Command Palette
Search for a command to run...
WBench:用于交互式视频世界模型评估的综合多轮基准
WBench:用于交互式视频世界模型评估的综合多轮基准
Kaining Ying Hengrui Hu Siyu Ren Jiamu Li Fengjiao Chen Ziwen Wang Xuezhi Cao Xunliang Cai Henghui Ding
摘要
标题:WBench:交互式世界模型的多轮综合基准摘要:交互式世界模型正在快速发展,然而现有的基准测试仅涵盖部分所需能力,缺乏用于系统评估的统一标准。为填补这一空白,我们引入了WBench,这是一个用于交互式世界模型评估的综合多轮基准测试,涵盖视频质量、场景遵循、交互遵循、一致性和物理合规性五个维度。WBench包含289个测试用例和1,058个交互轮次,每个用例均指定了世界设定和多轮交互序列,涵盖多样化的场景、风格、主体以及第一人称和第三人称视角,并包括四种交互类型:导航、主体动作、事件编辑和视角切换。在导航任务中,WBench统一了文本、6自由度(6-DoF)姿态和离散动作控制,从而能够评估具有不同原生输入接口的模型。评估采用22项自动子指标,结合专业视觉模型与大多模态模型,且所有指标均经过人类判断验证。在对20个最先进模型的评估中,我们发现没有任何单一模型在所有维度上均表现强劲。我们提供了对每个模型典型优势、劣势及开放挑战的详细诊断性见解。代码和数据可在https://github.com/meituan-longcat/WBench获取。
一句话总结
作者提出了 WBENCH,这是一个综合性的多轮评测基准,使用二十一项经人类验证的自动化指标,从五个维度评估交互式视频世界模型;统一了文本、6-DoF 位姿和离散动作控制,以适配多种输入接口;并为二十款前沿模型的性能权衡提供了详细的诊断洞察。
