Command Palette
Search for a command to run...
Gemini Embedding 2:来自 Gemini 的原生多模态 Embedding 模型
Gemini Embedding 2:来自 Gemini 的原生多模态 Embedding 模型
摘要
我们推出了 Gemini Embedding 2,这是一款原生多模态嵌入模型,能够将视频、音频、图像和文本等不同模态的数据映射到统一的表示空间中。我们利用 Gemini 的多模态能力,为跨越所有模态的任意交错输入序列生成嵌入向量,这些嵌入在广泛的任务中展现出良好的泛化能力。通过在多任务、多阶段的训练架构中应用大规模对比学习,我们在关键的嵌入基准测试中取得了最先进的性能,涵盖单一模态、跨模态以及多模态检索任务,且涉及的任务类型多样。实验结果表明,我们的嵌入模型在多种任务中表现出卓越的性能(在 MSCOCO 上 R@1 得分为 62.9,在 Vatex 上 NDCG@10 得分为 68.8,在 MTEB 多语言基准上得分为 69.9,在 MTEB 代码基准上得分为 84.0),超越了各类专用模型的表现。这些统一的能力使 Gemini Embedding 2 成为检索增强生成(RAG)、推荐系统及搜索等下游应用场景的有力候选方案。此外,该模型在从天体物理、生物科学到艺术、烹饪等不同领域的鲁棒 zero-shot 性能,证明了其作为开箱即用的表示方法,即使在特定专业领域也具有极高的可靠性。
一句话总结
Gemini Embedding 2 是一个原生多模态嵌入模型,它通过多任务多阶段训练设置中的大规模对比学习,将视频、音频、图像和文本模态嵌入到统一的表示空间中,从而在关键基准测试中实现最先进的性能,包括 MSCOCO 上的 62.9 R@1、Vatex 上的 68.8 NDCG@10、MTEB 多语言上的 69.9 以及 MTEB 代码上的 84.0,同时在天文学、生物科学、美术和烹饪艺术等专门领域展现出稳健的零样本性能,适用于 RAG、推荐和搜索等下游用例。
核心贡献
- Gemini Embedding 2 是一个原生多模态嵌入模型,在统一的表示空间内表示视频、音频、图像和文本模态。该系统支持所有模态之间交错输入的任意组合,无需转换为中间格式。
- 多任务多阶段训练设置中的大规模对比学习实现了关键嵌入基准测试的最先进性能。该模型在 MSCOCO 上达到 62.9 R@1,在 Vatex 上达到 68.8 NDCG@10,在 MTEB 多语言上达到 69.9,在 MTEB 代码上达到 84.0,超越了单模态、跨模态和多模态检索任务中的专用模型。
