Command Palette
Search for a command to run...
HRM-Text: Beyond Scaling in Efficient Pretraining
HRM-Text: Beyond Scaling in Efficient Pretraining
Guan Wang Changling Liu Chenyu Wang Cai Zhou Yuhao Sun Yifei Wu Shuai Zhen Luca Scimeca Yasin Abbasi Yadkori
摘要
当前大语言模型(LLM)的预训练范式依赖于海量的计算资源和互联网规模的原始文本数据,这为基础研究设置了巨大的门槛。相比之下,生物系统通过多时间尺度的处理(例如前额叶-顶叶环的功能性组织)展示了极高的样本效率。受此启发,我们提出了 HRM-Text,该模型使用分层循环模型(Hierarchical Recurrent Model, HRM)替代了标准的 Transformer 架构,将计算解耦为演化缓慢的战略层和演化快速的执行层。为了稳定语言建模中的深层循环过程,我们引入了 MagicNorm 和深层信用分配(deep credit assignment)的预热机制。此外,摒弃了标准的原始文本预训练,我们仅使用任务完成目标(task-completion objective)和 PrefixLM 掩码,在指令-响应对上进行训练。作为一个高效预训练的经验性存在性证明(existence proof),一个仅在 400 亿唯一 token 和 1,500 美元预算上从头开始训练的 1B 参数 HRM-Text 模型,在 MMLU 上取得了 60.7% 的成绩,在 ARC-C 上取得了 81.9% 的成绩,在 DROP 上取得了 82.2% 的成绩,在 GSM8K 上取得了 84.5% 的成绩,在 MATH 上取得了 56.2% 的成绩。尽管其使用的训练 token 数量比标准基线少约 100-900 倍,估计计算量减少约 96-432 倍,但 HRM-Text 的性能可与参数量在 2B-7B 之间的开源模型相竞争。
一句话总结
HRM-Text 使用分层循环模型(Hierarchical Recurrent Model)替代标准 Transformer,将计算解耦为缓慢演化的策略层和快速演化的执行层,由 MagicNorm 和预热深度信用分配(warmup deep credit assignment)稳定,仅利用指令 - 响应对,采用任务完成目标(task-completion objective)和 PrefixLM 掩码,使一个从零训练的 1B 参数模型(在 400 亿 unique tokens 上训练,预算为 $1,500)在 MMLU 上达到 60.7%,ARC-C 上 81.9%,DROP 上 82.2%,GSM8K 上 84.5%,MATH 上 56.2%,同时在采用大约 100-900 倍更少的训练 tokens 和 96-432 倍更少的估算算力的情况下,与 2-7B 参数开源模型竞争表现。