核心贡献
- 引入 WBENCH 作为统一的多轮评测基准,系统性地从五个维度(视频质量、设定遵循度、交互遵循度、一致性以及物理合规性)评估交互式世界模型。
- 包含 289 个测试用例和 1,058 次交互轮次的标准化数据集,通过支持文本、6-DoF 位姿和离散动作控制的统一导航接口,实现了跨范式的比较,覆盖多种场景与视角。
- 采用包含 22 个细粒度子指标的完全自动化评估管线,这些指标已通过人类判断验证,应用于 20 款前沿模型以建立诊断基线,并证明没有任何单一系统能在所有维度上均表现出强劲性能。
引言
交互式视频世界模型正快速发展,通过模拟响应用户操作的动态环境,为游戏、自主系统和具身智能等领域的应用提供动力。尽管取得这些进展,评测工作仍然碎片化,因为现有基准通常仅评估视觉质量或单视角导航等孤立能力,导致公平比较和可靠的故障诊断几乎无法实现。为克服这些局限,作者提出了 WBENCH,这是一个综合性的多轮评测基准,使用二十一个细粒度的自动化指标从五个核心维度评估世界模型。该框架在多种开放域场景、双视角以及四种不同交互类型上标准化了测试流程,同时提供统一的导航接口以支持跨范式比较。这一完全自动化的评估管线建立了清晰的诊断基线,并提炼出可操作的洞察,以指导未来的模型开发。
数据集

- 数据集构成与来源:作者提出了 WBENCH,这是一个包含 289 个测试用例和 1,058 次交互轮次的多轮评测基准。初始帧来源于 Nano Banana 2 和 GPT-Image-1.5,并补充了网络收集与手动拍摄的画面。所有素材均经过人工验证。数据集涵盖六个场景类别、五种主体类型和七种视觉风格,第一人称与第三人称视角的比例保持在 62 比 38。
