HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

用于自动研究的 AI:路线图与用户指南
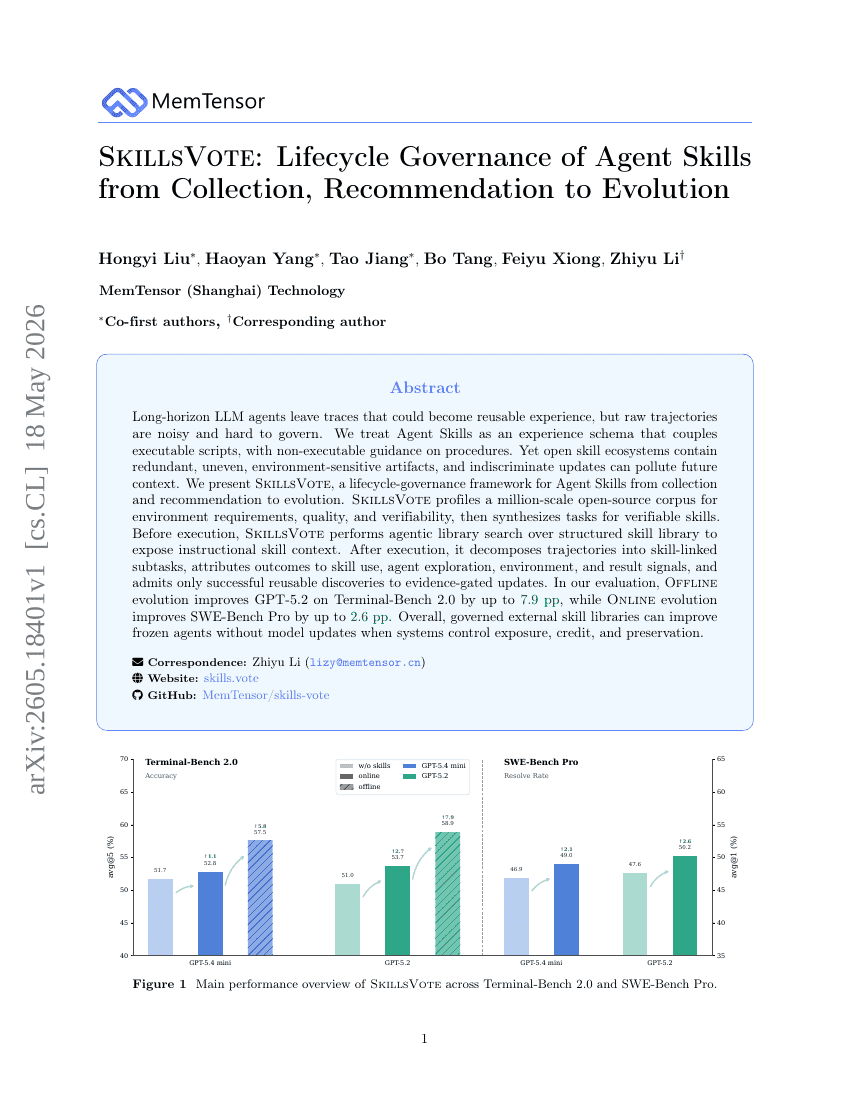
SkillsVote:从收集、推荐到演进的 Agent 技能生命周期治理

























用于自动研究的 AI:路线图与用户指南
SkillsVote:从收集、推荐到演进的 Agent 技能生命周期治理
Lance:通过多任务协同实现统一的多模态建模
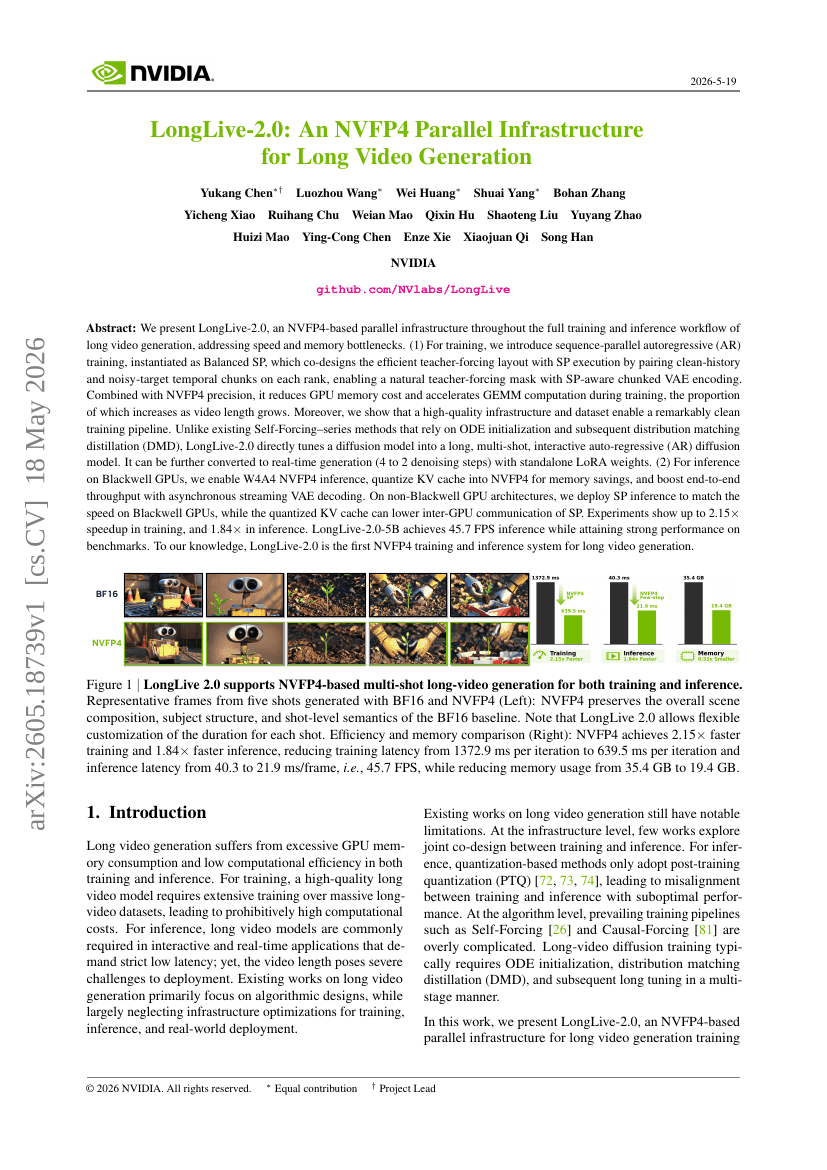
LongLive-2.0:用于长视频生成的NVFP4并行基础设施
切片与切块:配置最优专家混合物
