Command Palette
Search for a command to run...
Lens:重新思考基础文本到图像模型的训练效率
Lens:重新思考基础文本到图像模型的训练效率
摘要
我们介绍了 Lens,这是一个拥有 3.8B 参数的文本到图像(T2I)模型。在各种基准测试中,其性能与超过 6B 参数的最先进模型相当,甚至在某些情况下超越这些模型,同时所需的训练计算量显著减少。例如,Lens 仅使用 Z-Image 约 19.3% 的训练计算量。Lens 的训练效率源于其紧凑模型规模之外的两项关键策略。首先,我们通过以下方式最大化每个训练批次的数据信息密度:(i) 在 Lens-800M 上进行训练,这是一个包含 8 亿个密集标注图像-文本对的数据集,其标注由 GPT-4.1 生成,平均包含约 109 个单词,相比传统的短标注提供了更丰富的语义监督;(ii) 构建由具有多种分辨率和不同宽高比的图像组成的每个批次,从而扩大每个优化步骤的有效视觉覆盖范围。其次,我们通过谨慎的架构选择来提高收敛速度,包括采用提供更好潜在表示的语义 VAE,以及使用强大的语言编码器,后者在加速优化的同时,使得仅使用英语训练数据也能实现多语言泛化。预训练后,我们应用基于分类学驱动的提示(Lens-RL-8K)和结构化奖励标准的强化学习(RL)以抑制伪影并提高视觉质量,采用无需训练的提示搜索推理器模块以更好地将用户请求与模型对齐,并基于蒸馏的加速技术实现 4 步推理。通过高效的训练和系统优化,Lens 能够泛化到 1:2 至 2:1 的任意宽高比以及高达 1440^2 的分辨率,并支持多种常用语言的提示。