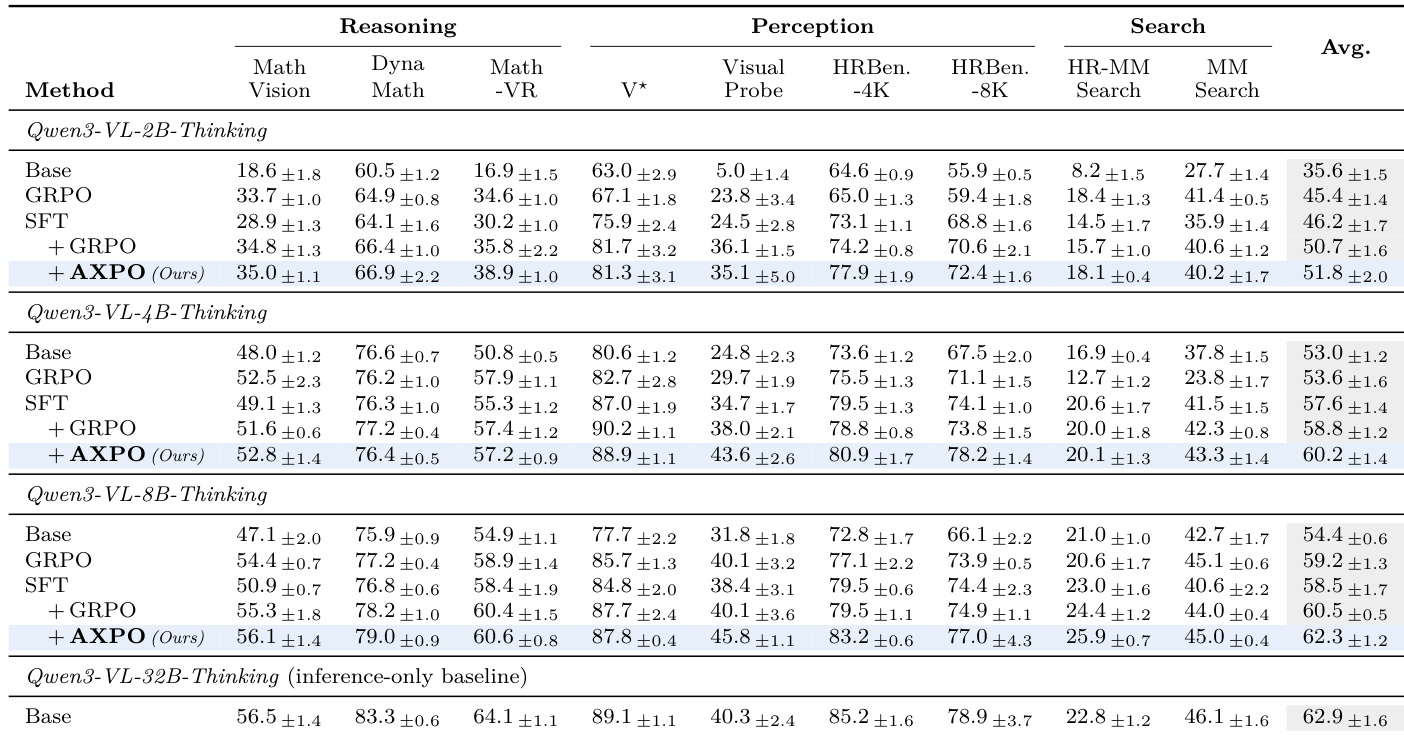
本文在涵盖多模态推理、感知与搜索任务的多种模型规模与基准测试上,将 AXPO 与结合强化学习的监督微调及既往 Agent 视觉语言模型进行对比评估。实验验证了 AXPO 通过提升有意义的工具利用率并纠正 agent 轨迹中的失败模式,有效弥合了“思考-行动”鸿沟。对比结果一致表明该方法性能优于现有方案,尤其在感知与图像数学领域实现了显著的定性提升。消融实验进一步证实所有设计组件均不可或缺,因为移除任何元素均会导致所有评估任务中出现一致的性能下降。