- 在天文学和生物科学到美术和烹饪艺术等不同领域展现了稳健的零样本性能。该架构通过证明原生音频输入在检索任务中优于传统 ASR 同时消除了对特定任务指令的需求来建立效率。
引言
嵌入模型为搜索和 RAG 等应用提供必要的语义表示,但现有的多模态方法通常依赖难以处理混合输入的晚期融合编码器。这些系统缺乏深度的跨模态交互,通常依赖自动语音识别等中间转换而不是原生处理音频。作者引入 Gemini Embedding 2 将文本、图像、音频和视频映射到统一的表示空间。它们利用底层的 Gemini 模型和大规模对比学习在 diverse 基准测试中实现最先进的性能。该统一架构支持复杂的下游用例,如 Agent 系统,无需特定任务指令或模态转换。
方法
多模态 Gemini Embedding 2 模型旨在为不同模态的输入(包括文本、图像、视频和音频)生成整体表示。这些表示促进了检索、聚类和排序等下游任务。该模型利用 Gemini 基础模型固有的多模态能力来构建这些表示。
架构首先将原始输入格式转换为 token 序列,这一过程由底层的 Gemini 模型原生处理。这允许系统接受 Gemini 支持的原始图像、视频或音频格式。一旦分词,长度为 L 的 token 输入序列 T 由具有双向注意力的 transformer M 处理。这产生 token 嵌入序列 Tembed=M(T)∈RL×dM,其中 dM 是 transformer 模型维度。为了将此信息压缩为单个向量,应用了池化操作。作者利用平均池化沿序列轴平均 token 嵌入,得到 Pembed=P(Tembed)∈RdM。最后,线性投影 f 将嵌入缩放到目标维度 d,产生最终输出 E=f(Pembed)∈Rd。
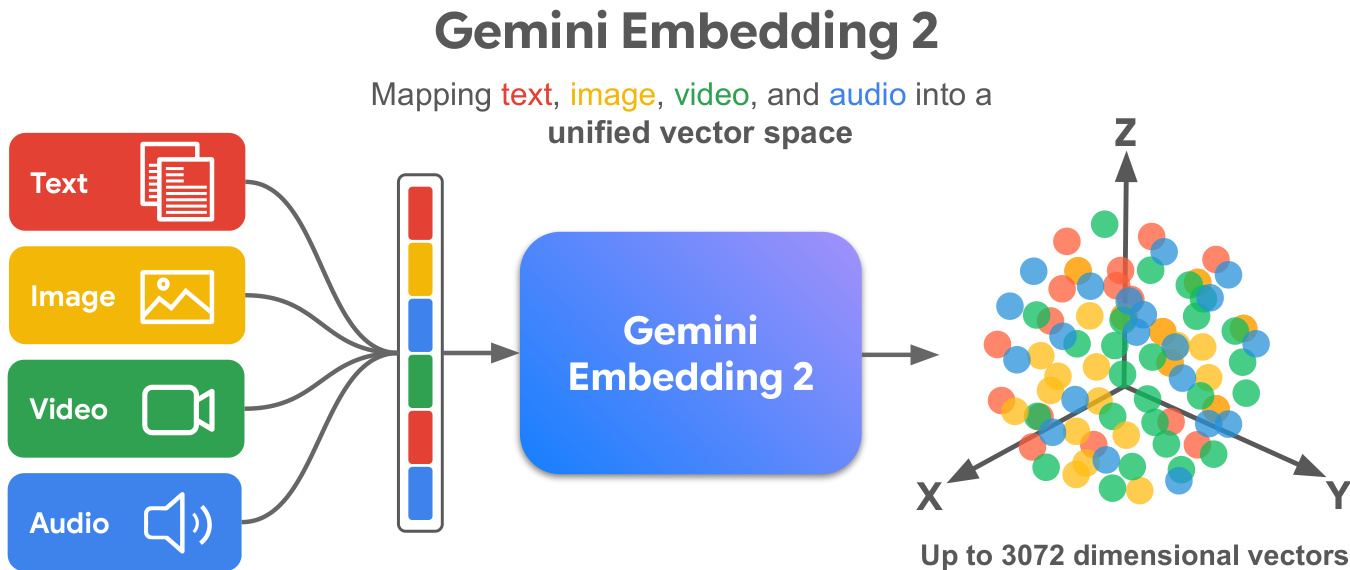
下图说明了这些不同模态如何映射到统一的向量空间。
训练过程采用多任务和多阶段策略以适应数据的多模态性质。核心目标函数是带有批次内负样本的噪声对比估计 (NCE) 损失。训练示例通常包括查询 qi、正目标 pi+,以及可选的硬负目标 pi−。在纯文本任务中,包含任务字符串 t 来描述任务性质,尽管该字符串在训练期间被随机丢弃以增强鲁棒性。
查询和段落嵌入计算如下: qi=f(mean_pool(M(t⊕qi))),pi±=f(mean_pool(M(pi±)))
对于大小为 B 的批次,损失计算如下: L=B1∑i=1B−logesim(qi,pi+)/τ+esim(qi,pi−)/τ+∑j=1Bmask(i,j)esim(qi,pj+)/τesim(qi,pi+)/τ
