Command Palette
Search for a command to run...
结合策略优化与蒸馏的大语言模型长上下文推理方法
结合策略优化与蒸馏的大语言模型长上下文推理方法
Miguel Moura Ramos Duarte M. Alves André F. T. Martins
摘要
将大型语言模型(LLMs)适应长上下文任务,需要采用在数千个 token 范围内仍能保持准确性和连贯性的后训练方法。现有方法在多个方面存在局限:1)监督微调(SFT)和知识蒸馏(KD)等离策略(off-policy)方法存在暴露偏差(exposure bias),且在长跨度下难以从模型生成的错误中恢复;2)组相对策略优化(GRPO)等在线策略(on-policy)强化学习方法使训练过程更贴合模型生成的状态,但由于奖励稀疏,存在不稳定性且样本效率低下;3)在线策略蒸馏(OPD)提供了密集的 token 级指导,但未能直接优化任意奖励信号。在本文中,我们提出了蒸馏组相对策略优化(dGRPO),这是一种用于长上下文推理的方法,它通过在线策略蒸馏(OPD)从更强的教师模型中引入密集指导,从而增强 GRPO。此外,我们引入了 LONGBLOCKS,这是一个合成长上下文数据集,涵盖了多跳推理、上下文定位和长文生成等多个方面。我们进行了广泛的实验和消融实验,对比了离策略训练、稀疏奖励 GRPO 以及我们提出的组合方法,从而优化了长上下文对齐的训练策略。
一句话总结
本文提出了 Distilled Group Relative Policy Optimization (dGRPO),该方法通过在线策略蒸馏增强 GRPO,引入更强教师的密集指导,以减轻离线方法的暴露偏差和稀疏奖励强化学习的不稳定性,并引入了涵盖多跳推理、上下文定位和长文本生成的 LONGBLOCKS 合成数据集,通过对比离线训练、稀疏奖励 GRPO 和组合方法的广泛实验,验证了长上下文对齐的改进方案。
核心贡献
- 本文介绍了 Distilled Group Relative Policy Optimization (dGRPO),一种通过在线策略蒸馏增强 Group Relative Policy Optimization 并引入更强教师密集指导的方法。这种组合通过利用密集监督优化模型生成的轨迹,解决了稀疏奖励强化学习的不稳定性以及离线方法的暴露偏差问题。
- 提出了名为 LONGBLOCKS 的合成长上下文数据集,以支持涵盖多跳推理、上下文定位和长文本生成的长上下文训练。该资源支持对需要远距离依赖鲁棒性和扩展范围内稳定推理的任务进行模型评估和训练。
- 广泛实验表明,结合离线冷启动与在线策略优化可在不牺牲短上下文能力的情况下,持续提升长上下文性能。这些发现确立了一种实用的后训练方案,能有效对齐大语言模型以应对复杂的长范围生成任务。