核心贡献
- HRM-Text 使用分层循环模型替代标准 Transformer,将计算解耦为缓慢演化的策略层和快速演化的执行层。
- 该方法利用 MagicNorm 和预热深度信用分配(warmup deep credit assignment)稳定深度循环,同时仅通过任务完成目标和 PrefixLM 掩码在指令 - 响应对上进行训练。
- 一个在 400 亿 unique tokens 上从零训练的 1B 参数 HRM-Text 模型在包括 MMLU 和 GSM8K 在内的基准测试中实现了竞争性性能,其训练 tokens 数量比标准基线少约 100 到 900 倍,计算量少 96 到 432 倍。
引言
当前大语言模型预训练依赖巨大的计算量和互联网规模的原始文本,形成了限制基础研究仅由资源丰富机构进行的壁垒。这种暴力扩展范式在数据受限的情况下效率低下,且先前的循环架构往往遭受严重的梯度不稳定性。为了克服这些挑战,作者引入了 HRM-Text,用受生物多时间尺度处理启发的分层循环模型替代标准 Transformer。它们通过 MagicNorm 和预热深度信用分配(warmup deep credit assignment)等技术稳定深度循环,同时仅使用任务完成目标在指令 - 响应对上进行训练。这种协同设计使 1B 参数模型能够使用多达 900 倍更少的训练 tokens 和显著更少的计算量,实现与 2 到 7B 基线相当的竞争性性能。
数据集

- 作者在开源数据集上训练 HRM-Text,包括通用指令、重写知识、数学任务、教科书练习和网络提取问题。初始语料库包含 593.7M 文档中的 176.5B tokens。
- 他们采样 40B unique tokens,总训练时长为 60B tokens。分层采样将每个数据集视为独立层,并限制文档数量以防止大型来源过度代表。
- 特定的采样限制和乘数确保训练混合平衡,同时较小的数据集根据分层计划进行上采样。
- 作者添加条件标签以控制输出格式,包括直接、思维链、合成和噪声风格。... 边界内的文本被剥离以消除显式推理痕迹。
方法
HRM-Text 模型建立在改进的 HRM 架构之上,具有双时间尺度循环。前向传播以源自输入 token embeddings 的高级状态 zH0 初始化,以及固定低级状态 zL0。核心处理序列由两个高级循环组成。每个循环执行三次快速 L 模块更新,随后进行一次慢速 H 模块更新。Token logits 通过对最终 H 模块状态输出应用线性头来生成。