在此公式中,sim(x,y) 表示向量之间的余弦相似度。掩码项 mask(i,j) 如果 qi=qj 或 pi+=pj+ 则设为 0,否则设为 1。这对于具有少量目标的分类任务特别相关。此外,模型通过多分辨率损失 (MRL) 支持多种嵌入维度。该技术跨越 k 个重叠子维度调整损失函数,使模型能够提供高达 3072 维向量,同时保持对 768 和 1536 维度的优化。
训练配方分为不同阶段以促进不同任务和模态的学习。第一阶段是预微调 (PFT),它将模型参数从自回归生成调整为编码。该阶段利用大批次大小提供稳定梯度并减轻噪声输入的影响。在 PFT 期间,训练数据由以预设比率采样的图像、文本和代码任务组成。
第二阶段是微调 (FT),它结合了更广泛的任务,包括文本、代码、文档、图像、音频和视频。其中许多任务涉及查询、目标和硬负目标三元组。作者发现为每个特定任务调整批次大小以提高评估质量是有益的。在此阶段,训练批次通过从单个任务采样示例构建,采样率根据经验定义以平衡不同模态的性能。最后,作者应用 Model Soup 技术来系统化不同检查点的组合。这涉及平均从单独微调运行中获得的参数,包括来自相同或不同训练运行的检查点,以实现额外的泛化性能。
实验
Gemini Embedding 2 在全面的多模态和单模态基准测试中进行评估,以验证其在文本、图像、视频和音频理解方面的最先进的能力。评估表明,该模型提供了一个稳健的统一潜在空间,在检索任务中优于竞争对手,同时在不需手动提示工程的情况下提供强大的零样本性能。此外,原生音频处理显著超越了基于转录的基线,并且该模型在专门领域表现出一致的泛化能力,而其他架构往往波动。
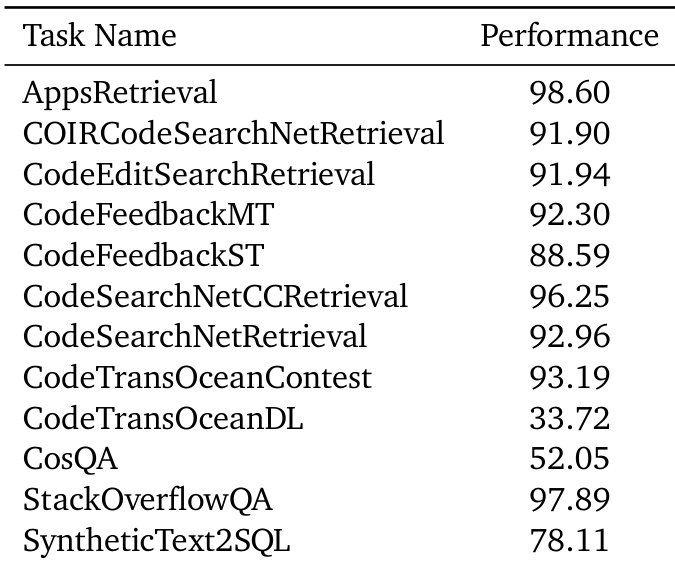
该表显示了 Gemini Embedding 2 在一系列代码检索和代码相关问答基准测试上的性能指标。该模型展示了大多数任务中的强大能力,在 AppsRetrieval 和 StackOverflowQA 等领域取得高分,而在 CodeTransOceanDL 等特定数据集上显示较低的有效性。伴随文本指出,合成数据的使用有助于 CodeFeedbackMT 和 SyntheticText2SQL 等任务的显著改进。该模型在 AppsRetrieval 和 StackOverflowQA 上达到顶级性能。在 CodeSearchNetCCRetrieval 和 CodeTransOceanContest 中观察到强劲结果。在 CodeTransOceanDL 和 CosQA 上性能相对较低。