引言
使大语言模型适应长上下文任务对于代码库理解和多会话交互等应用至关重要。现有的后训练方法面临重大障碍,其中离线方法受暴露偏差困扰,而在线策略强化学习因奖励稀疏而面临不稳定性。作者通过提出 Distilled Group Relative Policy Optimization (dGRPO) 来解决这些局限性,该方法通过更强教师的密集指导增强 Group Relative Policy Optimization。他们还引入了 LONGBLOCKS,一个旨在支持多跳推理和长文本生成的合成数据集,从而形成了一种保持短上下文能力的长上下文对齐稳定方案。
数据集
数据集组成与来源
- 作者引入了 LONGBLOCKS,这是一个包含 193,219 个问答对的多语言合成数据集,专为长上下文适应设计。
- 数据源自多种语料库,包括 ArXiv、Wikipedia、StackExchange、Project Gutenberg Books、Stack-Edu、FineWeb2-HQ 和 Institutional-Books-1.0。
- 该集合涵盖超过 30 种自然语言和 15 种编程语言。
处理与过滤
- 两阶段流水线通过从源语料库中采样足够长且自包含的文档来生成数据。
- 团队使用 Qwen3-Next-80B-A3B-Thinking 创建候选问答对,这些问答对要求整合扩展上下文中的证据。
- 使用模糊去重移除格式错误和近似重复的文档。
- LLM-as-a-judge 步骤验证候选项并拒绝格式错误的输出、不完整的回答、无支持的回答以及可从局部范围回答的问题。
- 问题类型包括总结、多部分信息检索、多跳推理、综合和分类问题。
训练用法与混合
- 该数据集支持离线预热和在线策略对齐。
- 在 SFT 和 RL 期间,作者保持短上下文和长上下文数据的固定 10/90 token 级别混合。
- 短上下文样本均匀地从 Nemotron-Post-Training-Dataset-v2 中抽取,而长上下文样本来自 LONGBLOCKS。
其他处理细节
- 编程语言和标记语言从 Stack-Edu 中均匀采样。
- 生成的输出严格遵循 Question: 后跟 Answer: 的格式。
- 提示词确保问题要求从文档的多个部分定位信息或在不同部分和主题间进行推理。
方法
作者提出了一种统一训练流水线,旨在将强化学习扩展到长上下文推理任务。参考框架图以了解两阶段过程的概述。
流水线始于使用监督微调 (SFT) 的离线冷启动阶段。此初始阶段利用高质量的短上下文和长上下文指令来引导长上下文行为。通过提供密集的 token 级别监督,这种预热提高了长上下文生成的连贯性并稳定了后续的在线策略学习。这种初始化在长范围设置中至关重要,如果生成质量低,token 级别的优势估计可能会变得脆弱。