得益于其紧凑的规模,Lens 在单个 NVIDIA H100 GPU 上生成 1024^2 分辨率的图像仅需 3.15 秒,而其蒸馏后的 turbo 版本仅需 0.84 秒即可完成 4 步生成。
一句话总结
Lens 是一款参数量为 3.8B 的文生图模型,在仅消耗 Z-Image 19.3% 训练算力的情况下,性能持平或超越参数量超过 6B 的模型。该模型通过 Lens-800M 数据集(包含由 GPT-4.1 生成的长文本描述)与多分辨率批处理策略最大化批次信息密度,借助语义 VAE 与稳健的语言编码器加速收敛,并支持在 1:2 至 2:1 宽高比下生成最高 1440² 分辨率的多语言图像。
核心贡献
- Lens 是一款参数量为 3.8B 的文生图模型,仅需 Z-Image 19.3% 的训练算力,即可提供与参数量超过 6B 的先进模型持平或更优的性能。
- 训练效率的提升得益于语义 VAE 与强语言编码器的结合,并辅以 Lens-800M 数据集。该数据集包含 8 亿对由 GPT-4.1 生成的密集标注图文对,每段描述平均包含 109 个单词。多分辨率批处理策略通过引入多样的宽高比与分辨率,进一步提升了单次优化步骤的信息密度。
- 后训练优化采用基于分类体系的强化学习与结构化奖励标准,以抑制视觉伪影,并利用免训练的推理模块对齐用户提示词。基于蒸馏的加速技术使得在单张 NVIDIA H100 GPU 上仅需 0.84 秒即可完成 4 步图像生成。
引言