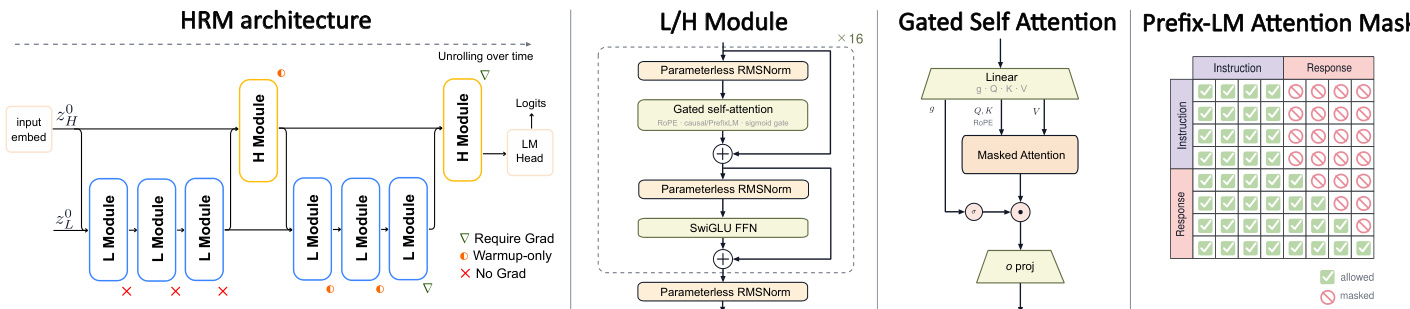
内部,H 和 L 循环模块均使用 MagicNorm 构建以解决梯度不稳定性。该设计利用了截断时间反向传播引起的正向和反向计算视界之间的不对称性。每个循环模块由 L 个内部 PreNorm 块组成,但在其出口处配有最终归一化层。在前向传播期间,循环状态 z 在每一步循环结束时接受模块级归一化操作,限制激活方差。相反,在反向传播期间,截断的梯度视界意味着误差信号通过模块级归一化的次数少于内部 PreNorm 恒等连接的次数。此外,模块使用无参数 RMSNorm、SwiGLU 激活函数、旋转位置编码(Rotary Position Embeddings)和 sigmoid 门控自注意力机制。该注意力机制使用线性投影处理查询、键和值向量,随后是一个掩码注意力块,其中 sigmoid 门在最终投影之前调节输出。
该模型优化任务完成目标,而非基于原始文本的标准自回归预训练。它直接使用指令 - 响应对从零预训练,仅在响应上计算负对数似然损失。该目标自然与 PrefixLM 注意力掩码配对,允许指令 tokens 上的完全双向注意力,同时在响应序列上保持标准因果掩码。为了确保优化期间的稳定性,作者采用预热深度信用分配策略。梯度最初仅通过最后两个循环步骤反向传播,随着训练进展扩展到最后五个步骤。这种渐进式加深使模型能够利用更长的循环计算,同时减少初始化时对优化病理的暴露。
实验
实验在匹配的训练计算量下评估 HRM 架构与标准和循环基线,以验证架构效率和特定训练目标的影响。结果表明,结合任务完成目标的循环设计显著提高了基准测试收益,使 HRM 能够使用显著更少的训练计算量与更大的模型竞争。定性分析证实这些增益源于更大的有效深度和稳定的梯度动态,而非数据污染或训练不稳定性。
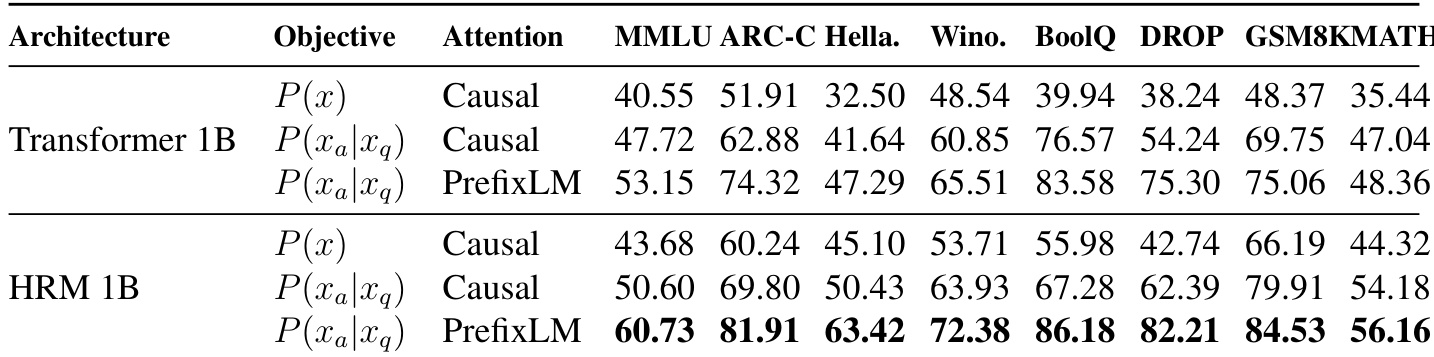
作者通过比较标准 Transformer 与 HRM 来调查训练目标和注意力机制如何影响模型性能。数据表明,转向任务完成目标并利用 PrefixLM 注意力一致地改善了两种架构的结果。此外,HRM 架构表现出优于标准 Transformer 的能力,当与任务完成目标和 PrefixLM 注意力结合时达到峰值性能。HRM 1B 在所有测试配置中始终优于 Transformer 1B 基线。任务完成目标为两种模型类型带来了显著优于标准目标的性能增益。切换到 PrefixLM 注意力进一步增强了结果,与 HRM 架构配对时产生最高分数。
