Command Palette
Search for a command to run...
语言模型需要睡眠
语言模型需要睡眠
Sangyun Lee Sean McLeish Tom Goldstein Giulia Fanti
摘要
基于 Transformer 的大语言模型正日益被应用于长视界(long-horizon)任务;然而,其注意力机制随上下文长度的扩展表现出较差的可扩展性。为解决这一问题,我们研究了一种类似睡眠的巩固机制,在该机制中,模型会定期将近期上下文转换为持久的快权重(fast weights),随后清空其键值(key-value)缓存。在“睡眠”阶段,模型会对累积的上下文执行 N 次离线循环传递,并通过学习到的局部规则更新其状态空间模型(SSM)块中的快权重。在推理阶段,这种设计将额外计算量转移至睡眠阶段,同时保持了清醒时预测的延迟不变。我们在受控的合成任务(包括元胞自动机和多跳图检索)以及一项现实中的数学推理任务上测试了该方法,常规 Transformer 以及 SSM-attention 混合模型在该推理任务上均未能成功处理。随后,我们表明,增加我们模型的睡眠时长 N 能够提升性能,且在需要更深层次推理的案例中获得的增益最为显著。
一句话总结
为解决基于 transformer 的大型语言模型中注意力机制扩展性较差的问题,作者提出了一种类睡眠巩固机制,通过 N 次离线循环传递将近期上下文转换为状态空间模型块内的持久快速权重,将计算移至睡眠期,从而在保持唤醒时预测延迟的同时,在元胞自动机、多跳图检索以及常规 transformer 和 SSM-attention 混合模型失效的现实数学推理任务上实现性能提升。
核心贡献
- 引入了一种类睡眠巩固机制,模型在清除键值缓存之前定期将近期上下文转换为持久快速权重。离线循环传递通过学习到的局部规则更新状态空间模型块内的快速权重,将计算移至睡眠期而不增加推理延迟。
- 该方法在受控合成任务(包括元胞自动机和多跳图检索)以及现实数学推理任务上进行了评估。常规 transformer 和 SSM-attention 混合模型在这些任务上表现失败,而该方法显示出性能改进。
- 增加睡眠时长 N 可提高性能,在需要更深推理的示例上观察到最大增益。这表明当推理深度增加时,额外的睡眠期计算最为有益。
引言
大型语言模型通常依赖扩展性随上下文长度变差的注意力机制,导致采用结合注意力与固定大小快速权重记忆的混合架构。然而,即使内存容量充足,这些先前的模型也难以处理深度推理任务,因为它们缺乏将驱逐上下文转换为有用内部状态所需的计算。作者借鉴生物睡眠引入巩固阶段,模型在此阶段在没有外部输入的情况下对累积上下文执行循环前向传递。此过程更新快速权重以保留信息供后续推理使用,显著提高了在需要对被驱逐 token 进行深度计算的任务上的推理性能。
方法
提出的架构通过将注意力层与状态空间模型 (SSM) 块交错排列,解决了标准 transformer 的内存扩展问题。在这种混合设计中,注意力层维护随序列长度线性增长的键值 (KV) 缓存,而 SSM 层将信息存储在固定大小的快速权重状态中。模型通过堆叠这些块构建,其中注意力块表示为 Bℓattn,SSM 块表示为 Bℓssm。SSM 块利用门控赫布型更新规则将过去信息压缩到其内部状态 St 中:
St=αtSt−1+βtvtkt⊤
这里,αt 和 βt 充当数据依赖的遗忘门和输入门,使模型能够在不扩展内存需求的情况下保留相关历史。
为了管理超出注意力窗口的上下文,系统实现了一种称为 "LLM Sleep" 的巩固机制。此过程涉及在丢弃注意力缓存之前对上下文执行多次离线循环传递。
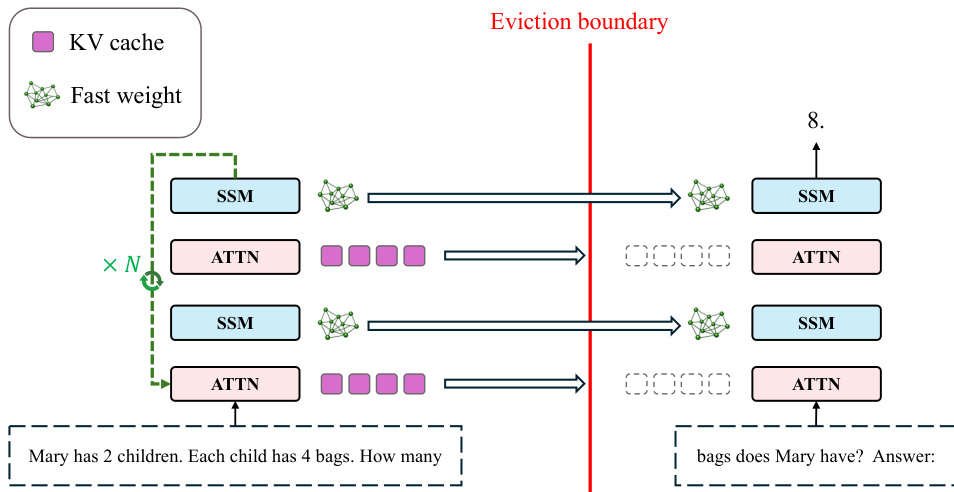
如框架图所示,模型处理输入 token 直到达到驱逐边界。此时,系统对当前上下文执行 N 次循环传递,由标记为 ×N 的绿色虚线循环指示。在这些传递期间,SSM 块中的快速权重被迭代细化以编码累积信息。同时,注意力块中的 KV 缓存(由紫色方块表示)被清除。细化的快速权重(显示为绿色网络图标)跨边界持久存在以支持后续预测。这种方法允许模型在睡眠阶段对被驱逐上下文执行深度推理,同时在推理阶段保持恒定延迟。训练通过整个计算图进行反向传播,包括循环巩固步骤。
实验
本研究在严格上下文驱逐约束下评估注意力-SSM 混合模型,使用 Rule 110 和 Depo 等合成推理任务以及 GSM-Infinite 数学基准。通过改变内存巩固期间的离线睡眠循环次数,结果表明,额外的循环显著提高了标准单次传递模型失效的深度顺序计算和多跳检索上的性能。这些发现证实,延长睡眠期计算可使模型更有效地将被驱逐上下文编码到快速权重中,这一趋势在受控合成环境和现实预训练 LLM 中持续存在。