- 子集详情与构建:作者采用设定优先的方法组织基准测试。标注人员设计世界设定,并推导出符合物理规律且因果有序的交互序列。分层采样确保了场景、风格、视角、主体和四种交互类型的平衡覆盖。导航用例占 57%,细分为六种轨迹拓扑;主体动作、事件编辑和视角切换构成其余部分。每个用例均经过人工审核,以验证提示词到初始帧的一致性以及轮次间的连贯性。
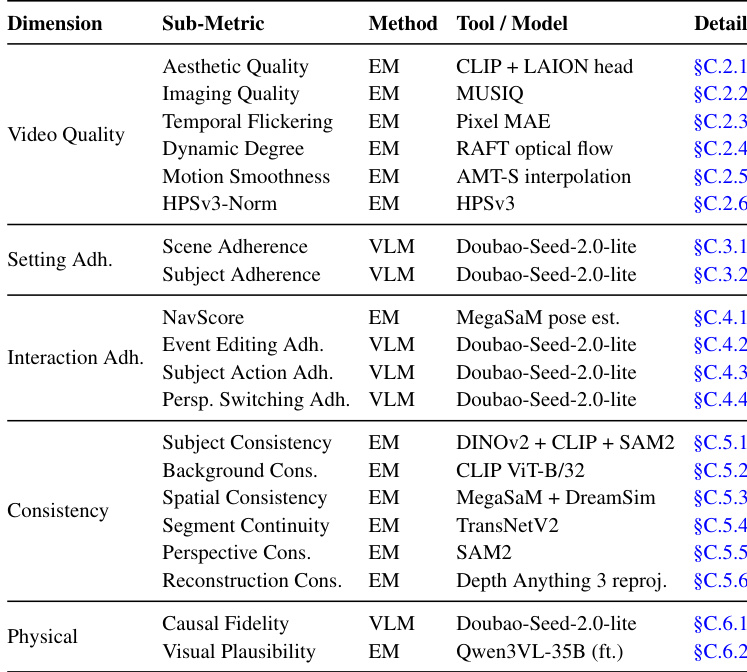
- 使用方式与评估协议:作者严格将 WBENCH 作为独立测试基准,用于评估二十款交互式世界模型,而非用于训练。因此,该数据集不包含任何训练集划分或混合比例。针对文本驱动模型采用迭代式图生视频协议,其他模型则使用原生控制接口。该基准通过二十一个自动子指标进行处理,这些指标结合了专用视觉模型与大语言多模态模型。所有指标均通过与人类判断对比进行验证,以评估视频质量、设定遵循度、交互遵循度、一致性和物理合规性。
- 元数据与处理细节:作者通过四个属性(场景、风格、视角和主体)定义每个世界设定来构建元数据。这些属性组合成环境与主体提示词,用于生成初始帧。在评估阶段,作者以每秒 2 到 3 帧的频率采样,并将视频缩放至较长边不超过 512 像素。导航命令在文本、六自由度位姿和离散 WASD 输入之间实现统一,并采用依赖视角的映射关系。作者还实现了带有 JSON 评分标准的结构化 VLM 提示词,用于评估流体动力学、碰撞和表面交互等特定物理维度。
方法
作者提出了一套用于评估交互式世界模型的综合框架,核心在于输入的结构化分解与生成视频质量的多维度评估。基础方法将每个评估用例分解为世界设定 W(定义环境的初始状态)和交互序列 I(指定用户在多轮交互中的控制信号)。该框架能够系统评估模型在初始上下文与动作时间序列条件下,生成连贯、符合物理规律且行为一致的视频输出的能力。整体架构如图 1 所示,展示了评估流程的关键组件,包括初始图像、交互类型(导航、主体动作、事件、视角切换)以及统一的评估系统。