初始化后,模型使用 Distilled Group Relative Policy Optimization (dGRPO) 进行在线策略优化。此阶段解决了标准离线方法的局限性,如暴露偏差,以及纯在线策略 RL 的样本效率低下问题。dGRPO 结合了两个互补信号:来自 Group Relative Policy Optimization (GRPO) 的稀疏结果级别奖励,以及通过在线策略蒸馏 (OPD) 来自教师模型的密集 token 级别指导。
GRPO 通过移除对单独价值函数批评器的需求来简化价值估计。相反,它从给定提示 p 的一组采样完成 {o1,o2,…,oG} 估计基线。为了减轻长上下文训练中稀疏奖励的脆弱性,dGRPO 添加了一个 KL 散度项,将学生策略锚定在教师策略上,针对学生实际访问的轨迹。目标函数定义为:
IdGRPO(θ)=Ep∼P,{oi}i=1G∼πθold(⋅∣p)G1i=1∑G∣oi∣1t=1∑∣oi∣min(ρi,t(θ)A^i,t,ρˉi,t(θ)A^i,t)−βDKL(πθ(⋅∣p,oi,<t)πteacher(⋅∣p,oi,<t))其中 β≥0 控制教师正则化的强度。第一项优化稀疏奖励,而 KL 项提供 token 级别反馈。
为了支持此训练,作者利用了一个合成长上下文数据集。生成高质量指令以确保任务需要理解整个文档。如下所示:

实验
评估将两阶段后训练流水线与基础模型和仅 SFT 模型进行比较,使用全面的短上下文推理和长上下文检索基准。主要结果表明,结合 SFT 与 dGRPO 能够实现长上下文任务的稳健扩展,同时保持短任务准确性,而没有预热启动的强化学习则会降低性能。消融研究证实,与替代方案相比,dGRPO 稳定了优化,并通过外部教师和平衡数据分配实现了最佳性能,验证了该方法将性能前沿推向了比更大基准模型更高的水平。
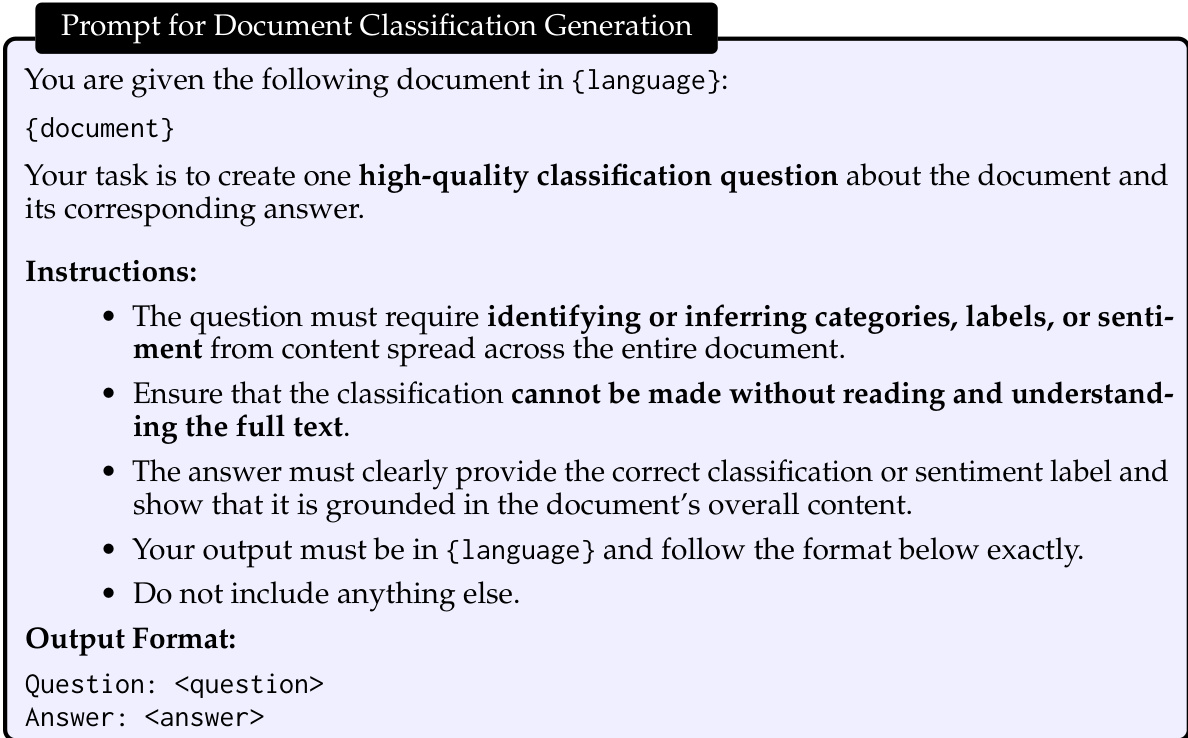
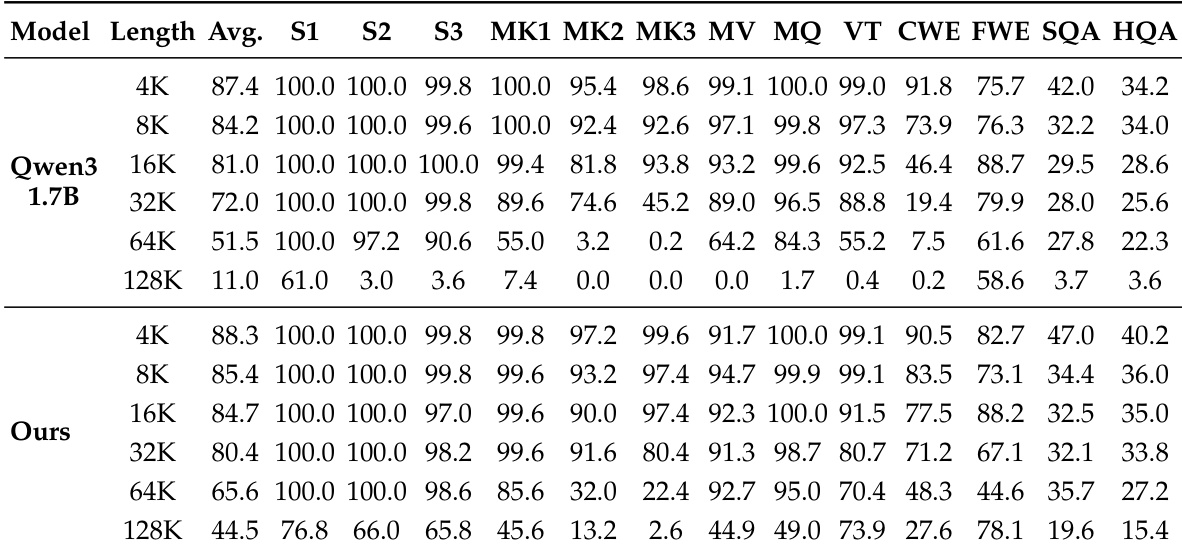
作者使用 RULER 基准测试将其提出的模型与基础 Qwen3-1.7B 模型进行比较,以评估不同上下文长度下的性能。结果表明,所提出的方法实现了更高的平均分数,并显示出比基础模型实质性的改进,特别是在序列长度增加时。虽然基础模型在最长上下文长度下表现显著挣扎,但所提出的模型保持了更强的性能,显示出长上下文检索和推理任务的有效扩展。所提出的模型实现了比基础 Qwen3-1.7B 模型更高的平均 RULER 分数。性能增益在更长的序列长度下变得越来越明显,在最大上下文长度下观察到显著优势。基础模型在最长上下文长度下显示性能急剧下降,而所提出的模型保留了显著更高的准确性。