智能体驱动的网络架构发现:AIRA-Compose 与 AIRA-Design
学习预见:揭示在线策略蒸馏的解锁效率
DexJoCo:面向 MuJoCo 上手操作的任务导向基准与工具包
FashionChameleon:迈向实时且可交互的人-服装视频定制
CiteVQA:用于可信文档智能的证据归因基准测试
MMSkills:迈向通用视觉 Agent 的多模态技能
PhysBrain 1.0 技术报告
将价值模型重新引入:大语言模型强化学习中的生成式批判家用于价值建模
NEXUS:一种用于时间序列预测的智能体框架
MemEye:面向多模态 Agent 记忆的以视觉为中心的评价框架
SANA-WM:基于混合线性扩散Transformer的高效分钟级世界模型
MemLens:大视觉-语言模型中多模态长期记忆的基准测试
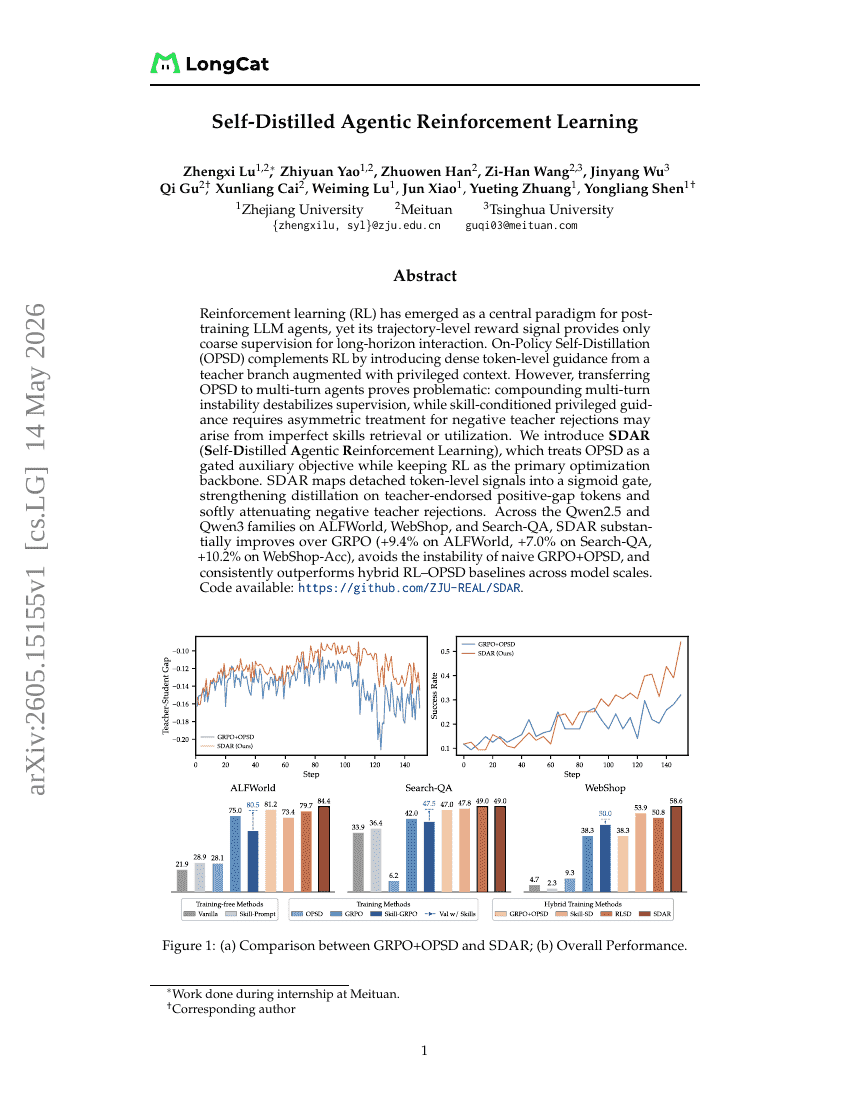
自蒸馏式 Agent 强化学习
因果强制++:用于实时交互式视频生成的可扩展少步自回归扩散蒸馏
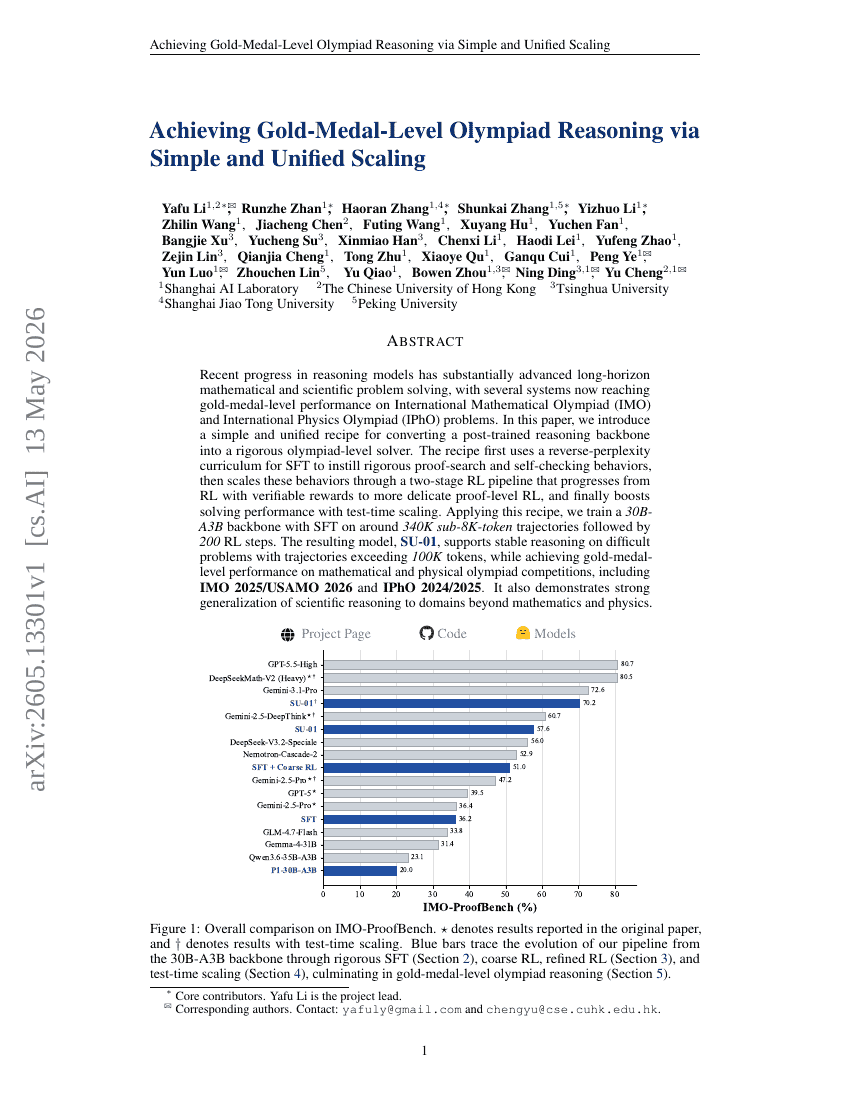
通过简单且统一的缩放实现金牌级奥林匹克推理
RepoZero:大语言模型能否从零开始生成代码仓库?
Qwen-Image-VAE-2.0 技术报告
通过文本-表格建模从有限交互中预测 AI Agent 的决策
高效训练长上下文视觉语言模型:实现超越 128K 上下文的泛化能力
AnyFlow:具有在线策略流映射蒸馏的任意步视频扩散模型
MinT:用于训练和服务数百万大语言模型的托管基础设施
MulTaBench:基于文本和图像的多模态表格学习基准测试
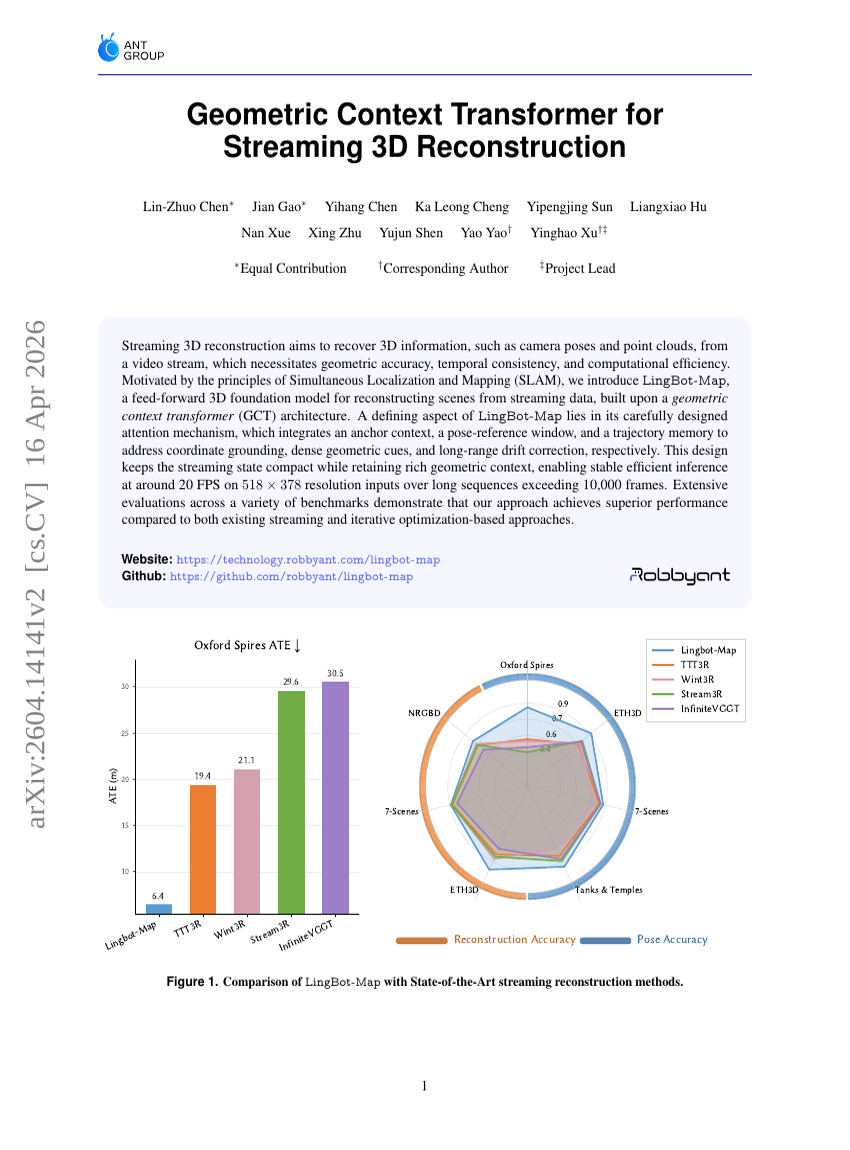