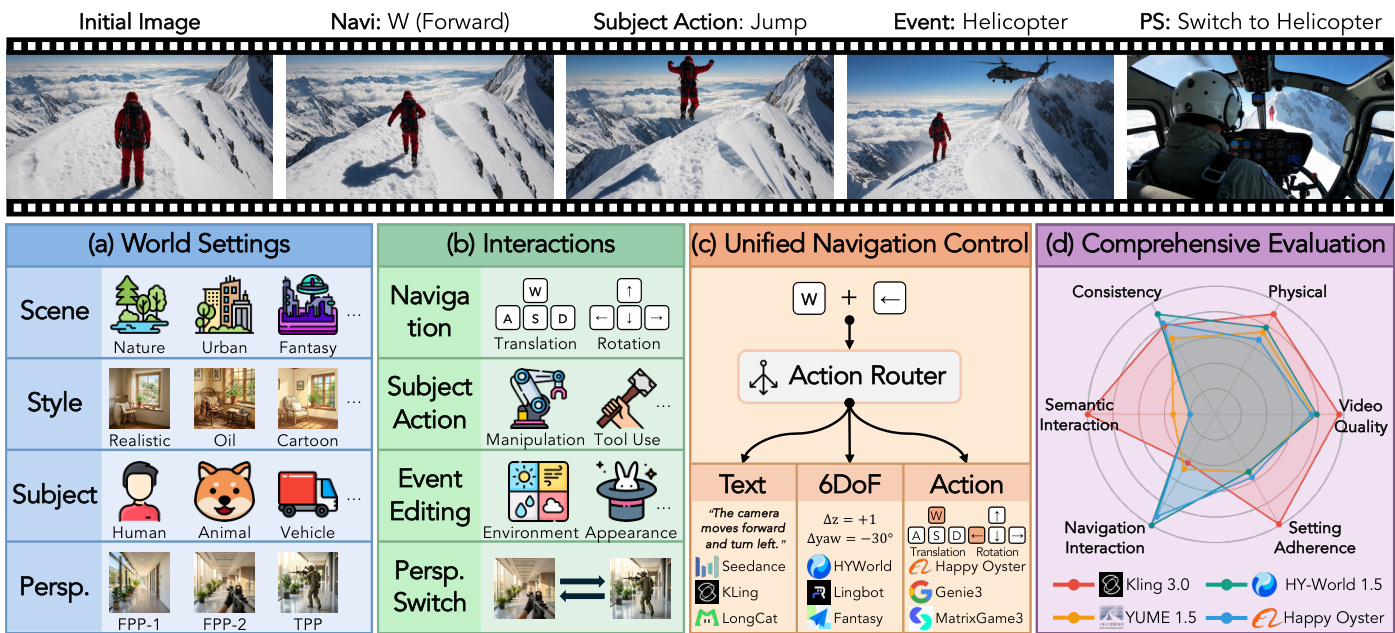
评估套件由五个互补维度构成:视频质量、设定遵循度、交互遵循度、一致性以及物理保真度。视频质量衡量生成视频的感知质量,包含审美质量、成像质量、时间闪烁、运动平滑度以及人类偏好奖励分数等子指标。设定遵循度评估对指定世界设定的忠实程度,子指标用于衡量场景与主体的遵循情况。交互遵循度聚焦于交互序列的正确执行,涵盖导航准确性、事件编辑、主体动作和视角切换。一致性衡量场景几何、物体外观和视角随时间推移的稳定性。物理保真度评估生成世界是否遵守既定物理规则,涵盖高层因果保真度与底层视觉合理性。
该框架支持多种动作条件模型,采用标准化的网页界面协议进行评估。这些模型(包括 Happy Oyster、Matrix-Game、Genie 3、Hunyuan-GameCraft 和 Infinite-World)旨在接收离散或连续的动作信号,并基于完整动作历史生成后续观测结果。评估过程由人工操作员输入键盘指令,并将生成的视频流进行屏幕录制,以便进行离线指标计算。作者强调,评估协议必须具备鲁棒性,以适配不同模型的多样化输入接口与运动幅度。
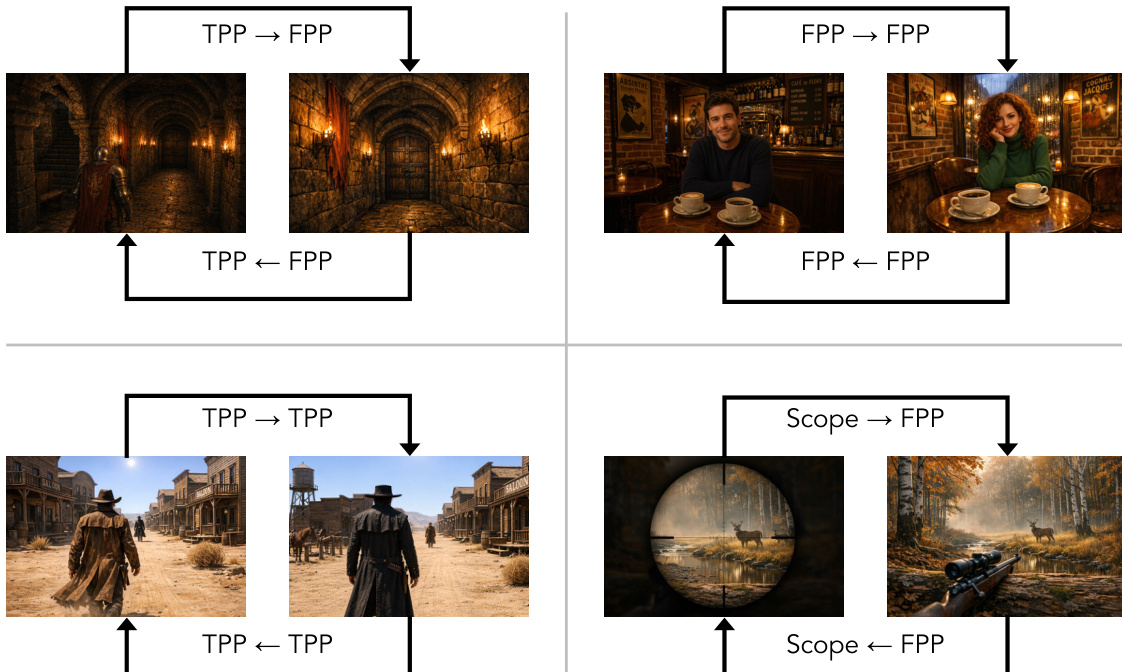
针对导航评估,作者提出导航得分(NavScore),该得分结合导航准确性与轨迹一致性。导航准确性采用归一化绝对轨迹误差(nATE)进行衡量,该过程经过自适应真实轨迹构建与弧长重采样。轨迹一致性通过比较对称或重复的动作对进行评估,一致性得分由平均归一化 ATE 推导得出。最终 NavScore 为准确性与一致性项的平均值,并重新缩放至 0 到 100 的区间。图 2 展示了一个四轮导航案例,说明自适应真实轨迹构建如何确保对不同运动幅度的模型进行公平评估。