基础文生图模型已彻底改变数字内容创作,但其对海量计算资源的需求使得大规模训练在成本与环境层面均不可持续。既往研究通常通过增加参数量来解决这一问题,但这会推高训练成本、增加推理延迟,并忽视数据密度与收敛速度等关键效率瓶颈。该研究提出 Lens,一款专为训练效率优化的紧凑型 3.8B 参数 T2I 模型。团队通过控制模型规模、利用密集标注与多分辨率训练提升批次信息密度,并策略性选择 VAE 与语言编码器以加速优化收敛。该方法使 Lens 在生成质量上持平或超越更大的先进模型,同时将训练算力消耗降低逾 80%,并支持快速推理。
数据集
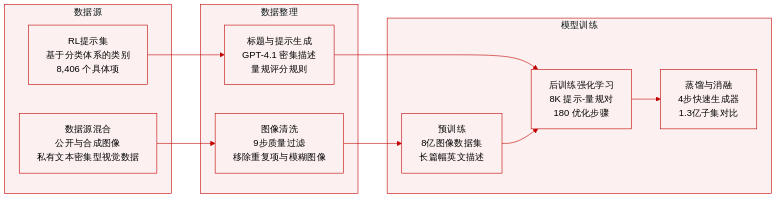
- 数据集构成与来源
- 预训练语料库由四个互补来源构建:公开真实图像、公开合成数据、私有高文本视觉内容(海报、幻灯片、平面设计及通用图像),以及在随机背景上渲染并经过模糊、色彩、字体、缩放与旋转增强的合成文本数据。
- 针对后训练阶段,研究团队开发了一套基于分类体系的提示词数据集,涵盖人类、物体、动物、场景、食物、事件、虚构世界、文本与 UI 设计等十大类别。每个大类进一步细分为精细子类别与具体项目。
- 各子集关键细节
- Lens-800M(预训练):包含约 8 亿张高质量图像。研究团队采用九步清洗流程,剔除损坏文件,过滤分辨率低于 384² 的图像,并利用专用模型排除 NSFW 内容、低美学评分样本(低于 3 分)、带水印图像、模糊或低熵样本以及曝光不当图像。通过余弦相似度阈值高于 0.985 的 CLIP 嵌入值去除近重复图像。