面向流式3D重建的几何上下文Transformer
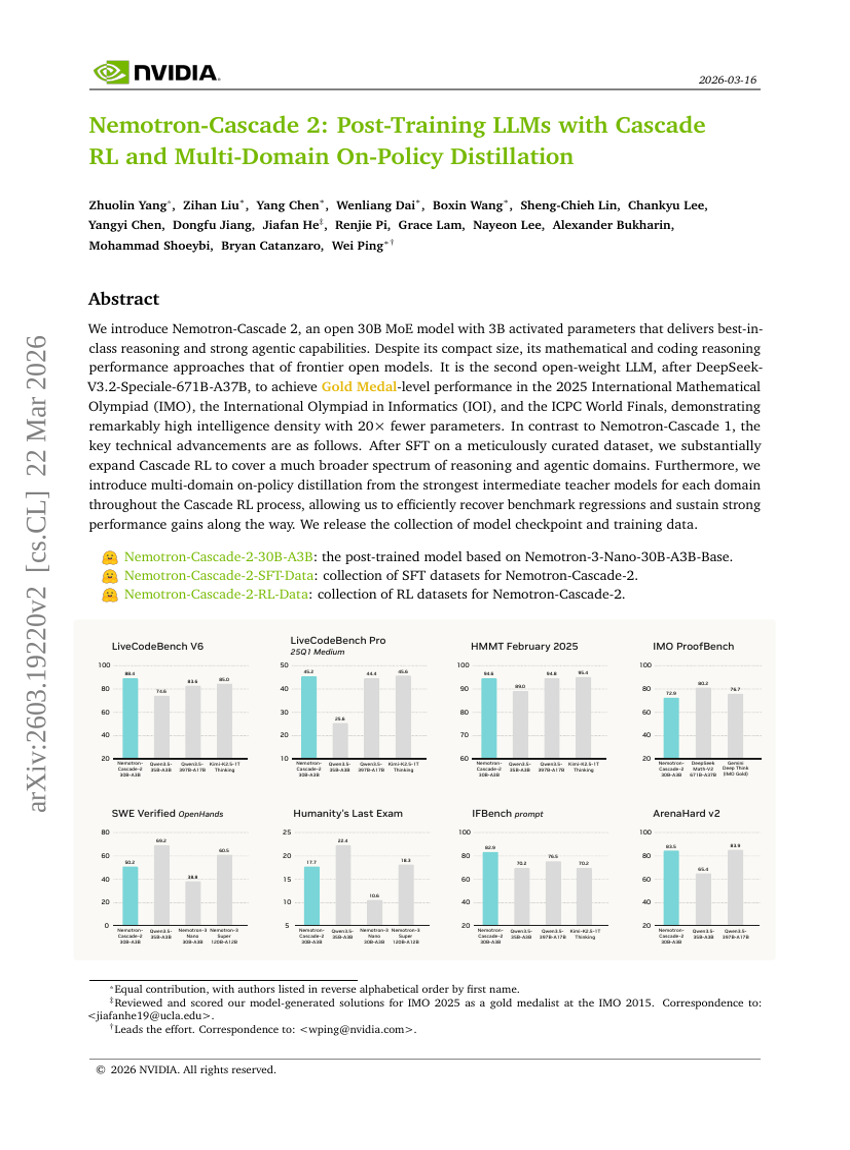
Nemotron-Cascade 2:使用级联强化学习与多域在线策略蒸馏的后训练 LLM
MOSS-TTS 技术报告
StreakMind:利用自动化数据库集成进行天文图像中卫星条纹的AI检测与分析
VibeServe:AI代理能否构建定制化的大型语言模型服务系统?
Lance:通过多任务协同实现统一的多模态建模
LongLive-2.0:用于长视频生成的NVFP4并行基础设施
切片与切块:配置最优专家混合物
智能体驱动的网络架构发现:AIRA-Compose 与 AIRA-Design
学习预见:揭示在线策略蒸馏的解锁效率