一致性维度通过多项子指标进行评估。空间一致性衡量初始帧与往返轨迹返回帧之间的感知相似度,而门控空间一致性会在视频几乎无移动时抑制得分。片段连续性检测视频内意外的硬切,视角一致性追踪主体质心在帧间的稳定性。几何一致性与光度一致性采用统一的基于深度的重投影管线进行评估,其中几何一致性通过重投影位移衡量 3D 结构连贯性,光度一致性通过重投影帧对的像素级 PSNR 衡量外观稳定性。
物理维度通过两阶段流程进行评估。因果保真度利用 VLM 评估全局合理性与上下文条件准确性,覆盖七个物理子维度,最终得分为两阶段结果的平均值。视觉合理性采用微调后的 Qwen3-VL-30B-A3B 模型进行评估,该模型基于五级评分系统预测连续得分,并针对与人类判断对齐进行优化。图 3 展示了从初始图像到最终综合评估的整体流程,突出了生成与评估视频输出的逐步工作流。
实验
该评估在文本驱动、相机控制和动作条件三种范式下检验了二十款模型的性能,验证其在视频质量、设定遵循度、交互控制、时间一致性与物理合理性方面的表现。定性分析表明,没有任何单一范式在所有方面均占主导地位,因为文本驱动模型在场景定位与语义交互方面表现优异,而专用世界模型则在空间导航与几何一致性方面领先。关键在于,导航能力在结构上独立于渲染质量与物理引擎,在多轮交互中因累积的空间漂移而非生成能力局限而迅速下降。最终结果表明,当针对特定控制任务进行优化时,开源架构的性能可媲美专有系统,且基准测试的难度主要由空间映射与场景动态的复杂性决定。
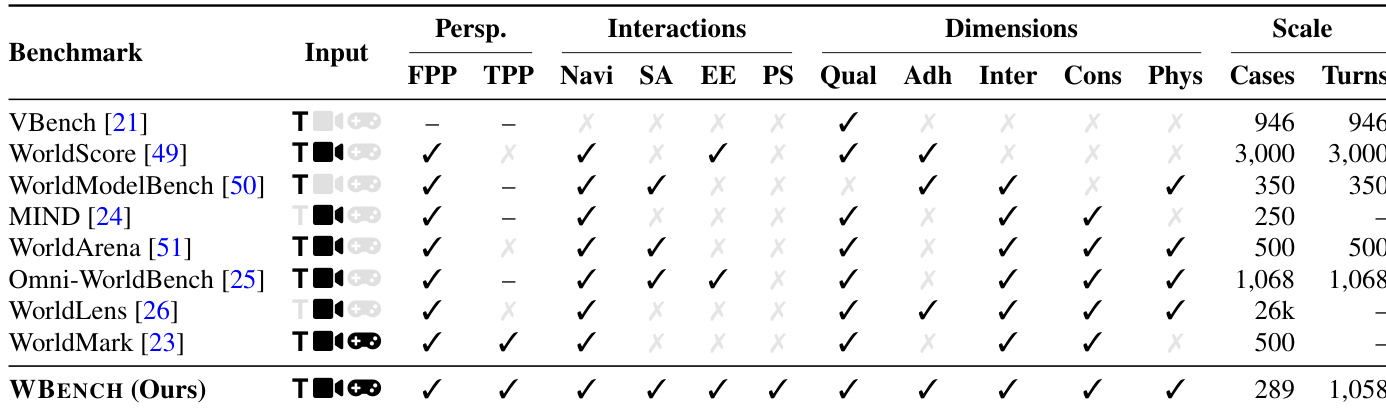
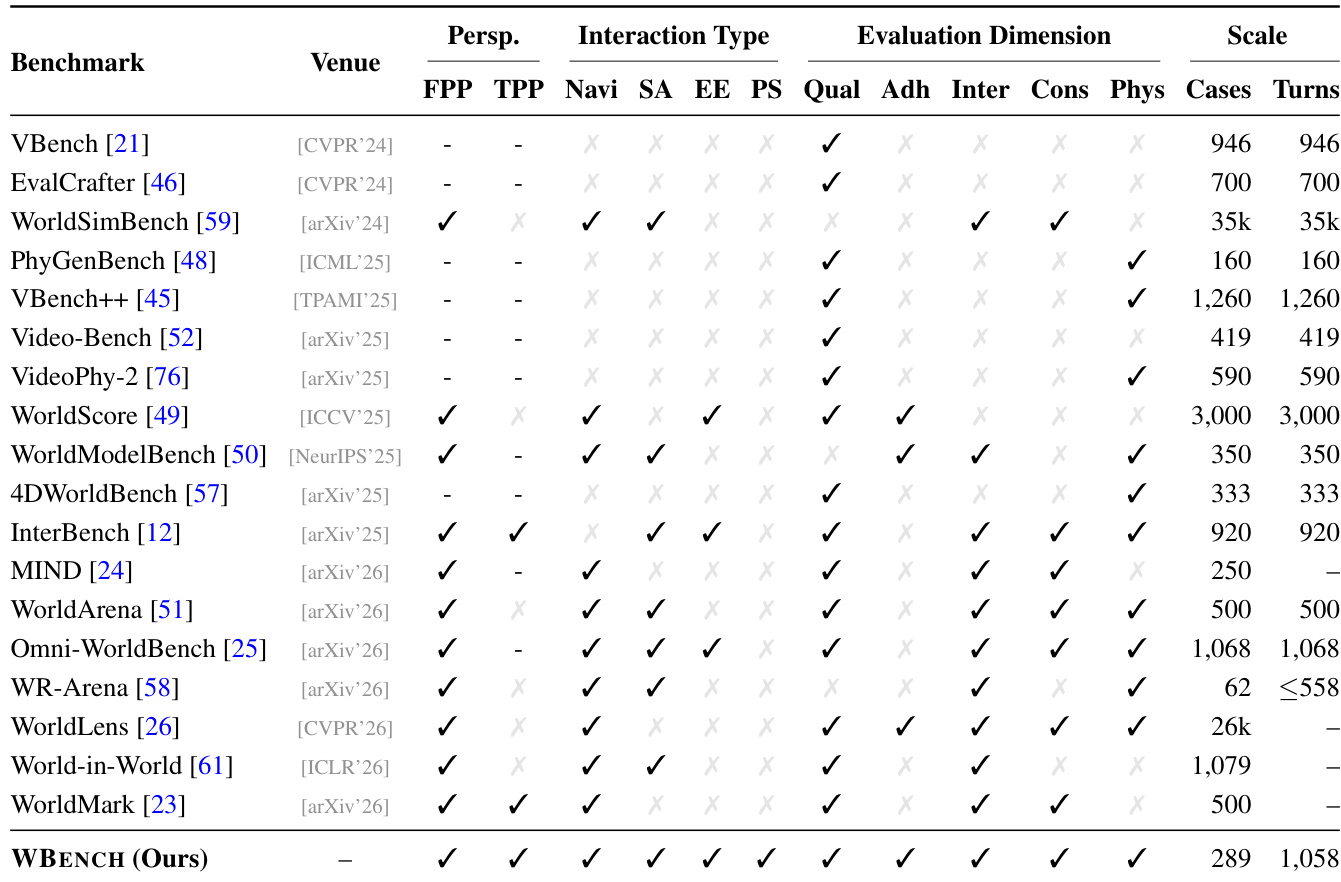