- Lens-RL-8K(后训练):包含 8,406 条精心筛选的提示词。每条提示词通过采样一至四个描述维度(属性、空间关系、数量、交互、颜色)并输入 GPT-4.1 生成。每条提示词均搭配最多十条特定任务评估标准及一条全局结构一致性标准。
- Lens-130M(消融实验):从 Lens-800M 中随机抽取的 1.3 亿张图像子集,用于对比不同标注策略。
- 数据使用方式
- 基础模型在 Lens-800M 上进行预训练,采用 GPT-4.1 生成的密集长文本英文描述,图像内的原始文本保留其源语言。
- 后训练阶段通过 DiffusionNFT 实施强化学习。每步采样 48 对提示词与评估标准,生成 24 张不同分辨率的图像,并使用 GPT-4.1-mini 依据标准对每张图像进行评分。策略模型在 64 张 A100 GPU 上优化 180 步。
- 最终模型采用 DMD2、解耦 DMD、SenseFlow 技术以及对抗损失的 R1 正则化方法,蒸馏为四步生成器。
- 消融实验在 Lens-130M 子集上训练较小规模的变体模型,以证明密集标注优于简短或混合标注。额外的强化学习消融实验对比完整提示词集与二分之一、四分之一及去除文本的子集,以验证场景多样性的重要性。
- 裁剪策略、元数据构建与处理细节
- 分辨率与质量过滤是主要的降采样策略,确保所有保留图像在训练前均满足最低尺寸与清晰度标准。
- 标注生成遵循严格的系统提示词,旨在产出详细且构图丰富的描述,同时保持多语言文本的准确性。