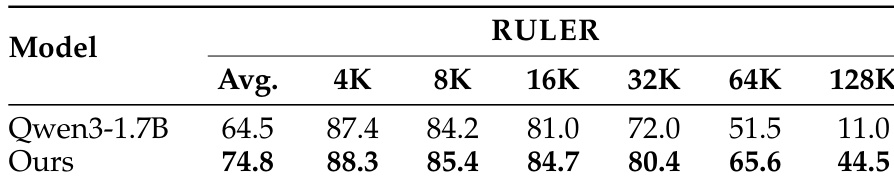
作者在其提出的方法上针对一系列长上下文基准测试与基础 Qwen3-1.7B 模型进行比较。结果表明,所提出的方案在大多数类别中产生了实质性的改进,特别是在检索和问答任务中,同时保持了其他领域的性能。像 PassKey 和数字检索这样的检索任务显示出比基准显著的性能增长。问答和推理类别显示出比基础模型显著的相对增益。所有类别的平均分数大幅增加,验证了方法的有效性。
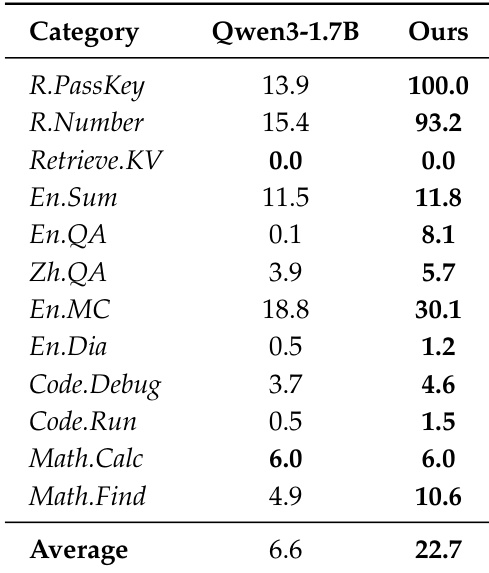
该表比较了基础 Qwen3-1.7B 模型与作者提出的模型之间的多语言基准测试结果。所提出的模型在测试语言的整体平均性能上显示出改进。虽然基础模型在德语和法语中保留了更高的分数,但作者的方法在日语和中文中产生了实质性增益。所提出的模型实现了比基础 Qwen3-1.7B 模型更高的平均分数。在日语和中文中观察到实质性的性能改进。基础模型在德语和法语任务上优于所提出的版本。
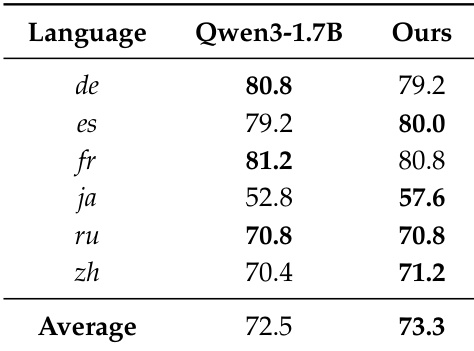
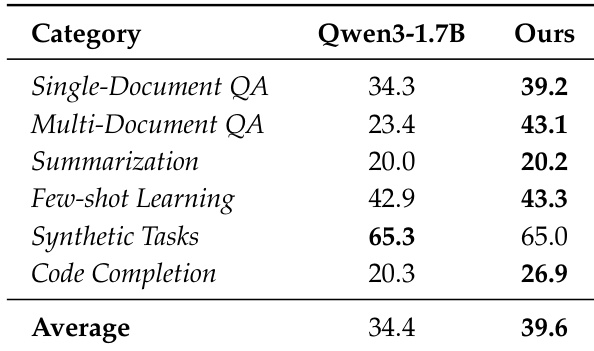
作者将其提出的训练方案与基础 Qwen3-1.7B 模型在包括 QA、总结和编码在内的多样化任务套件中进行评估。结果表明,他们的方法实现了更高的平均性能,主要由多文档 QA 和代码完成的实质性增益驱动。虽然合成任务上的性能与基准相当,但该方案成功增强了复杂推理和生成任务的能力,而没有降低其他任务的性能。所提出的模型实现了比基础模型更高的整体平均分数。在多文档 QA 和代码完成类别中观察到显著的性能改进。在单文档 QA、总结和少样本学习中的性能显示出比基准适度的增益。
作者将其提出的模型与基础 Qwen3-1.7B 在不同上下文长度下进行比较,以评估长上下文能力。结果表明,虽然基础模型随着上下文长度增加而遭受显著的性能下降,但所提出的方法即使在测试的最大长度下也保持了稳健的准确性。这表明训练方案成功扩展了检索和推理能力,而没有损害短上下文性能。所提出的模型在长上下文基准测试上实现了比基础模型实质性的增益,特别是在最长的序列长度下。短上下文性能保持稳定或略有提升,证明长上下文对齐保留了核心能力。特定子任务在所提出的模型中显示出显著的韧性,而基础模型在扩展长度下的检索和推理方面存在困难。
作者将其提出的模型与基础 Qwen3-1.7B 模型在包括 RULER、多语言评估以及从编码到问答的各种任务在内的多样化基准测试中进行评估。结果表明,所提出的方法始终实现了更高的平均性能,在长上下文检索和推理方面取得了实质性增益,而基础模型在这些方面表现显著挣扎。虽然性能在特定语言间略有变化,但该方法成功扩展了长上下文能力,而没有损害短上下文准确性或其他核心能力。