下表从输入模态、交互类型、评估维度和规模方面将 WBENCH 与现有基准进行对比。WBENCH 支持比其它基准更广泛的交互类型与维度,涵盖导航、事件编辑、主体动作和视角切换,并在更多用例与交互轮次上进行评估。该基准还引入了统一框架,支持不同模型范式间的公平比较。与现有基准相比,WBENCH 评估了更广泛的交互类型与维度。WBENCH 覆盖的用例与轮次数量多于大多数现有基准。WBENCH 通过在统一框架上评估不同类型的模型,支持跨范式比较。
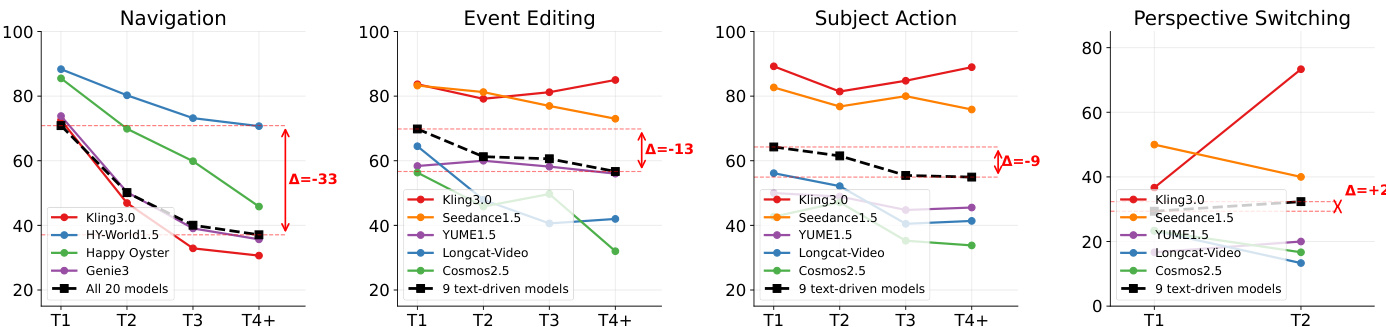
作者从物理合理性、交互遵循度和一致性等多个性能维度对多款视频生成模型进行了评估。结果表明,没有任何单一模型在所有任务中均表现优异,不同模型在碰撞规避、人体运动或反射处理等特定领域各具优势。模型在处理形变与破坏等复杂物理任务时往往失败,表明这些领域仍是难点。评估结果凸显了运动动态与时间稳定性之间的权衡,部分模型虽达成高一致性但动态程度较低。没有任何模型在所有物理合理性子维度上占据绝对优势,其在碰撞、形变和人体运动等任务上的表现差异显著。Wan 2.7 和 Kling 3.0 等文本驱动模型在交互遵循度方面领先,尤其在事件编辑和主体动作上表现突出,而视角切换则普遍具有较高难度。一致性指标揭示了运动动态与时间稳定性之间的权衡,达成高一致性的模型通常动态程度较低。

作者使用一套评估指标,分析了模型在导航、事件编辑、主体动作和视角切换四种交互类型上的表现。结果显示,没有任何单一模型在所有任务中占据主导,不同范式与能力之间存在明显的权衡。导航性能随交互轮次增加而显著下降,而视角切换在所有模型中得分均持续偏低。文本驱动模型在事件编辑和主体动作等语义交互中表现优异,但相比相机控制与动作条件模型,其在导航方面有所落后。导航性能随交互轮次迅速衰减,文本驱动模型的下降幅度最大。文本驱动模型在事件编辑和主体动作上取得最高分,而相机控制与动作条件模型在导航方面表现更佳。视角切换仍是难度最高的交互类型,所有模型得分均较低,且随轮次增加改善甚微。