- 强化学习提示词构建依赖明确的元数据指南以确保评估可靠性。研究团队强制执行多项规则,要求主体完全可见且无遮挡、物体数量精确、色彩呈现统一以及标签与物体配对清晰。
- 奖励信号通过二元评分格式生成,视觉语言模型严格依据标准合规性输出 1 或 0,从而消除主观阐述并标准化强化学习反馈循环。
方法
Lens 模型架构旨在通过紧凑且强大的潜在扩散框架、精心挑选的语言编码器以及模块化后训练系统,实现高训练效率与卓越的生成性能。整体框架如图所示,包含三个核心组件:用于图像压缩的变分自编码器(VAE)、基于文本条件生成图像潜在特征的潜在扩散 Transformer,以及用于提示词优化的推理模块(Reasoner)。流程始于输入图像经 VAE 编码器压缩为紧凑的潜在表示,空间分辨率降低 8 倍。该潜在表示随后由扩散 Transformer 处理,在潜在空间中迭代去除图像噪声。文本提示词首先由 GPT-OSS 编码,这是一款 20B 参数的混合专家(MoE)语言模型。特征从多个层级(第 4、12、18 和 24 层)提取并拼接,形成丰富的多层语义表示。线性适配器将这些文本特征投影至与图像潜在特征相同的维度。随后,这些文本特征与每步的含噪图像潜在特征一同输入扩散 Transformer。扩散模型的核心为 MMDiT 模块,通过独立的图像与文本分支处理拼接特征,采用 RMSNorm 进行归一化并使用 RoPE 进行位置编码。48 个 MMDiT 模块堆叠构成去噪主干网络。完成最终去噪步骤后,VAE 解码器将潜在表示还原为输出图像,并通过解块操作(unpatchify)恢复原始分辨率。