作者将提出的 HRM 架构与称为 TRM 的变体在不同参数规模下进行比较,以评估稳定性和计算效率。结果表明,HRM 在 TRM 变得不稳定且表现不佳的较大规模下保持稳定的训练动态,而在较小规模下,HRM 以显著更低的计算成本实现竞争性基准性能。HRM 在所有规模下保持稳定的训练动态,而 TRM 变体在较大参数规模下遭受严重不稳定。在较小规模下,HRM 在大多数基准测试中实现竞争性性能,同时需要比 TRM 显著更少的计算量。HRM 在较大参数规模下表现出对不稳定 TRM 变体的一致性能增益。

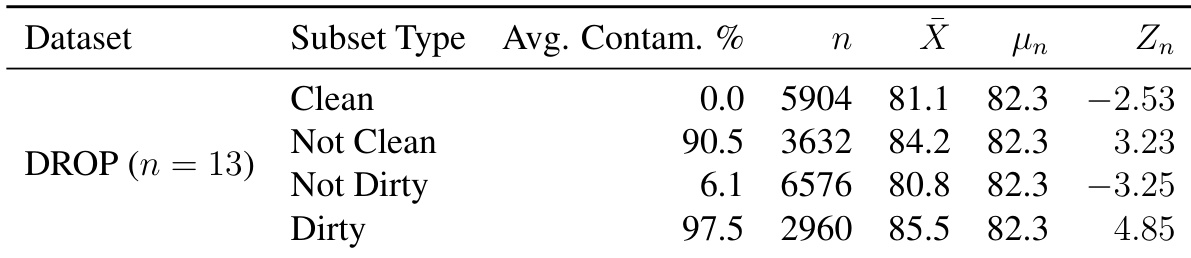
该表呈现了 DROP 基准测试上数据污染统计分析,根据污染程度将样本分类为子集。结果表明,污染百分比较高的子集往往比污染较低的子集实现更高的平均性能分数。尽管存在这些趋势,模型在严格清洁的子集上表现出稳健的性能,表明其能力并非仅由数据重叠驱动。污染程度最高的子集实现了最高的平均性能。统计测试值对于污染组为正,对于更清洁的组为负。在未检测到污染的子集上保持了强性能。
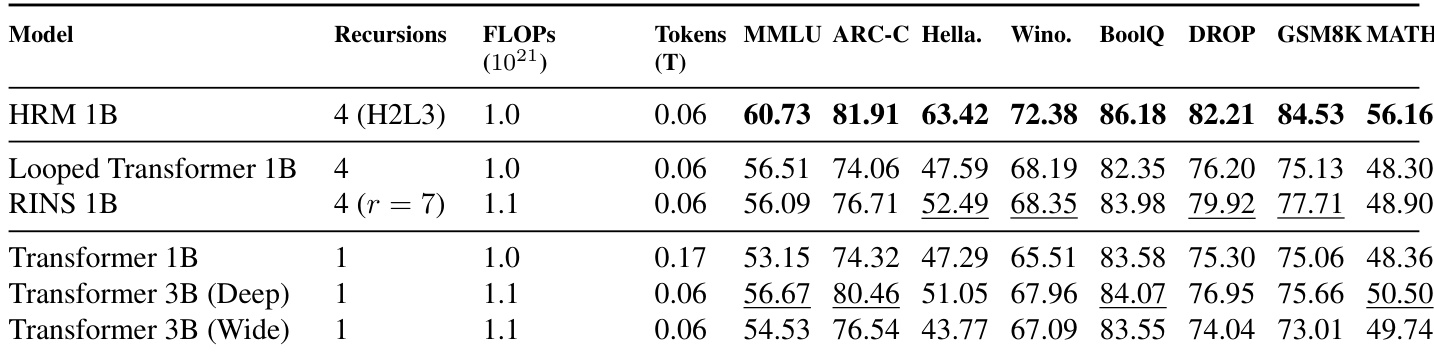
作者通过比较 HRM 与标准 Transformer、Looped Transformers 和 RINS 在匹配的训练计算预算下评估架构效率。结果表明,与具有相似计算成本的标准和其他循环架构相比,HRM 在大多数基准测试中实现了更优越的性能。值得注意的是,HRM 模型优于更大的标准 Transformer 模型和其他循环基线。HRM 在几乎所有评估的基准测试中实现了比基线最高的分数。循环架构通常优于相同参数大小的标准 Transformer,HRM 显示出最强的增益。提出的模型在与具有匹配 FLOPs 的更大标准 Transformer 模型比较时仍保持性能优势。
作者调查了一种推理时自动引导机制,该机制插值或外推来自各种递归深度的 logits 以改善模型性能。结果显示,与标准推理相比,应用此引导在所有评估的基准测试中一致产生轻微的性能增益。最佳引导参数取决于具体任务,表明不同问题受益于不同的有效循环深度。引导一致地提高了 MMLU、ARC-C 和其他基准测试的分数。该方法利用中间隐藏状态而不产生额外的计算开销。最佳引导权重因任务而异,范围从插值到外推。

该研究通过变化训练目标、注意力机制和参数规模,评估 HRM 架构与标准 Transformer 和循环基线。结果表明,HRM 确保稳定的训练动态和优越的性能,特别是当与任务完成目标和 PrefixLM 注意力结合时。此外,模型表现出对数据污染的鲁棒性,并保持对更大基线的效率优势,而推理时自动引导机制在不增加开销的情况下提高了准确性。