作者通过比较标准 ASR 管道与直接原生音频处理来评估输入模态对检索性能的影响。结果表明,在所有测试的分割中,利用原始音频输入显著增强了检索能力,优于基于转录的基线。原生音频处理产生的平均检索分数高于 ASR 基线。性能改进在语言内和跨语言检索任务中均保持一致。直接音频编码的优势在跨语言检索中比在语言内检索中明显更大。

作者使用代码检索基准测试调查合成数据对 Gemini Embedding 2 性能的影响。评估显示,使用合成数据训练的模型变体在所有特定任务上显著优于基础模型和无合成数据版本。这种方法导致总体平均分数大幅增加,证实了使用合成数据改进代码理解的有效性。使用合成数据训练的模型变体在所有评估的基准测试中达到最高分数。性能改进在 CodeFeedbackMT 和 SyntheticText2SQL 等不同的代码检索任务中保持一致。与之前的模型版本相比,利用合成数据导致总体平均性能显著提升。

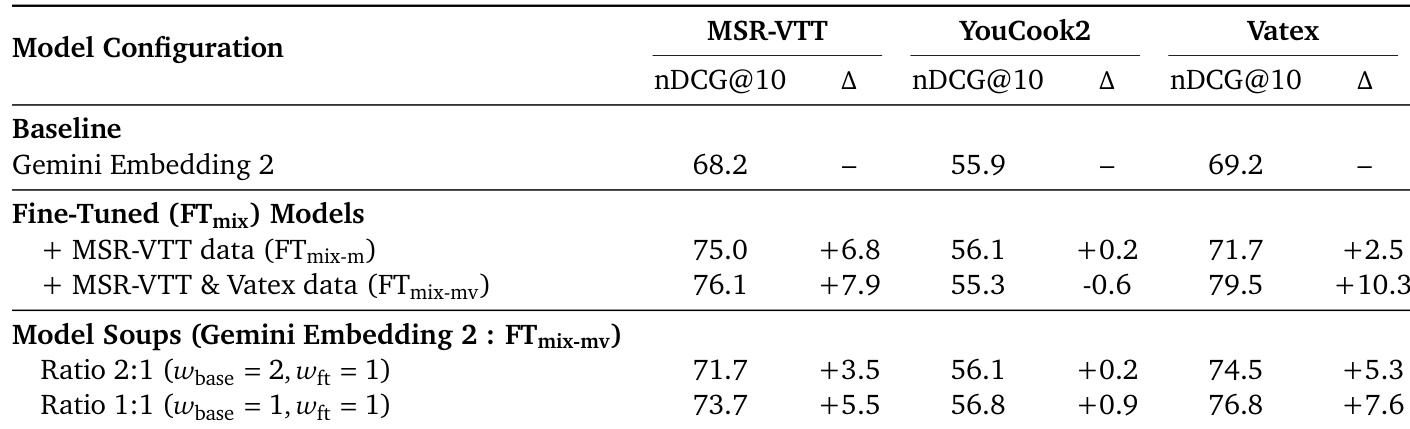
作者评估了在特定视频数据集上微调 Gemini Embedding 2 以及使用模型汤优化性能的效果。在目标数据上微调显著改善了这些特定基准测试的结果,但可能会略微降低域外任务的性能。模型汤有效地缓解了这种权衡,恢复了域外数据集的性能,同时保留了微调的好处。在特定视频数据集上微调在域内基准测试上产生显著性能增益。针对性微调导致域外数据集上的性能略有下降。模型汤平衡了权衡,在保持域内改进的同时恢复域外性能。
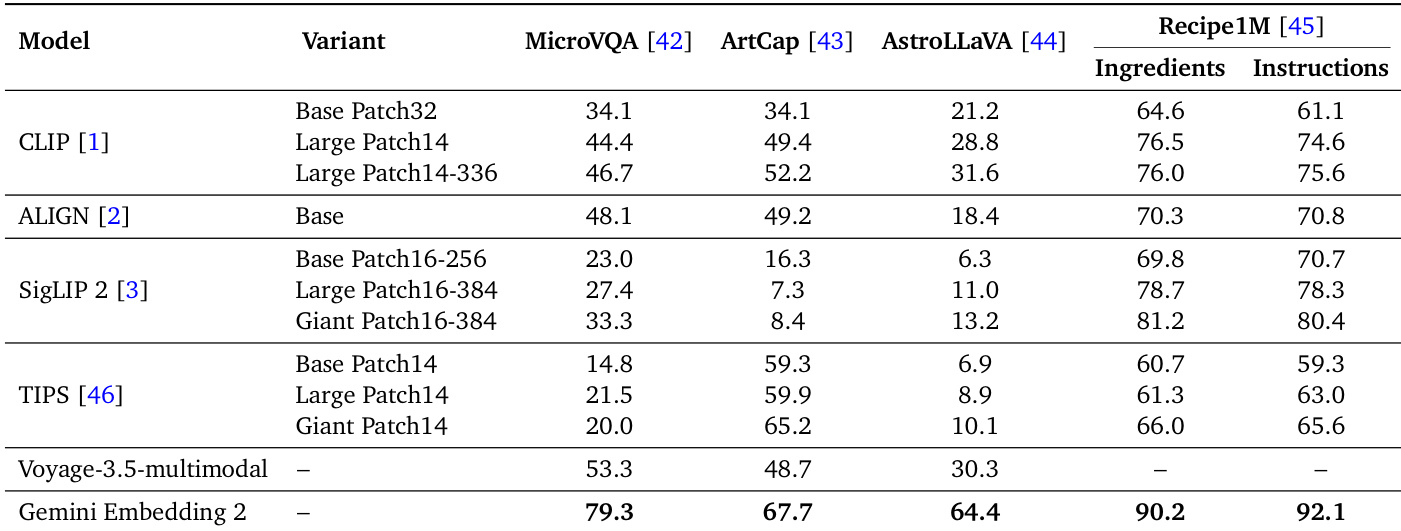
作者评估了 Gemini Embedding 2 与各种基线模型在专门领域(包括显微术、美术、天文学和烹饪艺术)的表现。结果表明,Gemini Embedding 2 在所有类别中始终达到顶级性能,而竞争模型则根据特定领域显示出显著差异。Gemini Embedding 2 展示了卓越的泛化能力,在其他模型波动显著的不同领域保持高性能。竞争模型表现出领域特定的优势和劣势,例如 TIPS 在艺术方面表现良好但在显微术方面表现不佳,而 SigLIP 2 在烹饪任务中表现出色但在艺术方面挣扎。该模型在 Recipe1M 数据集中实现了最强的检索能力,显著超过了最接近的竞争对手。
该评估在代码检索、音频模态和专门领域评估 Gemini Embedding 2,以验证各种优化策略。发现表明,原生音频处理优于转录基线,合成数据显著提升了代码理解,而模型汤有效地平衡了域内微调的好处与域外稳定性。此外,该模型在显微术和烹饪艺术等不同领域表现出卓越的泛化能力,在竞争模型波动显著的地方保持一致的顶级性能。