下表从视频质量、设定遵循度、交互遵循度、一致性与物理合规性等多个维度,将 WBENCH 与现有基准进行对比。该对比突出显示,WBENCH 评估了更广泛的交互类型与维度,特别支持第一人称与第三人称视角,并纳入了事件编辑和视角切换等多样化交互模态。与大多数现有基准相比,该基准在用例数量与交互轮次上规模更大,从而能够全面评估交互式视频生成模型。与现有基准相比,WBENCH 评估了更广泛的交互类型与维度,涵盖视角切换与事件编辑。WBENCH 支持第一人称与第三人称视角,使相机控制与主体交互的评估更为全面。WBENCH 在用例与轮次规模上更大,允许在长程交互中对模型性能进行更广泛的测试。
实验从视频质量、设定遵循度、交互遵循度、一致性与物理合理性等多个维度评估了多款视频生成模型。结果表明,文本驱动模型通常在设定遵循度与交互遵循度方面领先,而相机控制与动作条件模型在导航相关任务中表现更佳。一致性与物理维度揭示了运动动态与稳定性之间的权衡,不同模型在特定子指标上各具优势。与相机控制及动作条件模型相比,文本驱动模型实现了更高的设定遵循度与交互遵循度。相机控制与动作条件模型在导航任务中表现更好,而文本驱动模型在语义交互方面领先。一致性与物理维度在各模型间呈现出差异化的表现,部分模型在因果保真度或几何一致性等特定子指标上表现突出。
该评估利用 WBENCH 从物理合理性、交互遵循度和时间一致性方面验证交互式视频生成模型。结果表明,没有任何单一模型在所有任务中占据主导,揭示了运动动态与稳定性之间的内在权衡。文本驱动架构在语义交互与设定遵循度方面表现优异,而相机控制与动作条件模型在导航任务中表现更佳。复杂的物理现象、视角切换以及长程导航轮次在所有范式中均持续构成挑战。