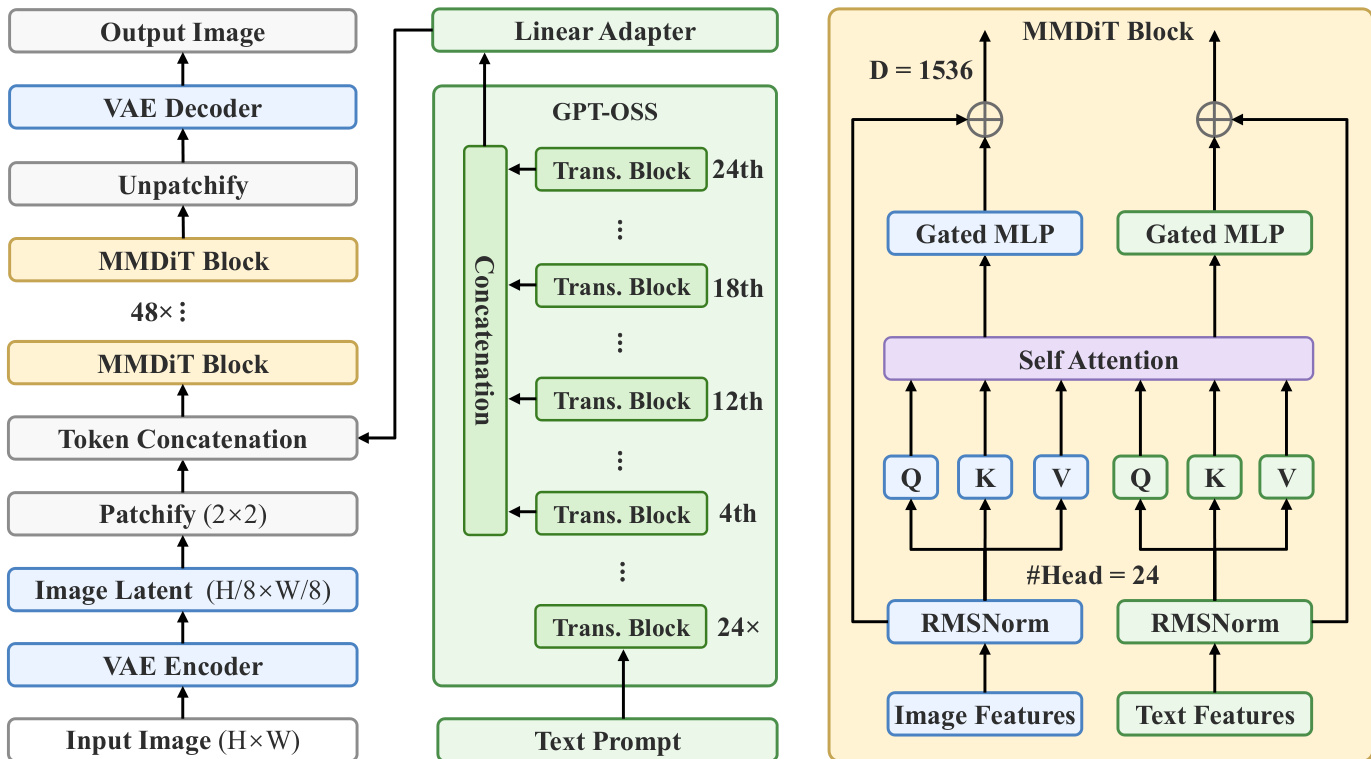 架构效率的进一步提升得益于强语义 VAE 的应用,其提供了更紧凑且富含语义的潜在空间,有助于加速收敛并改善图文对齐效果。模型还集成了推理模块,这是一个独立的语言模型,可在输入生成模型前将用户请求细化为详细连贯的提示词,从而在不重新训练核心生成器的前提下稳健处理模糊指令。该模块化设计为推理模块的选择提供了灵活性,GPT-OSS 因同时兼作文本编码器而具备成本优势。
架构效率的进一步提升得益于强语义 VAE 的应用,其提供了更紧凑且富含语义的潜在空间,有助于加速收敛并改善图文对齐效果。模型还集成了推理模块,这是一个独立的语言模型,可在输入生成模型前将用户请求细化为详细连贯的提示词,从而在不重新训练核心生成器的前提下稳健处理模糊指令。该模块化设计为推理模块的选择提供了灵活性,GPT-OSS 因同时兼作文本编码器而具备成本优势。
实验
评估在四个基准测试中将所提方法与先进基线进行对比,涵盖通用生成、构图对齐、高文本场景及复杂多区域视觉文本,并辅以不同推理模块的消融实验。定性可视化与对比结果表明,该方法持续输出高质量图像,精准渲染多语言文本,生成逼真肖像,并严格遵循复杂的多语言指令。这些发现证实,引入专用推理能力可显著提升模型在多样化文生图任务中的通用性与鲁棒性。
研究团队评估了不同强化学习训练集规模对模型在多个基准上表现的影响。结果表明,扩大训练集规模可提升 GenEval 的性能,而在 CVTG 与 OneIG (EN) 上,各项指标表现各异,文本相关分数与整体质量有所提升。