DexJoCo:面向 MuJoCo 上手操作的任务导向基准与工具包
FashionChameleon:迈向实时且可交互的人-服装视频定制
CiteVQA:用于可信文档智能的证据归因基准测试
MMSkills:迈向通用视觉 Agent 的多模态技能
PhysBrain 1.0 技术报告
将价值模型重新引入:大语言模型强化学习中的生成式批判家用于价值建模
NEXUS:一种用于时间序列预测的智能体框架
MemEye:面向多模态 Agent 记忆的以视觉为中心的评价框架
SANA-WM:基于混合线性扩散Transformer的高效分钟级世界模型
MemLens:大视觉-语言模型中多模态长期记忆的基准测试
自蒸馏式 Agent 强化学习
因果强制++:用于实时交互式视频生成的可扩展少步自回归扩散蒸馏
通过简单且统一的缩放实现金牌级奥林匹克推理
RepoZero:大语言模型能否从零开始生成代码仓库?
Qwen-Image-VAE-2.0 技术报告
通过文本-表格建模从有限交互中预测 AI Agent 的决策
高效训练长上下文视觉语言模型:实现超越 128K 上下文的泛化能力
AnyFlow:具有在线策略流映射蒸馏的任意步视频扩散模型
MinT:用于训练和服务数百万大语言模型的托管基础设施
MulTaBench:基于文本和图像的多模态表格学习基准测试
面向流式3D重建的几何上下文Transformer
Nemotron-Cascade 2:使用级联强化学习与多域在线策略蒸馏的后训练 LLM
MOSS-TTS 技术报告
StreakMind:利用自动化数据库集成进行天文图像中卫星条纹的AI检测与分析
VibeServe:AI代理能否构建定制化的大型语言模型服务系统?