强化学习训练集规模的增大有助于改善 GenEval 表现。CVTG 与 OneIG (EN) 的性能在不同指标上呈现混合趋势,部分指标在文本相关分数与整体质量上取得进展。模型性能对训练集规模较为敏感,尤其在需要精确构图对齐与文本渲染的任务中。

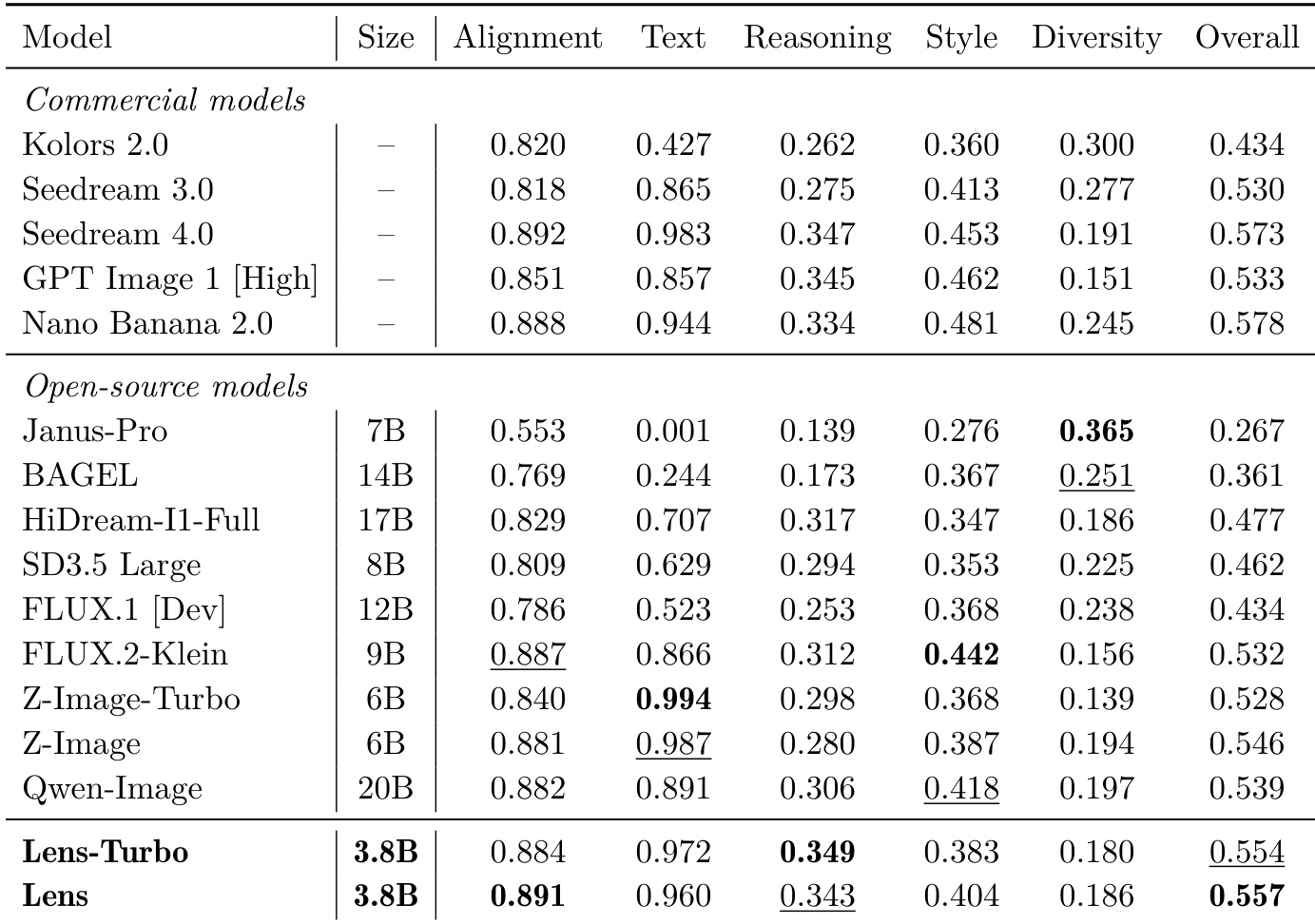
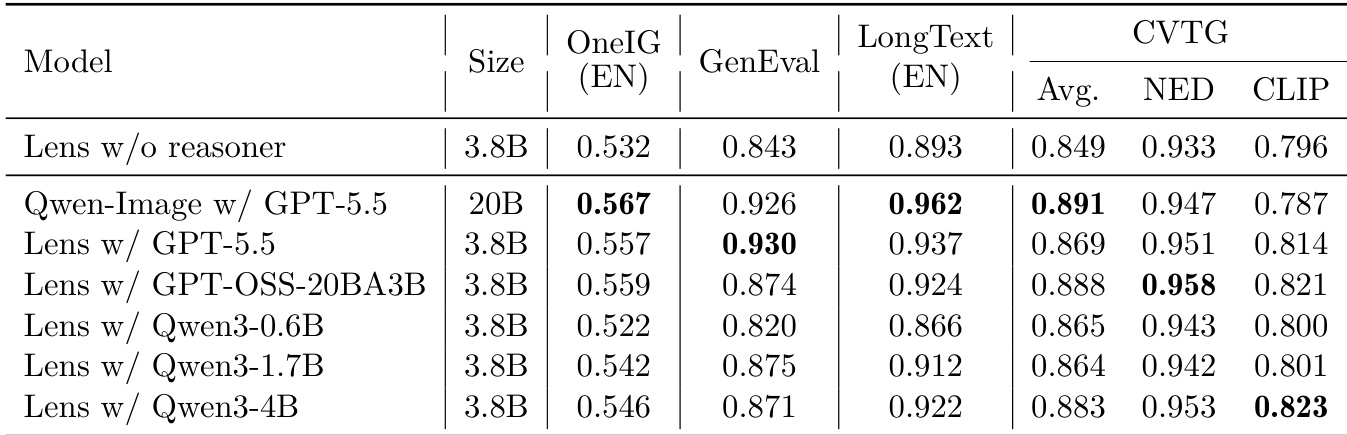
研究团队在多个基准测试中将 Lens 与 Lens-Turbo 与各类先进模型进行对比,涵盖文生图生成、构图对齐与复杂视觉文本生成。结果表明,Lens-Turbo 在文本相关任务中表现强劲,超越众多开源模型;Lens 则在对齐效果与整体质量上表现优异,排名靠前。开源模型性能差异显著,部分模型文本准确性高,但在推理与多样性方面稍显不足。
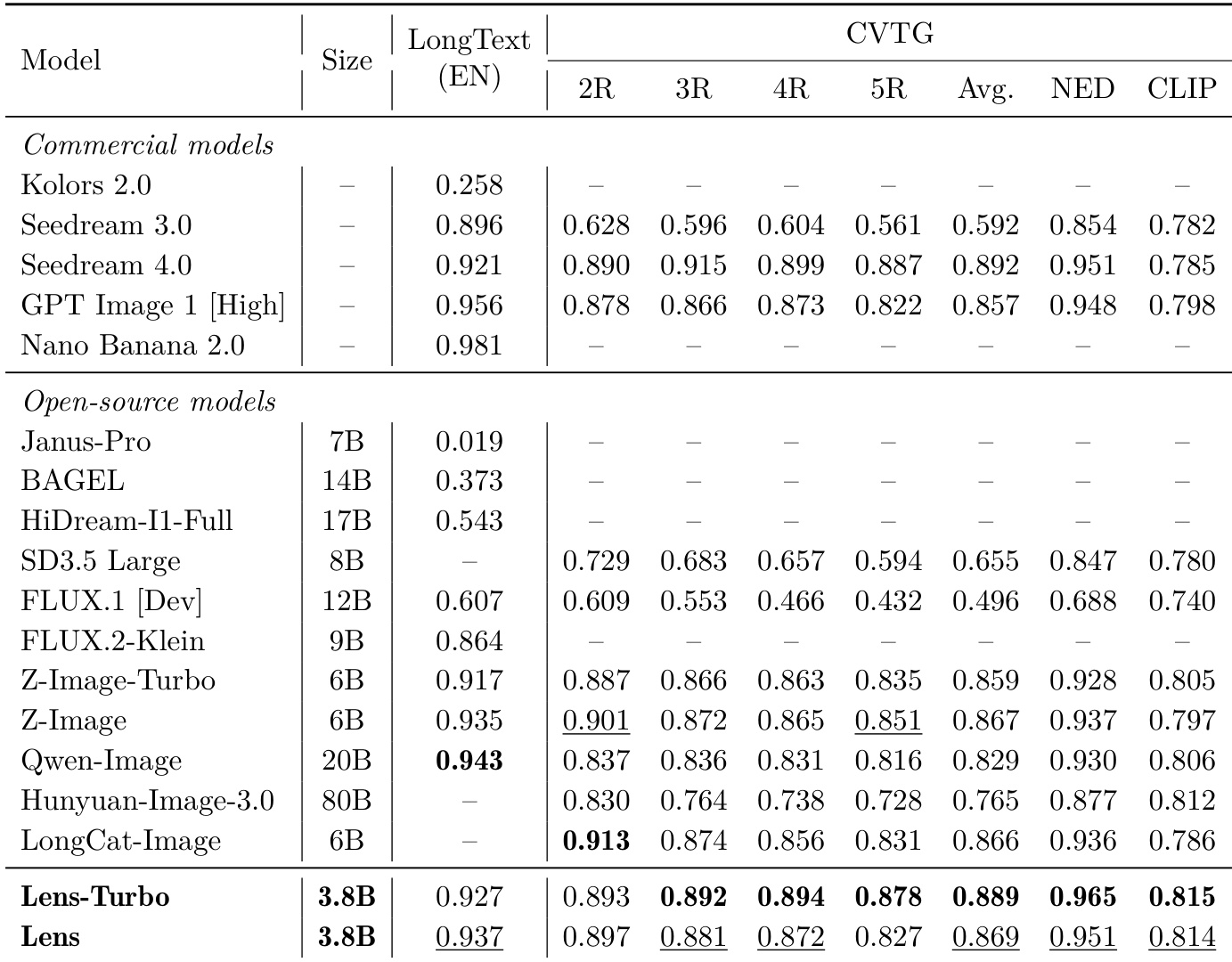
在涵盖高文本场景与复杂视觉文本生成的多项文生图基准中,研究团队对比了 Lens 与 Lens-Turbo 及各类先进模型。结果表明,两者在文本渲染与构图对齐方面具备竞争力,Lens-Turbo 常位居开源模型前列。Lens-Turbo 在高文本生成基准中表现领先。两者在包含多文本区域的复杂视觉文本生成任务中均取得优异成绩。Lens-Turbo 在特定文本对齐与渲染任务中超越多数商业模型。
研究团队在多个基准上将 Lens 与各类模型进行对比,涵盖评估主体对齐、文本准确性与构图约束的文生图任务。结果表明,Lens 的不同配置均具备竞争力,部分变体在特定基准上达到领先或接近领先的表现。在涉及文本准确性与构图对齐的任务中,Lens 变体表现优异。特定配置在部分基准上超越其他模型,展现出强大的文本渲染与视觉构图能力。引入不同推理模块会影响性能,部分变体在特定评估指标上取得提升。
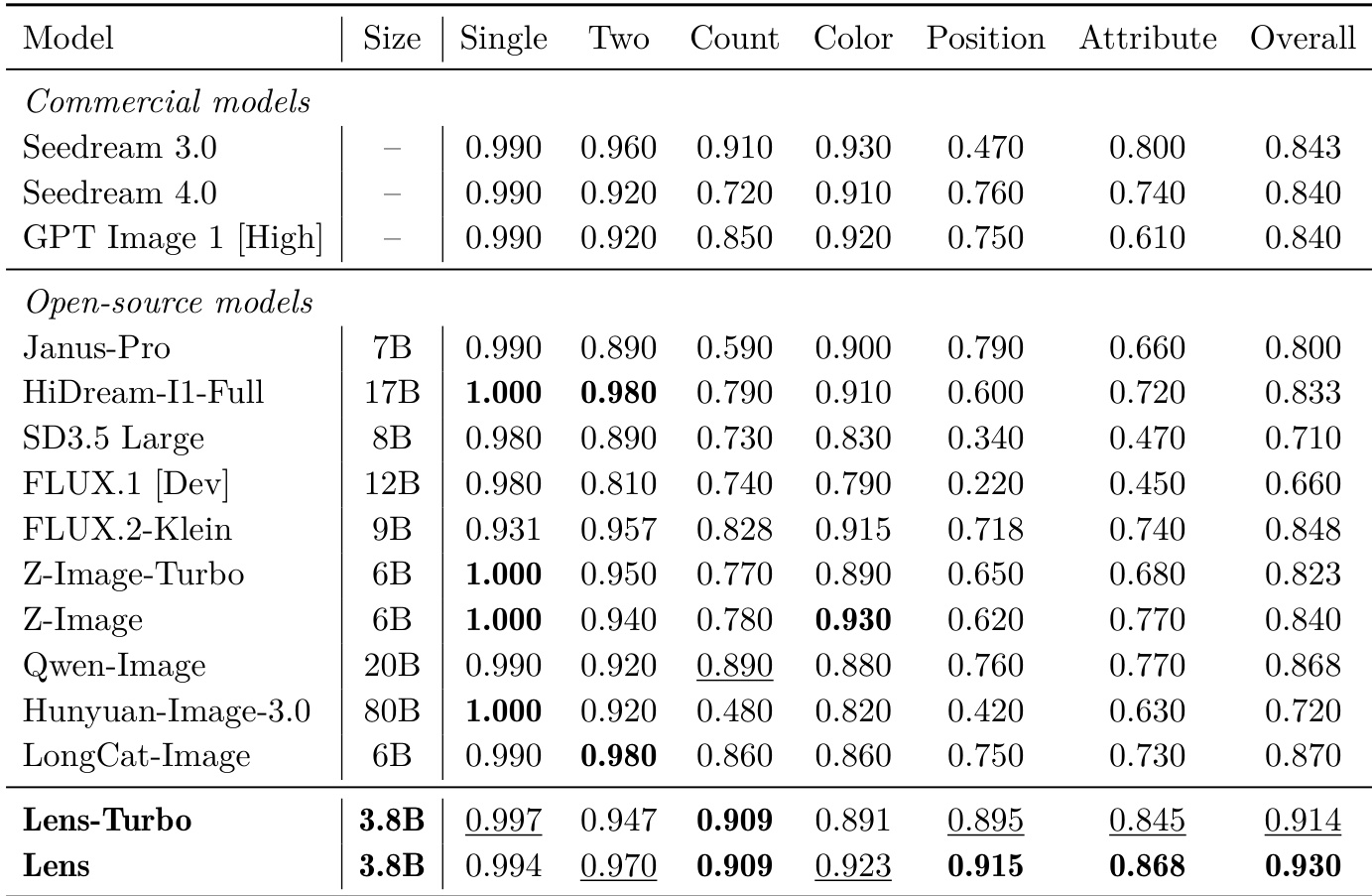
研究团队在多个基准上将 Lens 与 Lens-Turbo 与各类先进模型进行对比,涵盖以物体为中心的构图对齐、高文本场景与复杂视觉文本生成。结果表明,两者在涉及文本准确性与多物体对齐的任务中表现强劲,Lens-Turbo 在多数类别中综合得分优异。Lens-Turbo 在多项评估类别中取得高分,尤其在文本相关任务与多物体对齐方面。Lens 在整体性能及计数、属性绑定等特定任务中超越多款开源模型。Seedream 3.0 与 GPT Image 1 等商业模型在单物体生成上表现突出,但在复杂视觉文本与空间推理任务中稍逊一筹。
实验评估了强化学习训练集规模的影响,并在文生图生成、构图对齐与复杂视觉文本任务中对 Lens 与 Lens-Turbo 的性能进行基准测试。扩大训练数据规模持续改善对齐基准表现,不同模型配置在文本准确性与多物体推理方面展现出稳健能力。Lens-Turbo 在高文本生成任务中取得高度竞争力的结果,常居开源模型前列;标准 Lens 变体则在整体质量与精准的图文对齐方面表现突出。最终,两种架构在复杂渲染与空间推理任务中超越商业替代方案,验证了其有效性,并证实了其在高要求生成应用中的巨大潜力。